

New Delhi: The 5G services have been rolled out in all states and union territories (UTs) across the country and presently, these are available in 99.9 per cent of the districts, according to the government. As of October 31, telecom service providers (TSPs) have installed 5.08 lakh 5G Base Transceiver Stations (BTSs) across rural and urban areas of the country. It is to mention that more than 31 lakh Base Transceiver Stations (BTSs) have been installed across the country, informed Minister of State for Communications and Rural development, Dr. Pemmasani Chandra Sekhar, while replying to a question in the Rajya Sabha. To reduce call drops and improve internet connectivity in underserved areas, the government has taken several initiatives. Add Zee News as a Preferred Source These are BharatNet project for providing broadband connectivity in Gram Panchayats (GPs) and villages; scheme for providing mobile services in Left Wing Extremism (LWE) affected areas and in Aspirational Districts; 4G Saturation scheme to provide 4G mobile coverage in all uncovered villages; launch of GatiShakti Sanchar portal and RoW (Right of Way) Rules to streamline RoW permissions and clearance of installation of telecom infrastructure; and time-bound permission for use of street furniture for installation of small cells and telecommunication line. According to the minister, the telecom infrastructure are being deployed by private TSPs as well as state-led service providers. Further, telecom infrastructure are being shared by private and state-led service providers based on techno-commercial feasibility, he mentioned. Meanwhile, seven dedicated Working Groups constituted earlier by the Centre under the Bharat 6G Alliance have presented their progress and roadmap. Union Communications Minister Jyotiraditya Scindia said that technology, spectrum, devices, applications and sustainability verticals must align seamlessly for innovations to mature and scale. He said monthly joint reviews between working groups are essential to ensure that breakthroughs in one domain translate into actionable outcomes in others. The minister pointed out that spectrum policy will be central to India’s 6G strategy and noted that India has already undertaken significant spectrum refarming, with more planned ahead.

The Game Awards 2025: Clair Obscur: Expedition 33 Dominates With Multiple Wins | Technology News
The Game Awards 2025: The Game Awards 2025 concluded with a night full of excitement, major announcements, and close competition, but the biggest moment of the evening came with the reveal of the Game of the Year winner. This year, Clair Obscur: Expedition 33 claimed the top honour, marking a major achievement for Sandfall Interactive and Kepler Interactive. The ceremony carried strong momentum in the weeks leading up to the event, especially as Clair Obscur: Expedition 33 entered the show with 13 nominations, one of the highest counts in the history of The Game Awards. This year’s event reached audiences across the world through YouTube, Twitch, TikTok, Prime Video, and several regional streaming platforms. Alongside world-premiere trailers and new game reveals, viewers closely followed the award results. Several fan-favourite titles picked up early wins, adding to the suspense before the final category. By the end of the night, Clair Obscur: Expedition 33 not only secured Game of the Year but also dominated key creative categories. The game won Best Game Direction, Best Narrative, and Best Art Direction. Earlier in the season, it had already made headlines by winning Best Independent Game and Best Debut Indie Game, giving Sandfall Interactive a breakthrough year. Add Zee News as a Preferred Source (Also Read: OpenAI Launches ChatGPT-5.2: Check Latest Tools, Capabilities, Performance And Upgrades) The Game of the Year category featured tough competition, with nominees such as Death Stranding 2: On The Beach, Donkey Kong Bananza, Hades II, Hollow Knight: Silksong, and Kingdom Come: Deliverance II. Each title had strong support and critical praise, but Clair Obscur: Expedition 33 ultimately emerged as the standout. Other major categories also included returning franchises and new creative projects, adding to the diversity of this year’s lineup. With its multiple wins and record-setting nominations, Clair Obscur: Expedition 33 has made a significant mark on the gaming industry in 2025.

OpenAI Launches ChatGPT-5.2: Check Latest Tools, Capabilities, Performance And Upgrades | Technology News
Open AI has introduced ChatGPT-5.2 with major improvements across several key areas. The new version performs better at creating spreadsheets, building presentations, writing code, analysing images, and managing long or complex tasks. It can also handle multi-step projects more efficiently with advanced tool-use abilities. According to OpenAI, GPT-5.2 has recorded strong performance across several benchmark tests. On the GDPval assessment, the model scored higher than human professionals in well-defined knowledge-based tasks covering 44 occupations. Add Zee News as a Preferred Source
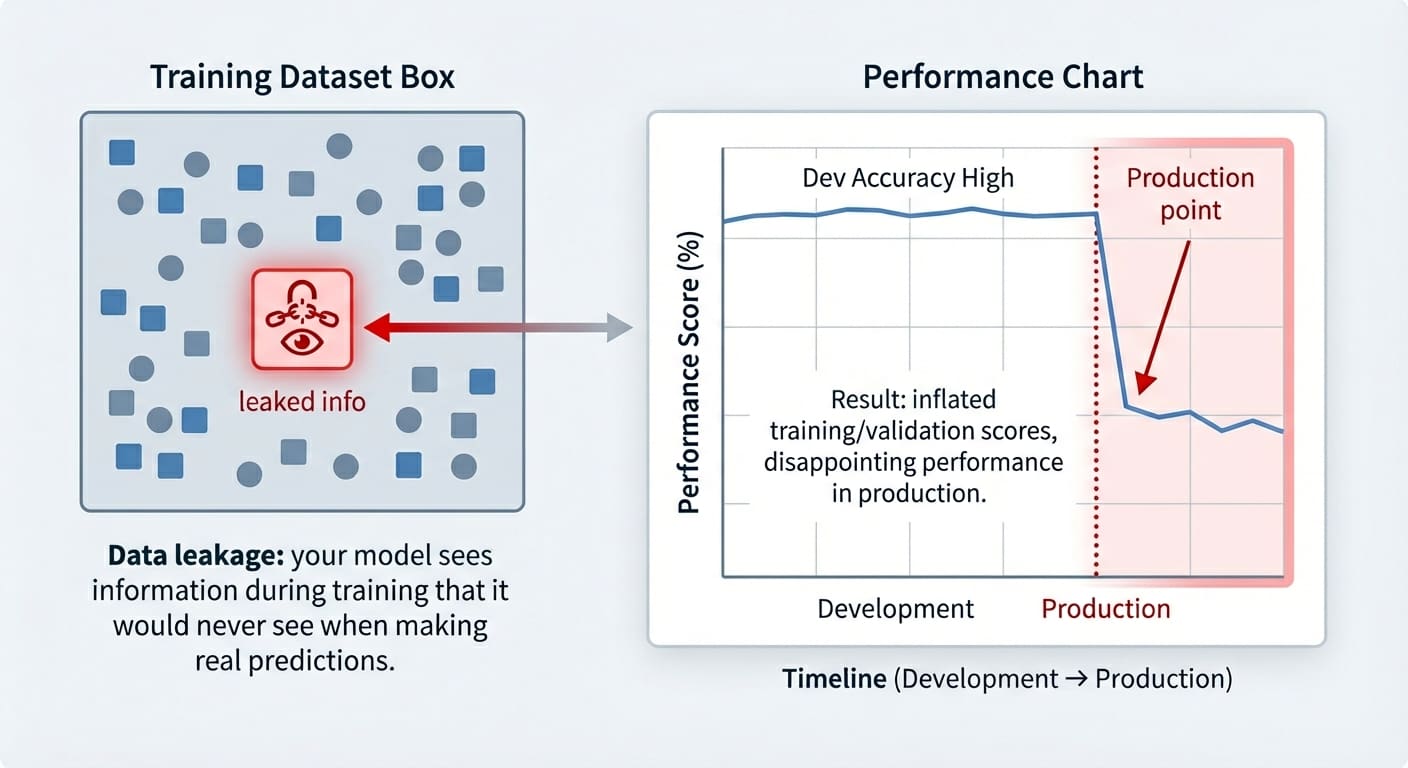
3 Subtle Ways Data Leakage Can Ruin Your Models (and How to Prevent It)
In this article, you will learn what data leakage is, how it silently inflates model performance, and practical patterns for preventing it across common workflows. Topics we will cover include: Identifying target leakage and removing target-derived features. Preventing train–test contamination by ordering preprocessing correctly. Avoiding temporal leakage in time series with proper feature design and splits. Let’s get started. 3 Subtle Ways Data Leakage Can Ruin Your Models (and How to Prevent It)Image by Editor Introduction Data leakage is an often accidental problem that may happen in machine learning modeling. It happens when the data used for training contains information that “shouldn’t be known” at this stage — i.e. this information has leaked and become an “intruder” within the training set. As a result, the trained model has gained a sort of unfair advantage, but only in the very short run: it might perform suspiciously well on the training examples themselves (and validation ones, at most), but it later performs pretty poorly on future unseen data. This article shows three practical machine learning scenarios in which data leakage may happen, highlighting how it affects trained models, and showcasing strategies to prevent this issue in each scenario. The data leakage scenarios covered are: Target leakage Train-test split contamination Temporal leakage in time series data Data Leakage vs. Overfitting Even though data leakage and overfitting can produce similar-looking results, they are different problems. Overfitting arises when a model memorizes overly specific patterns from the training set, but the model is not necessarily receiving any illegitimate information it shouldn’t know at the training stage — it is just learning excessively from the training data. Data leakage, by contrast, occurs when the model is exposed to information it should not have during training. Moreover, while overfitting typically arises as a poorly generalizing model on the validation set, the consequences of data leakage may only surface at a later stage, sometimes already in production when the model receives truly unseen data. Data leakage vs. overfittingImage by Editor Let’s take a closer look at 3 specific data leakage scenarios. Scenario 1: Target Leakage Target leakage occurs when features contain information that directly or indirectly reveals the target variable. Sometimes this can be the result of a wrongly applied feature engineering process in which target-derived features have been introduced in the dataset. Passing training data containing such features to a model is comparable to a student cheating on an exam: part of the answers they should come up with by themselves has been provided to them. The examples in this article use scikit-learn, Pandas, and NumPy. Let’s see an example of how this problem may arise when training a dataset to predict diabetes. To do so, we will intentionally incorporate a predictor feature derived from the target variable, ‘target’ (of course, this issue in practice tends to happen by accident, but we are injecting it on purpose in this example to illustrate how the problem manifests!): from sklearn.datasets import load_diabetes import pandas as pd import numpy as np from sklearn.linear_model import LogisticRegression from sklearn.model_selection import train_test_split X, y = load_diabetes(return_X_y=True, as_frame=True) df = X.copy() df[‘target’] = (y > y.median()).astype(int) # Binary outcome # Add leaky feature: related to the target but with some random noise df[‘leaky_feature’] = df[‘target’] + np.random.normal(0, 0.5, size=len(df)) # Train and test model with leaky feature X_leaky = df.drop(columns=[‘target’]) y = df[‘target’] X_train, X_test, y_train, y_test = train_test_split(X_leaky, y, random_state=0, stratify=y) clf = LogisticRegression(max_iter=1000).fit(X_train, y_train) print(“Test accuracy with leakage:”, clf.score(X_test, y_test)) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 from sklearn.datasets import load_diabetes import pandas as pd import numpy as np from sklearn.linear_model import LogisticRegression from sklearn.model_selection import train_test_split X, y = load_diabetes(return_X_y=True, as_frame=True) df = X.copy() df[‘target’] = (y > y.median()).astype(int) # Binary outcome # Add leaky feature: related to the target but with some random noise df[‘leaky_feature’] = df[‘target’] + np.random.normal(0, 0.5, size=len(df)) # Train and test model with leaky feature X_leaky = df.drop(columns=[‘target’]) y = df[‘target’] X_train, X_test, y_train, y_test = train_test_split(X_leaky, y, random_state=0, stratify=y) clf = LogisticRegression(max_iter=1000).fit(X_train, y_train) print(“Test accuracy with leakage:”, clf.score(X_test, y_test)) Now, to compare accuracy results on the test set without the “leaky feature”, we will remove it and retrain the model: # Removing leaky feature and repeating the process X_clean = df.drop(columns=[‘target’, ‘leaky_feature’]) X_train, X_test, y_train, y_test = train_test_split(X_clean, y, random_state=0, stratify=y) clf = LogisticRegression(max_iter=1000).fit(X_train, y_train) print(“Test accuracy without leakage:”, clf.score(X_test, y_test)) # Removing leaky feature and repeating the process X_clean = df.drop(columns=[‘target’, ‘leaky_feature’]) X_train, X_test, y_train, y_test = train_test_split(X_clean, y, random_state=0, stratify=y) clf = LogisticRegression(max_iter=1000).fit(X_train, y_train) print(“Test accuracy without leakage:”, clf.score(X_test, y_test)) You may get a result like: Test accuracy with leakage: 0.8288288288288288 Test accuracy without leakage: 0.7477477477477478 Test accuracy with leakage: 0.8288288288288288 Test accuracy without leakage: 0.7477477477477478 Which makes us wonder: wasn’t data leakage supposed to ruin our model, as the article title suggests? In fact, it is, and this is why data leakage can be difficult to spot until it might be late: as mentioned in the introduction, the problem often manifests as inflated accuracy both in training and in validation/test sets, with the performance downfall only noticeable once the model is exposed to new, real-world data. Strategies to prevent it ideally include a combination of steps like carefully analyzing correlations between the target and the rest of the features, checking feature weights in a newly trained model and seeing if any feature has an overly large weight, and so on. Scenario 2: Train-Test Split Contamination Another very frequent data leakage scenario often arises when we don’t prepare the data in the right order, because yes, order matters in data preparation and preprocessing. Specifically, scaling the data before splitting it into training and test/validation sets can be the perfect recipe to accidentally (and very subtly) incorporate test data information — through the statistics used for scaling — into the training process. These quick code excerpts based on the popular wine dataset show

What Is ‘Instagram Your Algorithm’ Feature Trending On Google Today | Technology News
The phrase ‘Instagram Your Algorithm’ has unexpectedly surged on Google Trends as of December 11, 2025 all thanks to Instagram’s newest feature that has the internet talking. The platform has rolled out a tool called ‘Your Algorithm,’ allowing users to understand why certain Reels appear on their feed and giving them greater control over their recommendations. The update has sparked a wave of reactions across social media, particularly on X, pushing the term to the top of Google’s trending searches. What This New Feature Is About Add Zee News as a Preferred Source Instagram is introducing a new level of personalisation by letting users browse through a list of topics the platform believes they’re interested in. From this menu, people can fine-tune what they want to see more or less of on their Reels feed. According to Instagram head Adam Mosseri, the new ‘Your Algorithm’ tab will sit in the top right corner of the app. Inside, users will see an AI-generated breakdown of their interests based on recent activity, anything from painting and GRWM videos to chess or horror films. They’ll even be able to share this interest summary publicly with followers. The feature rolls out first in the US, with a global release planned soon. Instagram has been testing the tool for weeks, and Mosseri said similar transparency options will eventually arrive for the Explore tab as well.

Starlink India’s Massive Promise: How Satellite Internet Works And Why Starlink Is Different From Everything Else | Technology News
Internet connectivity in India is deeply unequal, from the fast fiber lines in cities to the remarkably slow and unreliable networks that starve millions of villages. Starlink – the satellite internet service from billionaire Elon Musk-led SpaceX – will soon launch in India, promising to change this all over with a radical new way to deliver direct internet access from space. Starlink is not yet another service; it is a very different way of looking at connectivity. A recent leak on the Starlink India website briefly flashed tentative pricing, hinting at a high-end offering: an estimated monthly fee of about Rs 8,600 and a hardware kit at approximately Rs 34,000. Starlink later clarified these plans were uploaded by mistake and are incorrect, adding that the official India plan has not been announced yet. However, several key regulatory approvals are pending, including official launch dates, which are still not certain despite Starlink having received preliminary approval from the central government. Add Zee News as a Preferred Source How Satellite Internet Works And Why Starlink Is Different Traditional satellite internet involves big satellites at high orbits, about 36,000 km from Earth. The signal is delayed because of the great distance, therefore presenting high latency. Starlink changes this completely. Low Earth Orbit: Starlink deploys thousands of small satellites orbiting at a much lower altitude of about 550 kilometers. This greatly reduced distance minimizes the travel time of data, therefore contributing to much lower latency and improved speed of the internet. The System: At one end, the Starlink system comprises a smart dish installed on the user’s roof and the constellation of LEO satellites. Data goes from the user’s Wi-Fi router to the dish, which links directly to the nearest Starlink satellite. From there, the data either goes to a ground station or jumps via laser links from one satellite to another before reaching the global internet. Global Constellation: Currently, there are over 8,500 Starlink LEO satellites in orbit actively working around the globe, and the total number launched has already approached 9,000. In fact, this dense network ensures continuous signal coverage virtually everywhere. Bridging India’s Connectivity Gap Indeed, the Starlink model is all the more exciting for India, where laying fiber optic cables across challenging terrain-mountains, forests, remote villages, and border areas-is often difficult or impossible. Starlink bypasses infrastructure, whereas traditional internet needs multi-layered ground infrastructure in the form of fiber, towers, and undersea cables. The dish connects directly with the satellite network for high-speed internet at places that are unreachable by cables. Easy Installation: Your dish is smart, it self-locates and adjusts for the right satellite, without repeated engineering visits. Reliability: Starlink boasts an impressive 99.9% uptime. Since it’s satellite-based, it’s immune to the common problems of traditional internet-service hiccups, like fiber cuts that could leave you with no service for hours. Market Impact And Challenges In India While Starlink is often viewed as a solution to all of India’s internet problems, experts warn against this expectation. This calls for a focus on connectivity, not on speeds. While Starlink offers decent speed, it may not match the full range of fiber speeds offered in Indian cities. The true value of Starlink is in connection where the laying of optical fiber is difficult. For rural schools, health centers, and government offices in difficult terrains, the Starlink may be invaluable for telemedicine, e-governance, and digital payments. Affordability Hurdle: The service is pricey, and high costs for the hardware and monthly fees will restrict immediate mass adoption in India’s price-sensitive market. Challenges: The service is not without its shortcomings. Inclement rain, heavy cloud cover, or obstruction on the roof will now and then weaken the signal. With Starlink’s entry into India, it is a signal that the future of connectivity is being built in space. Much like how cell phone networks revolutionised communication, satellite internet can bring critical digital access to areas currently receiving a perpetual “No Signal” message. ALSO READ | What Is The Trump Gold Card? New USD 1M Visa Offers Expedited Path To Permanent US Residency
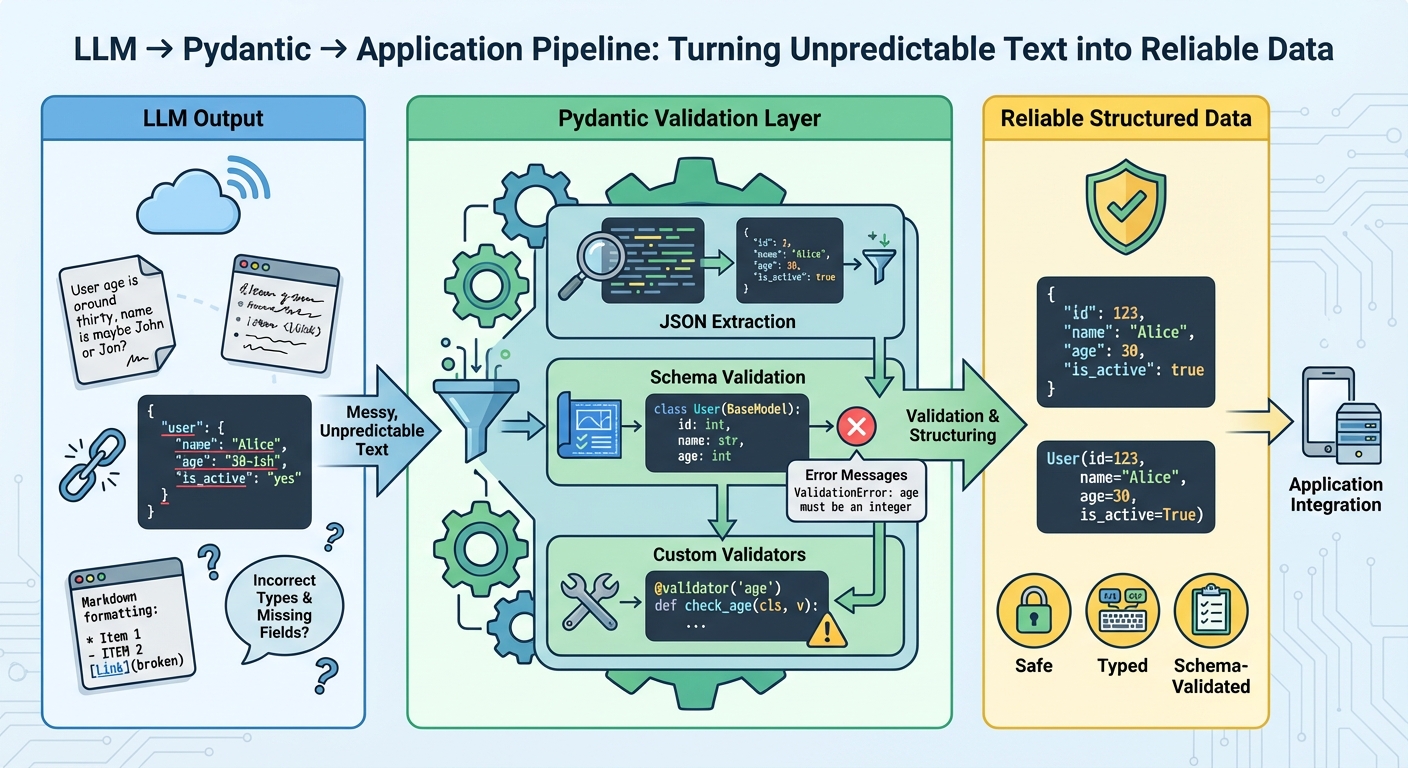
The Complete Guide to Using Pydantic for Validating LLM Outputs
In this article, you will learn how to turn free-form large language model (LLM) text into reliable, schema-validated Python objects with Pydantic. Topics we will cover include: Designing robust Pydantic models (including custom validators and nested schemas). Parsing “messy” LLM outputs safely and surfacing precise validation errors. Integrating validation with OpenAI, LangChain, and LlamaIndex plus retry strategies. Let’s break it down. The Complete Guide to Using Pydantic for Validating LLM OutputsImage by Editor Introduction Large language models generate text, not structured data. Even when you prompt them to return structured data, they’re still generating text that looks like valid JSON. The output may have incorrect field names, missing required fields, wrong data types, or extra text wrapped around the actual data. Without validation, these inconsistencies cause runtime errors that are difficult to debug. Pydantic helps you validate data at runtime using Python type hints. It checks that LLM outputs match your expected schema, converts types automatically where possible, and provides clear error messages when validation fails. This gives you a reliable contract between the LLM’s output and your application’s requirements. This article shows you how to use Pydantic to validate LLM outputs. You’ll learn how to define validation schemas, handle malformed responses, work with nested data, integrate with LLM APIs, implement retry logic with validation feedback, and more. Let’s not waste any more time. 🔗 You can find the code on GitHub. Before you go ahead, install Pydantic version 2.x with the optional email dependencies: pip install pydantic[email]. Getting Started Let’s start with a simple example by building a tool that extracts contact information from text. The LLM reads unstructured text and returns structured data that we validate with Pydantic: from pydantic import BaseModel, EmailStr, field_validator from typing import Optional class ContactInfo(BaseModel): name: str email: EmailStr phone: Optional[str] = None company: Optional[str] = None @field_validator(‘phone’) @classmethod def validate_phone(cls, v): if v is None: return v cleaned = ”.join(filter(str.isdigit, v)) if len(cleaned) < 10: raise ValueError(‘Phone number must have at least 10 digits’) return cleaned 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 from pydantic import BaseModel, EmailStr, field_validator from typing import Optional class ContactInfo(BaseModel): name: str email: EmailStr phone: Optional[str] = None company: Optional[str] = None @field_validator(‘phone’) @classmethod def validate_phone(cls, v): if v is None: return v cleaned = ”.join(filter(str.isdigit, v)) if len(cleaned) < 10: raise ValueError(‘Phone number must have at least 10 digits’) return cleaned All Pydantic models inherit from BaseModel, which provides automatic validation. Type hints like name: str help Pydantic validate types at runtime. The EmailStr type validates email format without needing a custom regex. Fields marked with Optional[str] = None can be missing or null. The @field_validator decorator lets you add custom validation logic, like cleaning phone numbers and checking their length. Here’s how to use the model to validate sample LLM output: import json llm_response=””‘ { “name”: “Sarah Johnson”, “email”: “sarah.johnson@techcorp.com”, “phone”: “(555) 123-4567”, “company”: “TechCorp Industries” } ”’ data = json.loads(llm_response) contact = ContactInfo(**data) print(contact.name) print(contact.email) print(contact.model_dump()) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 import json llm_response = ”‘ { “name”: “Sarah Johnson”, “email”: “sarah.johnson@techcorp.com”, “phone”: “(555) 123-4567”, “company”: “TechCorp Industries” } ‘” data = json.loads(llm_response) contact = ContactInfo(**data) print(contact.name) print(contact.email) print(contact.model_dump()) When you create a ContactInfo instance, Pydantic validates everything automatically. If validation fails, you get a clear error message telling you exactly what went wrong. Parsing and Validating LLM Outputs LLMs don’t always return perfect JSON. Sometimes they add markdown formatting, explanatory text, or mess up the structure. Here’s how to handle these cases: from pydantic import BaseModel, ValidationError, field_validator import json import re class ProductReview(BaseModel): product_name: str rating: int review_text: str would_recommend: bool @field_validator(‘rating’) @classmethod def validate_rating(cls, v): if not 1 <= v <= 5: raise ValueError(‘Rating must be an integer between 1 and 5′) return v def extract_json_from_llm_response(response: str) -> dict: “””Extract JSON from LLM response that might contain extra text.””” json_match = re.search(r’\{.*\}’, response, re.DOTALL) if json_match: return json.loads(json_match.group()) raise ValueError(“No JSON found in response”) def parse_review(llm_output: str) -> ProductReview: “””Safely parse and validate LLM output.””” try: data = extract_json_from_llm_response(llm_output) review = ProductReview(**data) return review except json.JSONDecodeError as e: print(f”JSON parsing error: {e}”) raise except ValidationError as e: print(f”Validation error: {e}”) raise except Exception as e: print(f”Unexpected error: {e}”) raise 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 from pydantic import BaseModel, ValidationError, field_validator import json import re class ProductReview(BaseModel): product_name: str rating: int review_text: str would_recommend: bool @field_validator(‘rating’) @classmethod def validate_rating(cls, v): if not 1 <= v <= 5: raise ValueError(‘Rating must be an integer between 1 and 5’) return v def extract_json_from_llm_response(response: str) -> dict: “”“Extract JSON from LLM response that might contain extra text.”“” json_match = re.search(r‘\{.*\}’, response, re.DOTALL) if json_match: return json.loads(json_match.group()) raise ValueError(“No JSON found in response”) def parse_review(llm_output: str) -> ProductReview: “”“Safely parse and validate LLM output.”“” try: data = extract_json_from_llm_response(llm_output) review = ProductReview(**data) return review except json.JSONDecodeError as e: print(f“JSON parsing error: {e}”) raise except ValidationError as e: print(f“Validation error: {e}”) raise except Exception as e: print(f“Unexpected error: {e}”) raise This approach uses regex to find JSON within response text, handling cases where the LLM adds explanatory text before or after the data. We catch different exception types separately: JSONDecodeError for malformed JSON, ValidationError for data that doesn’t match the schema, and General exceptions for unexpected issues. The extract_json_from_llm_response function handles text cleanup while parse_review handles validation, keeping concerns separated. In production, you’d want to log these errors or retry the LLM call with an improved prompt. This example shows an LLM response with extra text that our parser handles correctly: messy_response=””‘ Here’s the review in JSON format: {

Google Rolls Out AI Plus Plan In India With Expanded Access To Gemini 3 Pro; Check Storage And Subscription Price | Technology News
Google AI Plus Plan Price: Google has launched Google AI Plus in India, a new subscription plan that gives users access to its latest AI models, multimedia tools and other advanced features. With this plan, Google’s Gemini AI is directly integrated into apps like Gmail and Google Docs, and users also get extra storage and family sharing options. The subscription also includes expanded access to NotebookLM, helping users do deeper research and analysis. Google says the plan offers everything from wider access to Gemini 3 Pro in the Gemini app to improved image and video generation tools like Nano Banana Pro and Flow, unlocking more creative and productivity boosting features. Google AI Plus Plan: Storage And Subscription Price Add Zee News as a Preferred Source Subscribers get 200 GB of storage that works across Google Photos, Drive and Gmail. They can also share the benefits with up to five family members. Google says the plan is designed to give users an affordable way to access advanced AI features. Google AI Plus is priced at Rs 399 per month. New users can get it for Rs 199 per month for the first six months as an introductory offer. Google Unveiled Real-time Anti Scam Tools In November, Google shared a safety first road map for India that focuses on protecting children, teenagers and older adults as they use Artificial Intelligence. The company announced new on device, real time anti scam tools, text watermarking and digital literacy programs to help make AI safer and more inclusive for everyone. (Also Read: Vivo X300, Vivo X300 Pro Go On Sale In India; Check Camera, Battery, Display, Price, Availability, And Bank Offers) Google Scam Detection Feature The feature is powered by Gemini Nano, will be rolled out on Pixel phones to analyse calls in real time and flag potential scams entirely on-device, without recording audio, transcripts or sharing data with Google. The Scam Detection feature is off by default, applies only to calls from unknown numbers (not saved contacts), emits a beep to notify participants, and can be turned off by the user, it added. (With IANS Inputs)

Google, Microsoft And Amazon Bet Big On India With Huge $67.5 Billion Total Investments | Technology News
New Delhi: India is rapidly emerging one of the world’s most attractive destinations for artificial intelligence (AI) investments, with three global technology giants Amazon, Microsoft and Google have announced $67.5 billion commitments to build the country’s digital future. A young population, affordable data and a fast-growing digital ecosystem are helping transform India into a major hub for AI-led innovation, drawing unprecedented interest from companies like Amazon, Microsoft and Google. US e-commerce leader Amazon has unveiled plans to invest more than $35 billion in India by 2030, strengthening what it calls its three strategic pillars — AI-driven digitisation, export growth and job creation. The company said its investments will expand AI capabilities, improve logistics infrastructure and support lakhs of small businesses across the country. Add Zee News as a Preferred Source Microsoft has announced an equally ambitious move, committing $17.5 billion over four years (2026–2029) to scale up cloud and AI infrastructure, expand skilling programmes, and strengthen sovereign-ready digital capabilities across India. The announcement followed CEO Satya Nadella’s meeting with Prime Minister Narendra Modi, who said India’s youth will harness this opportunity to “innovate and leverage the power of AI for a better planet”. He also said that the country is on track to become the world’s largest developer community by 2030. Highlighting the country’s growing talent and its emerging leadership in next-generation AI innovation, Nadella said, “India is projected to have 57.5 million developers by 2030, making it the largest developer base globally.” Google has also made a major commitment, announcing a $15 billion investment to build a world-class AI hub in Visakhapatnam (Vizag). In partnership with AdaniConneX and Airtel, Google will develop India’s largest AI data centre campus, powered by clean energy and supported by a subsea cable network. Experts say the investment marks a shift in India’s tech map beyond Bengaluru and Hyderabad, potentially giving the country a new global-scale innovation centre on its east coast.

Apple iPhone 16, iPhone 16 Pro Max Get Massive Discount On THIS Platform; Check Camera, Battery, Display, Price And Other Specs | Technology News
Apple iPhone 16 Pro Max Flipkart Price: Flipkart’s Buy Buy 2025 sale is going to end with in couple of days. This sale is offering some of the biggest year end deals on popular gadgets. One of the best offers in this sale is on Apple’s iPhone 16 and iPhone 16 Pro Max. Flipkart is giving straight discounts, bank offers and exchange deals, which means you can get the iPhone 16 for less than Rs 40,000 if you combine all the benefits. At the same time, Flipkart is also offering a huge discount of more than Rs 10,000 on the iPhone 16 Pro Max. This makes it a great chance to buy Apple’s premium phone at a lower price than usual. These offers are not expected to stay for long, so interested buyers should make their purchase before the deals end. Apple iPhone 16 Specifications Add Zee News as a Preferred Source The premium smartphone features a 6.1 inch Super Retina XDR OLED display with HDR10 support and offers up to 1600 nits peak brightness outdoors, making the screen clear and bright even in sunlight. It runs on Apple’s A16 Bionic chipset, built on TSMC’s advanced 3nm process for faster performance and better efficiency. The phone is backed by a 3561mAh battery and comes with 8GB RAM along with 128GB or 256GB storage options. In the camera department, the iPhone 16 includes a dual camera setup with a 48MP primary sensor and a 12MP ultrawide sensor, while the front houses a 12MP camera for selfies and video calls. Apple iPhone 16 (128 GB Variant) Discount The iPhone 16 base model, which comes with 8GB RAM and 128GB storage, is now available at Apple for Rs 69,900. This is much lower than its original price of Rs 79,900, giving buyers a direct discount of Rs 10,000. With bank discounts and exchange offers, the price can drop even further, going down to around Rs 40,000. Consumers can also get a special flat discount of Rs 8,501 and choose no cost EMI options, making the deal even more affordable. If you use the exchange option, you can get up to Rs 57,400 off, making the deal even more affordable. Apple iPhone 16 Pro Max Specifcations The iPhone features a large 6.9 inch Super Retina XDR all screen OLED display with a sharp 2868×1320 pixel resolution at 460 ppi, offering bright and detailed visuals. It is powered by the A18 Pro chip, which includes a new 6 core CPU with two performance cores and four efficiency cores for smooth and powerful performance. The phone comes with a triple camera setup on the back, including a 48MP main camera with dual pixel PDAF and sensor shift OIS, a 12MP telephoto lens with 3D sensor shift OIS and 5x optical zoom, and a 48MP ultrawide camera. For selfies, it has a 12MP front camera. The device is equipped with a 4685mAh Li Ion battery that provides reliable all day usage. Apple iPhone 16 Pro Max (256 GB Variant) Discount The Apple iPhone 16 Pro Max (256 GB variant) is currently priced at Rs 1,34,900, which is Rs 10,000 lower than its original launch price of Rs 1,44,900. Buyers can also take advantage of additional bank offers, including 5 percent cashback on Axis Bank Flipkart Debit Cards (up to Rs 750) and 5 percent cashback on Flipkart SBI Credit Cards (up to Rs 4,000 per calendar quarter). The deal becomes even better with the exchange option, where users can get up to Rs 57,400 off depending on the device they trade in.



