

import dataclasses import torch import torch.nn as nn import torch.nn.functional as F from torch import Tensor @dataclasses.dataclass class LlamaConfig: “”“Define Llama model hyperparameters.”“” vocab_size: int = 50000 # Size of the tokenizer vocabulary max_position_embeddings: int = 2048 # Maximum sequence length hidden_size: int = 768 # Dimension of hidden layers intermediate_size: int = 4*768 # Dimension of MLP’s hidden layer num_hidden_layers: int = 12 # Number of transformer layers num_attention_heads: int = 12 # Number of attention heads num_key_value_heads: int = 3 # Number of key-value heads for GQA def rotate_half(x: Tensor) -> Tensor: “”“Rotates half the hidden dims of the input. This is a helper function for rotary position embeddings (RoPE). For a tensor of shape (…, d), it returns a tensor where the last d/2 dimensions are rotated by swapping and negating. Args: x: Input tensor of shape (…, d) Returns: Tensor of same shape with rotated last dimension ““” x1, x2 = x.chunk(2, dim=–1) return torch.cat((–x2, x1), dim=–1) # Concatenate with rotation class RotaryPositionEncoding(nn.Module): “”“Rotary position encoding.”“” def __init__(self, dim: int, max_position_embeddings: int) -> None: “”“Initialize the RotaryPositionEncoding module Args: dim: The hidden dimension of the input tensor to which RoPE is applied max_position_embeddings: The maximum sequence length of the input tensor ““” super().__init__() self.dim = dim self.max_position_embeddings = max_position_embeddings # compute a matrix of n\theta_i N = 10_000.0 inv_freq = 1.0 / (N ** (torch.arange(0, dim, 2).float() / dim)) inv_freq = torch.cat((inv_freq, inv_freq), dim=–1) position = torch.arange(max_position_embeddings).float() sinusoid_inp = torch.outer(position, inv_freq) # save cosine and sine matrices as buffers, not parameters self.register_buffer(“cos”, sinusoid_inp.cos()) self.register_buffer(“sin”, sinusoid_inp.sin()) def forward(self, x: Tensor) -> Tensor: “”“Apply RoPE to tensor x Args: x: Input tensor of shape (batch_size, seq_length, num_heads, head_dim) Returns: Output tensor of shape (batch_size, seq_length, num_heads, head_dim) ““” batch_size, seq_len, num_heads, head_dim = x.shape dtype = x.dtype # transform the cosine and sine matrices to 4D tensor and the same dtype as x cos = self.cos.to(dtype)[:seq_len].view(1, seq_len, 1, –1) sin = self.sin.to(dtype)[:seq_len].view(1, seq_len, 1, –1) # apply RoPE to x output = (x * cos) + (rotate_half(x) * sin) return output class LlamaAttention(nn.Module): “”“Grouped-query attention with rotary embeddings.”“” def __init__(self, config: LlamaConfig) -> None: super().__init__() self.hidden_size = config.hidden_size self.num_heads = config.num_attention_heads self.head_dim = self.hidden_size // self.num_heads self.num_kv_heads = config.num_key_value_heads # GQA: H_kv < H_q # hidden_size must be divisible by num_heads assert (self.head_dim * self.num_heads) == self.hidden_size # Linear layers for Q, K, V projections self.q_proj = nn.Linear(self.hidden_size, self.num_heads * self.head_dim, bias=False) self.k_proj = nn.Linear(self.hidden_size, self.num_kv_heads * self.head_dim, bias=False) self.v_proj = nn.Linear(self.hidden_size, self.num_kv_heads * self.head_dim, bias=False) self.o_proj = nn.Linear(self.num_heads * self.head_dim, self.hidden_size, bias=False) def forward(self, hidden_states: Tensor, rope: RotaryPositionEncoding, attn_mask: Tensor) -> Tensor: bs, seq_len, dim = hidden_states.size() # Project inputs to Q, K, V query_states = self.q_proj(hidden_states).view(bs, seq_len, self.num_heads, self.head_dim) key_states = self.k_proj(hidden_states).view(bs, seq_len, self.num_kv_heads, self.head_dim) value_states = self.v_proj(hidden_states).view(bs, seq_len, self.num_kv_heads, self.head_dim) # Apply rotary position embeddings query_states = rope(query_states) key_states = rope(key_states) # Transpose tensors from BSHD to BHSD dimension for scaled_dot_product_attention query_states = query_states.transpose(1, 2) key_states = key_states.transpose(1, 2) value_states = value_states.transpose(1, 2) # Use PyTorch’s optimized attention implementation # setting is_causal=True is incompatible with setting explicit attention mask attn_output = F.scaled_dot_product_attention( query_states, key_states, value_states, attn_mask=attn_mask, dropout_p=0.0, enable_gqa=True, ) # Transpose output tensor from BHSD to BSHD dimension, reshape to 3D, and then project output attn_output = attn_output.transpose(1, 2).reshape(bs, seq_len, self.hidden_size) attn_output = self.o_proj(attn_output) return attn_output class LlamaMLP(nn.Module): “”“Feed-forward network with SwiGLU activation.”“” def __init__(self, config: LlamaConfig) -> None: super().__init__() # Two parallel projections for SwiGLU self.gate_proj = nn.Linear(config.hidden_size, config.intermediate_size, bias=False) self.up_proj = nn.Linear(config.hidden_size, config.intermediate_size, bias=False) self.act_fn = F.silu # SwiGLU activation function # Project back to hidden size self.down_proj = nn.Linear(config.intermediate_size, config.hidden_size, bias=False) def forward(self, x: Tensor) -> Tensor: # SwiGLU activation: multiply gate and up-projected inputs gate = self.act_fn(self.gate_proj(x)) up = self.up_proj(x) return self.down_proj(gate * up) class LlamaDecoderLayer(nn.Module): “”“Single transformer layer for a Llama model.”“” def __init__(self, config: LlamaConfig) -> None: super().__init__() self.input_layernorm = nn.RMSNorm(config.hidden_size, eps=1e–5) self.self_attn = LlamaAttention(config) self.post_attention_layernorm = nn.RMSNorm(config.hidden_size, eps=1e–5) self.mlp = LlamaMLP(config) def forward(self, hidden_states: Tensor, rope: RotaryPositionEncoding, attn_mask: Tensor) -> Tensor: # First residual block: Self-attention residual = hidden_states hidden_states = self.input_layernorm(hidden_states) attn_outputs = self.self_attn(hidden_states, rope=rope, attn_mask=attn_mask) hidden_states = attn_outputs + residual # Second residual block: MLP residual = hidden_states hidden_states = self.post_attention_layernorm(hidden_states) hidden_states = self.mlp(hidden_states) + residual return hidden_states class LlamaModel(nn.Module): “”“The full Llama model without any pretraining heads.”“” def __init__(self, config: LlamaConfig) -> None: super().__init__() self.rotary_emb = RotaryPositionEncoding( config.hidden_size // config.num_attention_heads, config.max_position_embeddings, ) self.embed_tokens = nn.Embedding(config.vocab_size, config.hidden_size) self.layers = nn.ModuleList([LlamaDecoderLayer(config) for _ in range(config.num_hidden_layers)]) self.norm = nn.RMSNorm(config.hidden_size, eps=1e–5) def forward(self, input_ids: Tensor, attn_mask: Tensor) -> Tensor: # Convert input token IDs to embeddings hidden_states = self.embed_tokens(input_ids) # Process through all transformer layers, then the final norm layer for layer in self.layers: hidden_states = layer(hidden_states, rope=self.rotary_emb, attn_mask=attn_mask) hidden_states = self.norm(hidden_states) # Return the final hidden states return hidden_states class LlamaForPretraining(nn.Module): def __init__(self, config: LlamaConfig) -> None: super().__init__() self.base_model = LlamaModel(config) self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False) def forward(self, input_ids: Tensor, attn_mask: Tensor) -> Tensor: hidden_states = self.base_model(input_ids, attn_mask) return self.lm_head(hidden_states) def create_causal_mask(seq_len: int, device: torch.device, dtype: torch.dtype = torch.float32) -> Tensor: “”“Create a causal mask for self-attention. Args: seq_len: Length of the sequence device: Device to create the mask on dtype: Data type of the mask Returns: Causal mask of shape (seq_len, seq_len) ““” mask = torch.full((seq_len, seq_len), float(‘-inf’), device=device, dtype=dtype) \ .triu(diagonal=1) return mask def create_padding_mask(batch, padding_token_id, device: torch.device, dtype: torch.dtype = torch.float32): “”“Create a padding mask for a batch of sequences for self-attention. Args: batch: Batch of sequences, shape (batch_size, seq_len) padding_token_id: ID of the padding token Returns: Padding mask of shape (batch_size, 1, seq_len, seq_len) ““” padded = torch.zeros_like(batch, device=device, dtype=dtype) \ .masked_fill(batch == padding_token_id, float(‘-inf’)) mask = padded[:,:,None] + padded[:,None,:] return mask[:, None, :, :] # Create model with default config test_config = LlamaConfig() device = torch.device(“cuda”) if torch.cuda.is_available() else torch.device(“cpu”)

Apple Upbeat On India Expansion, Opens Retail Store In Noida, 5th In Country | Technology News
Noida: US tech giant Apple on Wednesday previewed Apple Noida, its first retail store here and fifth in the country so far. Located in DLF Mall of India, the new store brings together Apple’s full lineup of products and services. The new retail store in Noida is part of Apple’s retail expansion that began in 2023 with Apple BKC in Mumbai and Apple Saket in Delhi, followed by Apple Hebbal in Bengaluru and Apple Koregaon Park in Pune in September 2025. Apple Noida opened on Thursday, December 11, at 1 p.m. IST, where more than 80 team members are ready to help customers shop for the latest Apple products, including the latest iPhone series, Apple Watch Ultra 3, Apple Watch Series 11 models, and the all-new iPad Pro and 14-inch MacBook Pro (powered by the M5 chip). Customers can take advantage of Apple’s retail services, including personalised setup and support, said the company. “Connection is at the heart of everything we do in Apple retail, and we’re excited to open the doors to a new store built for community and creativity with Apple Noida,” said Deirdre O’Brien, Apple’s senior vice president of Retail and People. “Our team members are thrilled to deepen our connections with customers across this vibrant city and help them experience the best of Apple.” Add Zee News as a Preferred Source In their first year, the two outlets reportedly generated nearly Rs 800 crore in combined revenue, making them among Apple’s best-performing stores worldwide. Interestingly, the smaller Saket store contributed almost 60 per cent of total sales. Like all Apple facilities, Apple Noida also runs on 100 percent renewable energy and is carbon neutral.

Vivo X300, Vivo X300 Pro Go On Sale In India; Check Camera, Battery, Display, Price, Availability, And Bank Offers | Technology News
Vivo X300 Series Price In India: Chinese smartphone brand Vivo has officially announced the start of sales for its latest flagship lineup, the Vivo X300 and Vivo X300 Pro, in India, following their launch last week. The Vivo X300 series also marks the India debut of Vivo’s Android 16-based OriginOS 6, which formally replaces FunTouchOS on new Vivo devices. The lineup additionally supports a teleconverter kit. With these new models, Vivo is positioning the X300 series as direct competitors to Oppo’s Find X9 Pro and Find X9. Vivo X300 Pro Specifications: The smartphone features a 6.78-inch 1.5K BOE Q10+ LTPO OLED display with a 120Hz refresh rate and Circular Polarisation 2.0 for better outdoor visibility. It is powered by the MediaTek Dimensity 9500 chipset, paired with 16GB LPDDR5X RAM and 512GB UFS 4.1 storage, running on Android 16 with Vivo’s latest Indian UI. Add Zee News as a Preferred Source For photography, the device sports a 50MP Sony LYT-828 main sensor, a 50MP JN1 ultrawide lens, and a 200MP periscope telephoto camera with OIS, supported by Vivo’s V3+ and Vs1 dedicated imaging chips, Zeiss colour science, and an optional 2.35x Telephoto Extender. For selfies and quality video chats, there is a 50MP JN1 shooter at the front. The phone packs a 6,510mAh battery with 90W wired and 40W wireless charging. Additional features include an ultrasonic in-display fingerprint sensor, Wi-Fi 7, Bluetooth 5.4, NFC, GPS, IP68 rating, dual speakers, an Action Button, a large X-axis linear motor, a signal amplifier chip, and four Wi-Fi boosters, all in a 226g body. Vivo X300 Specifications The smartphone is powered by the MediaTek Dimensity 9500 (3nm) chipset paired with a Pro Imaging VS1 chip and a V3+ imaging chip for enhanced camera performance. It features a 6.31-inch 1.5K (1216×2640) AMOLED display and comes equipped with a versatile camera setup, including a 200MP main sensor, a 50MP wide-angle lens, and a 50MP telephoto camera, along with a separate 50MP sensor that supports 4K video recording. (Also Read: Apple Rolls Out ‘Tap to Pay’ Feature On iPhone; How It Works And Which Platforms Offer This Service- Details) The phone is available in multiple memory configurations which includes the 12GB RAM with 256GB storage, 12GB RAM with 512GB storage, and 16GB RAM with 512GB storage. It also offers robust durability with IP68 and IP69 ratings for dust and water resistance. The handset weighs 190 grams and comes in three colour options: Elite Black, Mist Blue, and Summit Red. Vivo X300 Series Price In India And Availability The smartphone is available in three variants: 12GB+256GB, 12GB+512GB and 16GB+512GB, priced at Rs 75,999, Rs 81,999 and Rs 85,999 respectively. The Vivo X300 Pro is priced at Rs 1,09,999. Both models will be available for purchase starting December 10, 2025 through major retail partners, Flipkart, Amazon and vivo India’s official e-store. Vivo X300 Series: Bank Offers Customers can get up to 10% instant cashback through SBI, HDFC, Kotak, IDFC First Bank, Yes Bank, and other major financial institutions. Vivo is also offering no-cost EMI plans for up to 24 months, with monthly payments starting at Rs 3,167, along with zero down payment options.

ChatGPT Logs Biggest User Growth Rate Among Smartphone Apps In S. Korea | Technology News
Seoul: ChatGPT, a generative artificial intelligence (AI) platform of OpenAI, recorded the biggest rate of increase in its smartphone app users among all apps available in South Korea this year, a survey showed on Wednesday. Users of the ChatGPT app grew 196.6 percent in November compared with January, making it the app with the most significant increase, according to a sample survey of 4 million smartphone users in Korea conducted by industry tracker Wiseapp Retail, reports Yonhap news agency. Daiso Mall, the online mall of the popular discount store Daiso, ranked second with a growth rate of 31.9 percent, followed by beauty retailer Olive Young with 30.8 percent and Monino, an asset-management service app for users of Samsung Group’s financial affiliates, with 28.1 percent. Add Zee News as a Preferred Source ChatGPT was also the most-used smartphone app during the same period, logging a monthly average of 16.7 million users, followed by Kakao Pay with 9.1 million and Olive Young with 8.6 million. In October, Kakao said that ChatGPT is now available for use on the KakaoTalk online messaging app. With ChatGPT for Kakao, KakaoTalk users can access the chatbot with a single tap and share AI-generated conversations, images and text with friends in real time, according to the company. Existing ChatGPT users can use the service within KakaoTalk with their preexisting ChatGPT account This rollout marked the first major outcome of the partnership formed between Kakao and OpenAI in February as part of the Korean internet giant’s broader strategy to join a global AI alliance amid intensifying competition in the market. Earlier, the number of ChatGPT users in South Korea surpassed 20 million for the first time in August, data showed. The monthly active users (MAUs) of ChatGPT reached a monthly record of 20.31 million in August, sharply up from 4.07 million a year ago, according to the data compiled by industry tracker Wiseapp Retail.

Apple Rolls Out ‘Tap to Pay’ Feature On iPhone; How It Works And Which Platforms Offer This Service- Details | Technology News
Apple’s Tap To Pay Feature: The Cupertino-based tech giant has rolled out the Tap to Pay on iPhone feature in Hong Kong. With this Apple’s Tap to Pay feature, the thousands of merchants can accept payments through iPhones directly via the contactless method, and they don’t need any additional hardware or terminals. Hence, the merchants can accept payments from wherever they do business. Apple Tap to Pay Feature: iPhone Expands Digital Payments Merchants can now accept payments by asking customers to hold their contactless card, iPhone, Apple Watch, or any digital wallet near the merchant’s iPhone. The transaction is completed securely using NFC technology. The Adyen, Global Payments, KPay, and SoePay are the first platforms in Hong Kong to support Tap to Pay on iPhone. Add Zee News as a Preferred Source This feature helps businesses across sectors like taxis, retail, food and beverages, beauty, and professional services accept contactless payments without extra hardware. Tap to Pay on iPhone works with Apple Pay, other digital wallets, and major contactless cards, including American Express, JCB, Mastercard, UnionPay, and Visa. (Also Read: Redmi Note 15, Redmi Note 15 Pro India Launch Teased; Check Expected Camera, Battery, Display, Price And Other Features) Apple Tap to Pay Feature: How It Works Merchants using an iPhone 11 or later with the latest iOS can now accept payments through NFC. Customers just need to hold their contactless card, iPhone, Apple Watch, or digital wallet near the merchant’s iPhone to finish the payment. No extra terminals or hardware are needed, making this a convenient option for businesses of any size.

Microsoft To Invest $17.5 Bn In India To Scale Up AI, PM Modi Says… | Technology News
New Delhi: Global tech giant Microsoft announced on Tuesday that it is investing $17.5 billion in India over the next four years (2026-2029) to drive AI diffusion in the country, with Prime Minister Narendra Modi asserting that the country’s youth “will harness this opportunity to innovate and leverage the power of AI for a better planet”. “Today we are announcing our largest investment in Asia — $17.5 billion over four years (CY 2026 to 2029) — to advance India’s cloud and artificial intelligence (AI) infrastructure, skilling and ongoing operations. This investment builds on the $3 billion investment announced earlier this year, which we are on track to spend by the end of CY2026,” Microsoft said in a statement. The announcement came after Microsoft Chairman and CEO Satya Nadella’s meeting here with Prime Minister Modi. Add Zee News as a Preferred Source “Thank you, Prime Minister Narendra Modi, for an inspiring conversation on India’s AI opportunity. To support the country’s ambitions, Microsoft is committing US$17.5B—our largest investment ever in Asia—to help build the infrastructure, skills, and sovereign capabilities needed for India’s AI-first future,” Nadella said in a post on X. Responding to Nadella’s post, PM Modi wrote: “When it comes to AI, the world is optimistic about India!” “Had a very productive discussion with Mr. Satya Nadella. Happy to see India being the place where Microsoft will make its largest-ever investment in Asia. The youth of India will harness this opportunity to innovate and leverage the power of AI for a better planet,” he posted. Microsoft said that India stands at a pivotal moment in its AI journey, one defined by impact at scale, determined to lead. As technology becomes a catalyst for inclusive growth and economic transformation, the country is emerging as a frontier AI nation. Nadella has arrived in India for an AI tour of the country. In the meeting with PM Modi, both leaders discussed the country’s AI roadmap and growth priorities. Microsoft’s investment in India focuses on three pillars—scale, skills and sovereignty—aligned with the Prime Minister’s vision of building a comprehensive ecosystem that drives AI innovation and access at a national scale, according to the company statement. The new investment will be used to continue to scale up Microsoft’s cloud and AI infrastructure, skilling initiatives and ongoing operations across India. This includes the company’s workforce of more than 22,000 employees across Bengaluru, Hyderabad, Pune, Gurugram, Noida and other cities — representing the diversity of Microsoft’s businesses. They drive every part of its product cycle, from model development to engineering and product innovation. Their work contributes to innovation across Microsoft’s AI stack — from infrastructure to app platforms to products — while operating hyperscale datacenters and delivering sales and support to customers nationwide. These teams are not only powering India’s digital transformation but also delivering AI impact at scale globally —Copilot Studio, Azure AI Search, AI agents, AI speech and translation, Azure Machine Learning and more. Every day, they collaborate closely with India’s leading enterprises, developers and institutions to unlock the promise of AI for the country, according to the Microsoft statement. One of the key priorities of the Microsoft investment is building secure, sovereign-ready hyperscale infrastructure to enable AI adoption in India. At the heart of this effort is the significant progress being made at the India South Central cloud region, based in Hyderabad, that is set to go live in mid-2026. This will be our largest hyperscale region in India, comprising three availability zones — roughly equivalent in size to two Eden Gardens stadiums combined, the statement said. The company said it will also continue to expand the three existing operational data centre regions in Chennai, Hyderabad and Pune. This expansion provides organisations across India greater choice and resilience, enabling low-latency, mission-critical performance for enterprises, startups, and public sector institutions. Union Minister of Electronics & Information Technology Ashwini Vaishnaw said: “As AI reshapes the digital economy, India remains committed to innovation anchored in trust and sovereignty. Microsoft’s landmark investment signals India’s rise as a reliable technology partner for the world. This partnership will set new benchmarks and drive the country’s leap from digital public infrastructure to AI public infrastructure.” Microsoft India and South Asia President Puneet Chandok said: “Building on the $3 billion investment announced in January 2025, Microsoft’s new $17.5 billion commitment and deep partnership across India’s technology ecosystem are focused on turning India’s AI ambition into impact for every citizen. This transformation is anchored on three pillars: hyperscale infrastructure to run AI at scale, sovereign-ready solutions that ensure trust, and skilling programs that empower every Indian to not just join the future but shape it.”
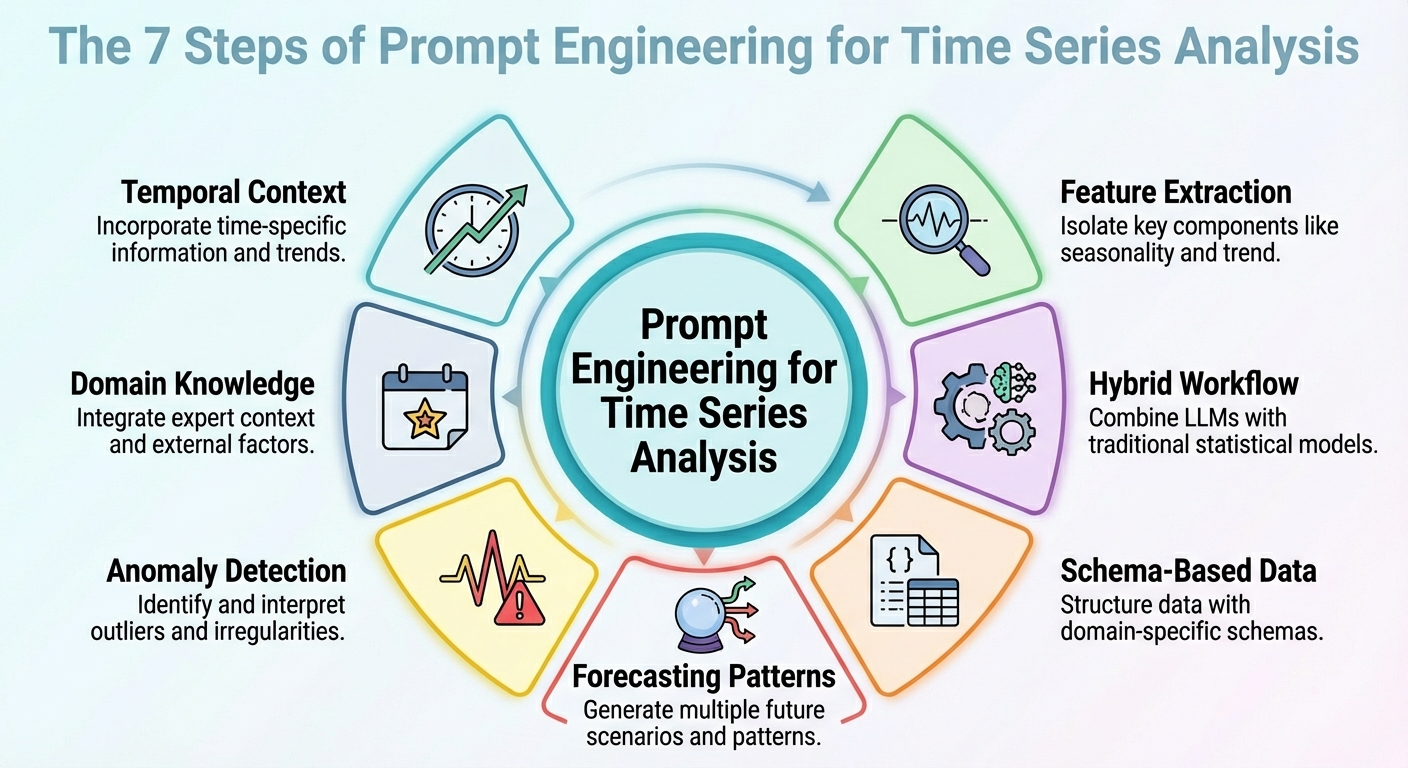
Prompt Engineering for Time Series Analysis
In this article, you will learn practical prompt-engineering patterns that make large language models useful and reliable for time series analysis and forecasting. Topics we will cover include: How to frame temporal context and extract useful signals How to combine LLM reasoning with classical statistical models How to structure data and prompts for forecasting, anomalies, and domain constraints Without further delay, let’s begin. Prompt Engineering for Time Series AnalysisImage by Editor Introduction Strange as it may sound, large language models (LLMs) can be leveraged for data analysis tasks, including specific scenarios such as time series analysis. The key is to correctly translate your prompt engineering skills into the specific analysis scenario. This article outlines seven prompt engineering strategies that can be used to leverage time series analysis tasks with LLMs. Unless said otherwise, the descriptions of these strategies are accompanied by illustrative examples revolving around a retail sales data scenario, concretely, considering a time series dataset consisting of daily sales over time for its analysis. 1. Contextualizing Temporal Structure First, an effective prompt to get a useful model output should be one that helps it understand the temporal structure of the time series dataset. This includes possible mentions of upward/downward trends, seasonality, known cycles like promotions or holidays, and so on. This context information will help your LLM interpret, for instance, temporal fluctuations as — well, just that: fluctuations, rather than noise. In sum, describing the structure of the dataset clearly in the context accompanying your prompts often goes further than intricate reasoning instructions in prompts. Example prompt:“Here is the daily sales (in units) for the last 365 days. The data shows a weekly seasonality (higher sales on weekends), a gradually increasing long-term trend, and monthly spikes at the end of each month due to pay-day promotions. Use that knowledge when forecasting the next 30 days.” 2. Feature and Signal Extraction Instead of asking your model to perform direct forecasts from raw numbers, why not prompt it to extract some key features first? This could include latent patterns, anomalies, and correlations. Asking the LLM to extract features and signals and incorporate them into the prompt (e.g., through summary statistics or decomposition) helps reveal the reasons behind future predictions or fluctuations. Example prompt:“From the past 365 days of sales data, compute the average daily sales, the standard deviation, identify any days where sales exceeded mean plus twice the standard deviation (i.e., potential outliers), and note any recurring weekly or monthly patterns. Then interpret what factors might explain high-sales days or dips, and flag any unusual anomalies.” 3. Hybrid LLM + Statistical Workflow Let’s face it: LLMs in isolation will often struggle with tasks requiring numeric precision and capturing temporal dependencies in time series. For this reason, simply combining their use with classical statistical models is a formula to yield better outcomes. How could a hybrid workflow like this be defined? The trick is to inject LLM reasoning — high-level interpretation, hypothesis formulation, and context comprehension — alongside quantitative models such as ARIMA, ETS, or others. For instance, LeMoLE (LLM-Enhanced Mixture of Linear Experts) is an example of a hybrid approach that enriches linear models with prompt-derived features. The result blends contextual reasoning and statistical rigor: the best of two worlds. 4. Schema-based Data Representation While raw time series datasets are usually poorly suited formats to pass as LLM inputs, using structured schemas like JSON or compact tables could be the key that allows the LLM to interpret these data much more reliably, as demonstrated in several studies. Example JSON snippet to be passed alongside a prompt: { “sales”: [ {“date”: “2024-12-01”, “units”: 120}, {“date”: “2024-12-02”, “units”: 135}, …, {“date”: “2025-11-30”, “units”: 210} ], “metadata”: { “frequency”: “daily”, “seasonality”: [“weekly”, “monthly_end”], “domain”: “retail_sales” } } { “sales”: [ {“date”: “2024-12-01”, “units”: 120}, {“date”: “2024-12-02”, “units”: 135}, …, {“date”: “2025-11-30”, “units”: 210} ], “metadata”: { “frequency”: “daily”, “seasonality”: [“weekly”, “monthly_end”], “domain”: “retail_sales” } } Prompt to accompany the JSON data with:“Given the above JSON data and metadata, analyze the time series and forecast the next 30 days of sales.” 5. Prompted Forecasting Patterns Designing and properly structuring forecasting patterns within the prompt — such as short-term vs. long-term horizons or simulating specific “what-if” scenarios — can help guide the model to produce more usable responses. This approach is effective for generating highly actionable insights for your requested analysis. Example: Task A — Short-term (next 7 days): Forecast expected sales. Task B — Long-term (next 30 days): Provide a baseline forecast plus two scenarios: – Scenario 1 (normal conditions) – Scenario 2 (with a planned promotion on days 10-15) In addition, provide a 95% confidence interval for both scenarios. Task A — Short–term (next 7 days): Forecast expected sales. Task B — Long–term (next 30 days): Provide a baseline forecast plus two scenarios: – Scenario 1 (normal conditions) – Scenario 2 (with a planned promotion on days 10–15) In addition, provide a 95% confidence interval for both scenarios. 6. Anomaly Detection Prompts This one is more task-specific and focuses on properly crafting prompts that may help not only forecast with LLMs but also detect anomalies — in combination with statistical methods — and reason about their likely causes, or even suggest what to investigate. The key is, once more, to first preprocess with traditional time series tools and then prompt the model for interpretation of findings. Example prompt:“Using the sales data JSON, first flag any day where sales deviate more than 2× the weekly standard deviation from the weekly mean. Then for every flagged day, explain possible causes (e.g., out-of-stock, promotion, external events) and recommend whether to investigate (e.g., check inventory logs, marketing campaign, store foot traffic).” 7. Domain-Infused Reasoning Domain knowledge like retail seasonality patterns, holiday effects, etc., uncovers valuable insights, and embedding it into prompts helps LLMs perform analyses and predictions that are more meaningful and also interpretable. This boils down to leveraging the relevance of “dataset

Top 5 Agentic AI LLM Models
In 2025, “using AI” no longer just means chatting with a model, and you’ve probably already noticed that shift yourself.

Redmi Note 15, Redmi Note 15 Pro India Launch Teased; Check Expected Camera, Battery, Display, Price And Other Features | Technology News
Redmi Note 15 Series India Launch: Xiaomi’s sub-brand Redmi is expected to launch the Redmi Note 15 series in India after introducing the lineup in China earlier this year. The series will likely include the Redmi Note 15, Redmi Note 15 Pro, and Redmi Note 15 Pro Plus, featuring notable upgrades in display, battery, performance, and camera technology. According to rumours, the company may follow a staggered rollout, starting with the standard Redmi Note 15 before launching the Note 15 Pro and Note 15 Pro Plus variants. However, Redmi has not issued any official confirmation yet. Redmi Note 15 Specifications (Expected) Add Zee News as a Preferred Source The Redmi Note 15 is expected to feature a large 6.8-inch AMOLED display with a smooth 120Hz refresh rate and is likely to be powered by a Snapdragon chipset. The smartphone may pack a 5,500mAh battery with support for 45W fast charging and could also offer an IP65 rating for dust and water resistance. On the photography front, the phone is rumoured to include a 108MP primary lens, an 8MP ultrawide sensor, and a 20MP front camera, all while maintaining a lightweight build of around 170 grams. On the software front, the Redmi Note 15 is expected to run Xiaomi’s HyperOS right out of the box. Redmi Note 15 Pro Models Specifications (Expected) The Redmi Note 15 Pro and Note 15 Pro Plus are expected to feature a slightly larger 6.83-inch AMOLED display with a 120Hz refresh rate. The Pro Plus model is rumoured to come with the Snapdragon 7s Gen 4 chipset, while the Pro variant may use the Dimensity 7400 Ultra processor. Both smartphones are likely to offer Gorilla Glass Victus 2 protection and a stronger IP68 rating. For cameras, they may include a 200MP main sensor paired with an 8MP ultrawide lens, and the Pro Plus could also pack a larger 6,500mAh battery. (Also Read: iPhone 17 Series, iPhone 16, And MacBook Pro Models Get Huge Discount In Apple Holiday Season Sale- Details Here) Redmi Note 15 Series India Launch And Price (Expected) The Redmi Note 15 is expected to be priced around Rs 20,000, while the Redmi Note 15 Pro may fall in the Rs 27,000–Rs 30,000 range. The Redmi Note 15 Pro Plus is likely to be the most expensive in the lineup, priced at around Rs 35,000. The Redmi Note 15 series is expected to make India debut on January 6, 2026.
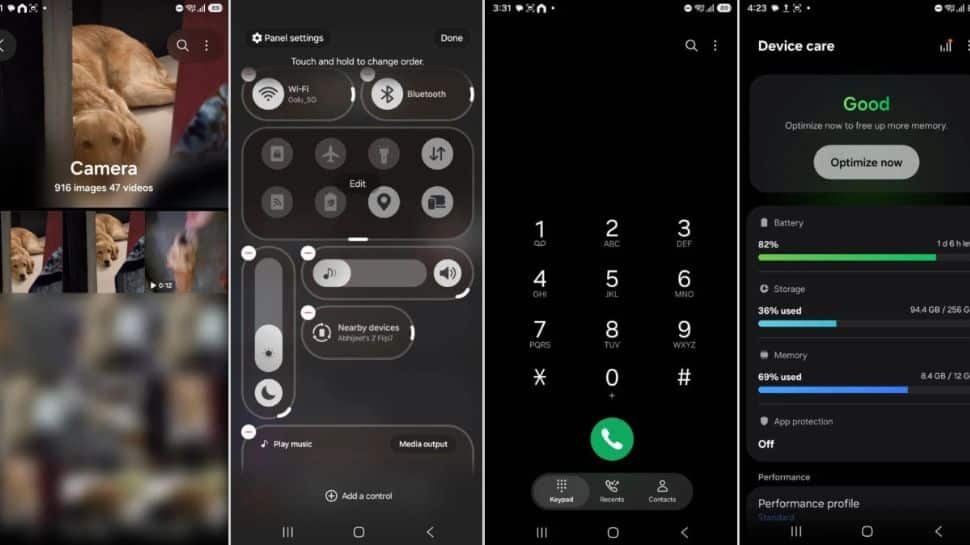
Samsung Rolls Out One UI 8.5 Beta Update In India For THESE Users; Check New Features, How To Install | Technology News
Samsung UI 8.5 Beta Update In India: South Korean giant Samsung has released the One UI 8.5 Beta update in India. It brings new features to improve productivity, privacy, and connectivity for Samsung Galaxy S25 series users. The company is moving fast because it is not even 2026 yet, but the next major update is already here. Samsung One UI 8.5 follows the Android 16 update from earlier this year and is expected to be the final version before One UI 9 arrives in 2026. However, the update is part of a limited rollout across select markets, including Germany, Korea, Poland, the UK, and the US. The new One UI 8.5 claims upgraded cross-device actions, better device management and enhanced security. Samsung One UI 8.5 Beta Update: Key Features Add Zee News as a Preferred Source The new beta update brings several useful features. The Quick Share can now recognise people in your photos and suggest sending the images directly to those contacts. The Samsung S25 series users will also get Audio Broadcast with Auracast, which allows you to share your voice through nearby devices using your Galaxy phone microphones. The Storage share lets your phone display files from other Galaxy devices, including your TV, tablets and PCs, directly in the My Files app. The security has also been improved with new theft protection that keeps your phone safe if it is lost or stolen. The update does not introduce major design changes, as a refreshed interface is expected when the new One UI 9 version arrives next year. (Also Read: iPhone 17 Series, iPhone 16, And MacBook Pro Models Get Huge Discount In Apple Holiday Season Sale- Details Here) Samsung One UI 8.5 Beta Update: How To Install And Availability Step 1: Update the Samsung Members app to the latest version on your Galaxy S25. Step 2: Open the app and sign in with your Samsung account. Step 3: Tap the “One UI 8.5 Beta Program” banner at the top of the home screen. Step 4: Tap Register and follow the on screen prompts to enrol in the beta. Step 5: After registering, download and install the beta software following the instructions. To join the One UI 8.5 beta program, open the Samsung Members app where the registration banner will be visible. Once you sign up, you can easily download and install the new One UI 8.5 beta update. It is important to note that the available features may vary by region, and not all countries will receive the same set of updates.



