

import dataclasses import functools import os import datasets import tokenizers import torch import torch.distributed as dist import torch.nn as nn import torch.nn.functional as F import torch.optim.lr_scheduler as lr_scheduler import tqdm from torch import Tensor from torch.distributed.algorithms._checkpoint.checkpoint_wrapper import ( apply_activation_checkpointing, checkpoint_wrapper, ) from torch.distributed.checkpoint import load, save from torch.distributed.checkpoint.state_dict import ( StateDictOptions, get_state_dict, set_state_dict, ) from torch.distributed.fsdp import ( CPUOffloadPolicy, FSDPModule, MixedPrecisionPolicy, fully_shard, ) from torch.distributed.fsdp.wrap import transformer_auto_wrap_policy from torch.utils.data.distributed import DistributedSampler # Build the model @dataclasses.dataclass class LlamaConfig: “”“Define Llama model hyperparameters.”“” vocab_size: int = 50000 # Size of the tokenizer vocabulary max_position_embeddings: int = 2048 # Maximum sequence length hidden_size: int = 768 # Dimension of hidden layers intermediate_size: int = 4*768 # Dimension of MLP’s hidden layer num_hidden_layers: int = 12 # Number of transformer layers num_attention_heads: int = 12 # Number of attention heads num_key_value_heads: int = 3 # Number of key-value heads for GQA class RotaryPositionEncoding(nn.Module): “”“Rotary position encoding.”“” def __init__(self, dim: int, max_position_embeddings: int) -> None: “”“Initialize the RotaryPositionEncoding module. Args: dim: The hidden dimension of the input tensor to which RoPE is applied max_position_embeddings: The maximum sequence length of the input tensor ““” super().__init__() self.dim = dim self.max_position_embeddings = max_position_embeddings # compute a matrix of n\theta_i N = 10_000.0 inv_freq = 1.0 / (N ** (torch.arange(0, dim, 2) / dim)) inv_freq = torch.cat((inv_freq, inv_freq), dim=–1) position = torch.arange(max_position_embeddings) sinusoid_inp = torch.outer(position, inv_freq) # save cosine and sine matrices as buffers, not parameters self.register_buffer(“cos”, sinusoid_inp.cos()) self.register_buffer(“sin”, sinusoid_inp.sin()) def forward(self, x: Tensor) -> Tensor: “”“Apply RoPE to tensor x. Args: x: Input tensor of shape (batch_size, seq_length, num_heads, head_dim) Returns: Output tensor of shape (batch_size, seq_length, num_heads, head_dim) ““” batch_size, seq_len, num_heads, head_dim = x.shape device = x.device dtype = x.dtype # transform the cosine and sine matrices to 4D tensor and the same dtype as x cos = self.cos.to(device, dtype)[:seq_len].view(1, seq_len, 1, –1) sin = self.sin.to(device, dtype)[:seq_len].view(1, seq_len, 1, –1) # apply RoPE to x x1, x2 = x.chunk(2, dim=–1) rotated = torch.cat((–x2, x1), dim=–1) output = (x * cos) + (rotated * sin) return output class LlamaAttention(nn.Module): “”“Grouped-query attention with rotary embeddings.”“” def __init__(self, config: LlamaConfig) -> None: super().__init__() self.hidden_size = config.hidden_size self.num_heads = config.num_attention_heads self.head_dim = self.hidden_size // self.num_heads self.num_kv_heads = config.num_key_value_heads # GQA: H_kv < H_q # hidden_size must be divisible by num_heads assert (self.head_dim * self.num_heads) == self.hidden_size # Linear layers for Q, K, V projections self.q_proj = nn.Linear(self.hidden_size, self.num_heads * self.head_dim, bias=False) self.k_proj = nn.Linear(self.hidden_size, self.num_kv_heads * self.head_dim, bias=False) self.v_proj = nn.Linear(self.hidden_size, self.num_kv_heads * self.head_dim, bias=False) self.o_proj = nn.Linear(self.num_heads * self.head_dim, self.hidden_size, bias=False) def reset_parameters(self): self.q_proj.reset_parameters() self.k_proj.reset_parameters() self.v_proj.reset_parameters() self.o_proj.reset_parameters() def forward(self, hidden_states: Tensor, rope: RotaryPositionEncoding, attn_mask: Tensor) -> Tensor: bs, seq_len, dim = hidden_states.size() # Project inputs to Q, K, V query_states = self.q_proj(hidden_states).view(bs, seq_len, self.num_heads, self.head_dim) key_states = self.k_proj(hidden_states).view(bs, seq_len, self.num_kv_heads, self.head_dim) value_states = self.v_proj(hidden_states).view(bs, seq_len, self.num_kv_heads, self.head_dim) # Apply rotary position embeddings query_states = rope(query_states) key_states = rope(key_states) # Transpose tensors from BSHD to BHSD dimension for scaled_dot_product_attention query_states = query_states.transpose(1, 2) key_states = key_states.transpose(1, 2) value_states = value_states.transpose(1, 2) # Use PyTorch’s optimized attention implementation # setting is_causal=True is incompatible with setting explicit attention mask attn_output = F.scaled_dot_product_attention( query_states, key_states, value_states, attn_mask=attn_mask, dropout_p=0.0, enable_gqa=True, ) # Transpose output tensor from BHSD to BSHD dimension, reshape to 3D, and then project output attn_output = attn_output.transpose(1, 2).reshape(bs, seq_len, self.hidden_size) attn_output = self.o_proj(attn_output) return attn_output class LlamaMLP(nn.Module): “”“Feed-forward network with SwiGLU activation.”“” def __init__(self, config: LlamaConfig) -> None: super().__init__() # Two parallel projections for SwiGLU self.gate_proj = nn.Linear(config.hidden_size, config.intermediate_size, bias=False) self.up_proj = nn.Linear(config.hidden_size, config.intermediate_size, bias=False) self.act_fn = F.silu # SwiGLU activation function # Project back to hidden size self.down_proj = nn.Linear(config.intermediate_size, config.hidden_size, bias=False) def reset_parameters(self): self.gate_proj.reset_parameters() self.up_proj.reset_parameters() self.down_proj.reset_parameters() def forward(self, x: Tensor) -> Tensor: # SwiGLU activation: multiply gate and up-projected inputs gate = self.act_fn(self.gate_proj(x)) up = self.up_proj(x) return self.down_proj(gate * up) class LlamaDecoderLayer(nn.Module): “”“Single transformer layer for a Llama model.”“” def __init__(self, config: LlamaConfig) -> None: super().__init__() self.input_layernorm = nn.RMSNorm(config.hidden_size, eps=1e–5) self.self_attn = LlamaAttention(config) self.post_attention_layernorm = nn.RMSNorm(config.hidden_size, eps=1e–5) self.mlp = LlamaMLP(config) def reset_parameters(self): self.input_layernorm.reset_parameters() self.self_attn.reset_parameters() self.post_attention_layernorm.reset_parameters() self.mlp.reset_parameters() def forward(self, hidden_states: Tensor, rope: RotaryPositionEncoding, attn_mask: Tensor) -> Tensor: # First residual block: Self-attention residual = hidden_states hidden_states = self.input_layernorm(hidden_states) attn_outputs = self.self_attn(hidden_states, rope=rope, attn_mask=attn_mask) hidden_states = attn_outputs + residual # Second residual block: MLP residual = hidden_states hidden_states = self.post_attention_layernorm(hidden_states) hidden_states = self.mlp(hidden_states) + residual return hidden_states class LlamaModel(nn.Module): “”“The full Llama model without any pretraining heads.”“” def __init__(self, config: LlamaConfig) -> None: super().__init__() self.rotary_emb = RotaryPositionEncoding( config.hidden_size // config.num_attention_heads, config.max_position_embeddings, ) self.embed_tokens = nn.Embedding(config.vocab_size, config.hidden_size) self.layers = nn.ModuleList([ LlamaDecoderLayer(config) for _ in range(config.num_hidden_layers) ]) self.norm = nn.RMSNorm(config.hidden_size, eps=1e–5) def reset_parameters(self): self.embed_tokens.reset_parameters() for layer in self.layers: layer.reset_parameters() self.norm.reset_parameters() def forward(self, input_ids: Tensor, attn_mask: Tensor) -> Tensor: # Convert input token IDs to embeddings hidden_states = self.embed_tokens(input_ids) # Process through all transformer layers, then the final norm layer for layer in self.layers: hidden_states = layer(hidden_states, rope=self.rotary_emb, attn_mask=attn_mask) hidden_states = self.norm(hidden_states) # Return the final hidden states return hidden_states class LlamaForPretraining(nn.Module): def __init__(self, config: LlamaConfig) -> None: super().__init__() self.base_model = LlamaModel(config) self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False) def reset_parameters(self): self.base_model.reset_parameters() self.lm_head.reset_parameters() def forward(self, input_ids: Tensor, attn_mask: Tensor) -> Tensor: hidden_states = self.base_model(input_ids, attn_mask) return self.lm_head(hidden_states) def create_causal_mask(batch: Tensor, dtype: torch.dtype = torch.float32) -> Tensor: “”“Create a causal mask for self-attention. Args: batch: Batch of sequences, shape (batch_size, seq_len) dtype: Data type of the mask Returns: Causal mask of shape (seq_len, seq_len) ““” batch_size, seq_len = batch.shape mask = torch.full((seq_len, seq_len), float(“-inf”), device=batch.device, dtype=dtype) \ .triu(diagonal=1) return mask def create_padding_mask(batch: Tensor, padding_token_id: int, dtype: torch.dtype = torch.float32) -> Tensor: “”“Create a padding mask for a batch of sequences for self-attention. Args: batch: Batch of sequences, shape (batch_size, seq_len) padding_token_id: ID of the padding token dtype: Data type of the mask Returns: Padding mask of shape (batch_size, 1, seq_len, seq_len) ““” padded

5 Python Libraries for Advanced Time Series Forecasting
5 Python Libraries for Advanced Time Series ForecastingImage by Editor Introduction Predicting the future has always been the holy grail of analytics. Whether it is optimizing supply chain logistics, managing energy grid loads, or anticipating financial market volatility, time series forecasting is often the engine driving critical decision-making. However, while the concept is simple — using historical data to predict future values — the execution is notoriously difficult. Real-world data rarely adheres to the clean, linear trends found in introductory textbooks. Fortunately, Python’s ecosystem has evolved to meet this demand. The landscape has shifted from purely statistical packages to a rich array of libraries that integrate deep learning, machine learning pipelines, and classical econometrics. But with so many options, choosing the right framework can be overwhelming. This article cuts through the noise to focus on 5 powerhouse Python libraries designed specifically for advanced time series forecasting. We move beyond the basics to explore tools capable of handling high-dimensional data, complex seasonality, and exogenous variables. For each library, we provide a high-level overview of its standout features and a concise “Hello World” code snippet to familiarize yourself immediately. 1. Statsmodels statsmodels provides best-in-class models for non-stationary and multivariate time series forecasting, primarily based on methods from statistics and econometrics. It also offers explicit control over seasonality, exogenous variables, and trend components. This example shows how to import and use the library’s SARIMAX model (Seasonal AutoRegressive Integrated Moving Average with eXogenous regressors): from statsmodels.tsa.statespace.sarimax import SARIMAX model = SARIMAX(y, exog=X, order=(1,1,1), seasonal_order=(1,1,1,12)) res = model.fit() forecast = res.forecast(steps=12, exog=X_future) from statsmodels.tsa.statespace.sarimax import SARIMAX model = SARIMAX(y, exog=X, order=(1,1,1), seasonal_order=(1,1,1,12)) res = model.fit() forecast = res.forecast(steps=12, exog=X_future) 2. Sktime Fan of scikit-learn? Good news! sktime mimics the popular machine learning library’s style framework-wise, and it is suited for advanced forecasting tasks, enabling panel and multivariate forecasting through machine-learning model reduction and pipeline composition. For instance, the make_reduction() function takes a machine-learning model as a base component and applies recursion to perform predictions multiple steps ahead. Note that fh is the “forecasting horizon,” allowing prediction of n steps, and X_future is meant to contain future values for exogenous attributes, should the model utilize them. from sktime.forecasting.compose import make_reduction from sklearn.ensemble import RandomForestRegressor forecaster = make_reduction(RandomForestRegressor(), strategy=”recursive”) forecaster.fit(y_train, X_train) y_pred = forecaster.predict(fh=[1,2,3], X=X_future) from sktime.forecasting.compose import make_reduction from sklearn.ensemble import RandomForestRegressor forecaster = make_reduction(RandomForestRegressor(), strategy=“recursive”) forecaster.fit(y_train, X_train) y_pred = forecaster.predict(fh=[1,2,3], X=X_future) 3. Darts The Darts library stands out for its simplicity compared to other frameworks. Its high-level API combines classical and deep learning models to address probabilistic and multivariate forecasting problems. It also captures past and future covariates effectively. This example shows how to use Darts’ implementation of the N-BEATS model (Neural Basis Expansion Analysis for Interpretable Time Series Forecasting), an accurate choice to handle complex temporal patterns. from darts.models import NBEATSModel model = NBEATSModel(input_chunk_length=24, output_chunk_length=12, n_epochs=10) model.fit(series, verbose=True) forecast = model.predict(n=12) from darts.models import NBEATSModel model = NBEATSModel(input_chunk_length=24, output_chunk_length=12, n_epochs=10) model.fit(series, verbose=True) forecast = model.predict(n=12) 5 Python Libraries for Advanced Time Series Forecasting: A Simple ComparisonImage by Editor 4. PyTorch Forecasting For high-dimensional and large-scale forecasting problems with massive data, PyTorch Forecasting is a solid choice that incorporates state-of-the-art forecasting models like Temporal Fusion Transformers (TFT), as well as tools for model interpretability. The following code snippet illustrates, in a simplified fashion, the use of a TFT model. Although not explicitly shown, models in this library are typically instantiated from a TimeSeriesDataSet (in the example, dataset would play that role). from pytorch_forecasting import TemporalFusionTransformer tft = TemporalFusionTransformer.from_dataset(dataset) tft.fit(train_dataloader) pred = tft.predict(val_dataloader) from pytorch_forecasting import TemporalFusionTransformer tft = TemporalFusionTransformer.from_dataset(dataset) tft.fit(train_dataloader) pred = tft.predict(val_dataloader) 5. GluonTS Lastly, GluonTS is a deep learning–based library that specializes in probabilistic forecasting, making it ideal for handling uncertainty in large time series datasets, including those with non-stationary characteristics. We wrap up with an example that shows how to import GluonTS modules and classes — training a Deep Autoregressive model (DeepAR) for probabilistic time series forecasting that predicts a distribution of possible future values rather than a single point forecast: from gluonts.model.deepar import DeepAREstimator from gluonts.mx.trainer import Trainer estimator = DeepAREstimator(freq=”D”, prediction_length=14, trainer=Trainer(epochs=5)) predictor = estimator.train(train_data) from gluonts.model.deepar import DeepAREstimator from gluonts.mx.trainer import Trainer estimator = DeepAREstimator(freq=“D”, prediction_length=14, trainer=Trainer(epochs=5)) predictor = estimator.train(train_data) Wrapping Up Choosing the right tool from this arsenal depends on your specific trade-offs between interpretability, training speed, and the scale of your data. While classical libraries like Statsmodels offer statistical rigor, modern frameworks like Darts and GluonTS are pushing the boundaries of what deep learning can achieve with temporal data. There is rarely a “one-size-fits-all” solution in advanced forecasting, so we encourage you to use these snippets as a launchpad for benchmarking multiple approaches against one another. Experiment with different architectures and exogenous variables to see which library best captures the nuances of your signals. The tools are available; now it’s time to turn that historical noise into actionable future insights.

Train Your Large Model on Multiple GPUs with Pipeline Parallelism
import dataclasses import os import datasets import tokenizers import torch import torch.distributed as dist import torch.nn as nn import torch.nn.functional as F import torch.optim.lr_scheduler as lr_scheduler import tqdm from torch import Tensor from torch.distributed.checkpoint import load, save from torch.distributed.checkpoint.state_dict import StateDictOptions, get_state_dict, set_state_dict from torch.distributed.pipelining import PipelineStage, ScheduleGPipe # Build the model @dataclasses.dataclass class LlamaConfig: “”“Define Llama model hyperparameters.”“” vocab_size: int = 50000 # Size of the tokenizer vocabulary max_position_embeddings: int = 2048 # Maximum sequence length hidden_size: int = 768 # Dimension of hidden layers intermediate_size: int = 4*768 # Dimension of MLP’s hidden layer num_hidden_layers: int = 12 # Number of transformer layers num_attention_heads: int = 12 # Number of attention heads num_key_value_heads: int = 3 # Number of key-value heads for GQA class RotaryPositionEncoding(nn.Module): “”“Rotary position encoding.”“” def __init__(self, dim: int, max_position_embeddings: int) -> None: “”“Initialize the RotaryPositionEncoding module. Args: dim: The hidden dimension of the input tensor to which RoPE is applied max_position_embeddings: The maximum sequence length of the input tensor ““” super().__init__() self.dim = dim self.max_position_embeddings = max_position_embeddings # compute a matrix of n\theta_i N = 10_000.0 inv_freq = 1.0 / (N ** (torch.arange(0, dim, 2) / dim)) inv_freq = torch.cat((inv_freq, inv_freq), dim=–1) position = torch.arange(max_position_embeddings) sinusoid_inp = torch.outer(position, inv_freq) # save cosine and sine matrices as buffers, not parameters self.register_buffer(“cos”, sinusoid_inp.cos()) self.register_buffer(“sin”, sinusoid_inp.sin()) def forward(self, x: Tensor) -> Tensor: “”“Apply RoPE to tensor x. Args: x: Input tensor of shape (batch_size, seq_length, num_heads, head_dim) Returns: Output tensor of shape (batch_size, seq_length, num_heads, head_dim) ““” batch_size, seq_len, num_heads, head_dim = x.shape dtype = x.dtype # transform the cosine and sine matrices to 4D tensor and the same dtype as x cos = self.cos.to(dtype)[:seq_len].view(1, seq_len, 1, –1) sin = self.sin.to(dtype)[:seq_len].view(1, seq_len, 1, –1) # apply RoPE to x x1, x2 = x.chunk(2, dim=–1) rotated = torch.cat((–x2, x1), dim=–1) output = (x * cos) + (rotated * sin) return output class LlamaAttention(nn.Module): “”“Grouped-query attention with rotary embeddings.”“” def __init__(self, config: LlamaConfig) -> None: super().__init__() self.hidden_size = config.hidden_size self.num_heads = config.num_attention_heads self.head_dim = self.hidden_size // self.num_heads self.num_kv_heads = config.num_key_value_heads # GQA: H_kv < H_q # hidden_size must be divisible by num_heads assert (self.head_dim * self.num_heads) == self.hidden_size # Linear layers for Q, K, V projections self.q_proj = nn.Linear(self.hidden_size, self.num_heads * self.head_dim, bias=False) self.k_proj = nn.Linear(self.hidden_size, self.num_kv_heads * self.head_dim, bias=False) self.v_proj = nn.Linear(self.hidden_size, self.num_kv_heads * self.head_dim, bias=False) self.o_proj = nn.Linear(self.num_heads * self.head_dim, self.hidden_size, bias=False) def forward(self, hidden_states: Tensor, rope: RotaryPositionEncoding) -> Tensor: bs, seq_len, dim = hidden_states.size() # Project inputs to Q, K, V query_states = self.q_proj(hidden_states).view(bs, seq_len, self.num_heads, self.head_dim) key_states = self.k_proj(hidden_states).view(bs, seq_len, self.num_kv_heads, self.head_dim) value_states = self.v_proj(hidden_states).view(bs, seq_len, self.num_kv_heads, self.head_dim) # Apply rotary position embeddings query_states = rope(query_states) key_states = rope(key_states) # Transpose tensors from BSHD to BHSD dimension for scaled_dot_product_attention query_states = query_states.transpose(1, 2) key_states = key_states.transpose(1, 2) value_states = value_states.transpose(1, 2) # Use PyTorch’s optimized attention implementation # setting is_causal=True is incompatible with setting explicit attention mask attn_output = F.scaled_dot_product_attention( query_states, key_states, value_states, is_causal=True, dropout_p=0.0, enable_gqa=True, ) # Transpose output tensor from BHSD to BSHD dimension, reshape to 3D, and then project output attn_output = attn_output.transpose(1, 2).reshape(bs, seq_len, self.hidden_size) attn_output = self.o_proj(attn_output) return attn_output class LlamaMLP(nn.Module): “”“Feed-forward network with SwiGLU activation.”“” def __init__(self, config: LlamaConfig) -> None: super().__init__() # Two parallel projections for SwiGLU self.gate_proj = nn.Linear(config.hidden_size, config.intermediate_size, bias=False) self.up_proj = nn.Linear(config.hidden_size, config.intermediate_size, bias=False) self.act_fn = F.silu # SwiGLU activation function # Project back to hidden size self.down_proj = nn.Linear(config.intermediate_size, config.hidden_size, bias=False) def forward(self, x: Tensor) -> Tensor: # SwiGLU activation: multiply gate and up-projected inputs gate = self.act_fn(self.gate_proj(x)) up = self.up_proj(x) return self.down_proj(gate * up) class LlamaDecoderLayer(nn.Module): “”“Single transformer layer for a Llama model.”“” def __init__(self, config: LlamaConfig) -> None: super().__init__() self.input_layernorm = nn.RMSNorm(config.hidden_size, eps=1e–5) self.self_attn = LlamaAttention(config) self.post_attention_layernorm = nn.RMSNorm(config.hidden_size, eps=1e–5) self.mlp = LlamaMLP(config) def forward(self, hidden_states: Tensor, rope: RotaryPositionEncoding) -> Tensor: # First residual block: Self-attention residual = hidden_states hidden_states = self.input_layernorm(hidden_states) attn_outputs = self.self_attn(hidden_states, rope=rope) hidden_states = attn_outputs + residual # Second residual block: MLP residual = hidden_states hidden_states = self.post_attention_layernorm(hidden_states) hidden_states = self.mlp(hidden_states) + residual return hidden_states class LlamaModel(nn.Module): “”“The full Llama model without any pretraining heads.”“” def __init__(self, config: LlamaConfig) -> None: super().__init__() self.rope = RotaryPositionEncoding( config.hidden_size // config.num_attention_heads, config.max_position_embeddings, ) self.embed_tokens = nn.Embedding(config.vocab_size, config.hidden_size) self.layers = nn.ModuleDict({ str(i): LlamaDecoderLayer(config) for i in range(config.num_hidden_layers) }) self.norm = nn.RMSNorm(config.hidden_size, eps=1e–5) def forward(self, input_ids: Tensor) -> Tensor: # Convert input token IDs to embeddings if self.embed_tokens is not None: hidden_states = self.embed_tokens(input_ids) else: hidden_states = input_ids # Process through all transformer layers, then the final norm layer for n in range(len(self.layers)): if self.layers[str(n)] is not None: hidden_states = self.layers[str(n)](hidden_states, self.rope) if self.norm is not None: hidden_states = self.norm(hidden_states) # Return the final hidden states, and copy over the attention mask return hidden_states class LlamaForPretraining(nn.Module): def __init__(self, config: LlamaConfig) -> None: super().__init__() self.base_model = LlamaModel(config) self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False) def forward(self, input_ids: Tensor) -> Tensor: hidden_states = self.base_model(input_ids) if self.lm_head is not None: hidden_states = self.lm_head(hidden_states) return hidden_states # Generator function to create padded sequences of fixed length class PretrainingDataset(torch.utils.data.Dataset): def __init__(self, dataset: datasets.Dataset, tokenizer: tokenizers.Tokenizer, seq_length: int, device: torch.device = None): self.dataset = dataset self.tokenizer = tokenizer self.device = device self.seq_length = seq_length self.bot = tokenizer.token_to_id(“[BOT]”) self.eot = tokenizer.token_to_id(“[EOT]”) self.pad = tokenizer.token_to_id(“[PAD]”) def __len__(self): return len(self.dataset) def __getitem__(self, index): “”“Get a sequence of token ids from the dataset. [BOT] and [EOT] tokens are added. Clipped and padded to the sequence length. ““” seq = self.dataset[index][“text”] tokens: list[int] = [self.bot] + self.tokenizer.encode(seq).ids + [self.eot] # pad to target sequence length toklen = len(tokens) if toklen < self.seq_length+1: pad_length = self.seq_length+1 – toklen tokens += [self.pad] * pad_length # return the sequence x = torch.tensor(tokens[:self.seq_length], dtype=torch.int64, device=self.device) y = torch.tensor(tokens[1:self.seq_length+1], dtype=torch.int64, device=self.device) return x, y def load_checkpoint(model: nn.Module, optimizer: torch.optim.Optimizer) -> None: dist.barrier() model_state, optimizer_state = get_state_dict( model, optimizer, options=StateDictOptions(full_state_dict=True), ) load( {“model”: model_state, “optimizer”:
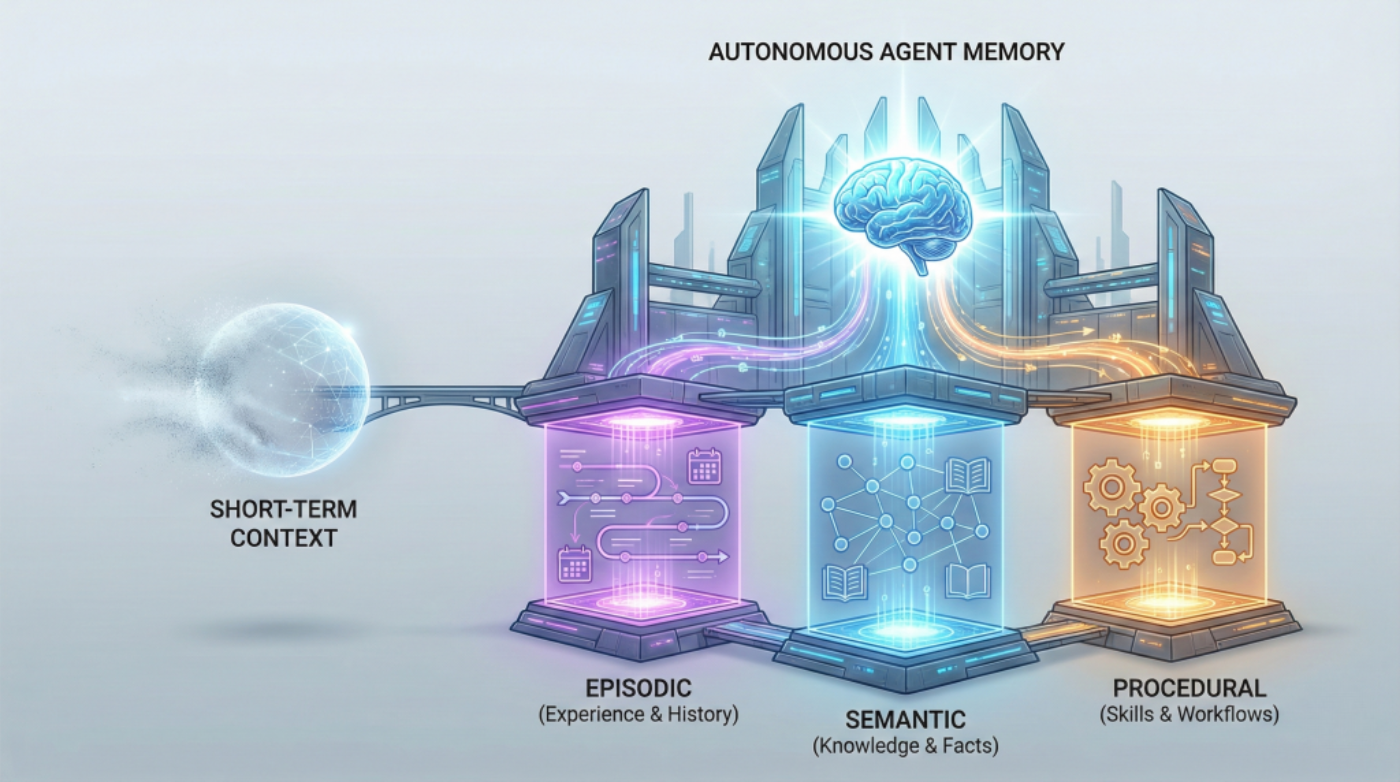
Beyond Short-term Memory: The 3 Types of Long-term Memory AI Agents Need
In this article, you will learn why short-term context isn’t enough for autonomous agents and how to design long-term memory that keeps them reliable across extended timelines. Topics we will cover include: The roles of episodic, semantic, and procedural memory in autonomous agents How these memory types interact to support real tasks across sessions How to choose a practical memory architecture for your use case Let’s get right to it. Beyond Short-term Memory: The 3 Types of Long-term Memory AI Agents NeedImage by Author If you’ve built chatbots or worked with language models, you’re already familiar with how AI systems handle memory within a single conversation. The model tracks what you’ve said, maintains context, and responds coherently. But that memory vanishes the moment the conversation ends. This works fine for answering questions or having isolated interactions. But what about AI agents that need to operate autonomously over weeks or months? Agents that schedule tasks, manage workflows, or provide personalized recommendations across multiple sessions? For these systems, session-based memory isn’t enough. The solution mirrors how human memory works. We don’t just remember conversations. We remember experiences (that awkward meeting last Tuesday), facts and knowledge (Python syntax, company policies), and learned skills (how to debug code, how to structure a report). Each type of memory serves a different purpose, and together they enable us to function effectively over time. AI agents need the same thing. Building agents that can learn from experience, accumulate knowledge, and execute complex tasks requires implementing three distinct types of long-term memory: episodic, semantic, and procedural. These aren’t just theoretical categories. They’re practical architectural decisions that determine whether your agent can truly operate autonomously or remains limited to simple, stateless interactions. Why Short-term Memory Hits a Wall Most developers are familiar with short-term memory in AI systems. It’s the context window that lets ChatGPT maintain coherence within a single conversation, or the rolling buffer that helps your chatbot remember what you said three messages ago. Short-term memory is essentially the AI’s working memory, useful for immediate tasks but limited in scope. Think of short-term memory like RAM in your computer. Once you close the application, it’s gone. Your AI agent forgets everything the moment the session ends. For basic question-answering systems, this limitation is manageable. But for autonomous agents that need to evolve, adapt, and operate independently across days, weeks, or months? Short-term memory isn’t enough. Even extremely large context windows simulate memory only temporarily. They don’t persist, accumulate, or improve across sessions without an external storage layer. The agents getting traction (the ones driving adoption of agentic AI frameworks and multi-agent systems) require a different approach: long-term memory that persists, learns, and guides intelligent action. The Three Pillars of Long-term Agent Memory Long-term memory in AI agents takes multiple forms. Autonomous agents need three distinct types of long-term memory, each serving a unique purpose. Each memory type answers a different question an autonomous agent must handle: What happened before? What do I know? How do I do this? Episodic Memory: Learning from Experience Episodic memory allows AI agents to recall specific events and experiences from their operational history. This stores what happened, when it happened, and what the outcomes were. Consider an AI financial advisor. With episodic memory, it doesn’t just know general investment principles; it remembers that three months ago, it recommended a tech stock portfolio to User A, and that recommendation underperformed. It recalls that User B ignored its advice about diversification and later regretted it. These specific experiences inform future recommendations in ways that general knowledge can’t. Episodic memory transforms an agent from a reactive system into one that learns from its own history. When your agent encounters a new situation, it can search its episodic memory for similar past experiences and adapt its approach based on what worked (or didn’t work) before. This memory type is often implemented using vector databases or other persistent storage layers, which enable semantic retrieval across past episodes. Instead of exact matching, the agent can find experiences that are conceptually similar to the current situation, even if the details differ. In practice, episodic memory stores structured records of interactions: timestamps, user identifiers, actions taken, environmental conditions, and outcomes observed. These episodes become case studies that the agent consults when making decisions, enabling a form of case-based reasoning that becomes more refined over time. Semantic Memory: Storing Structured Knowledge While episodic memory is about personal experiences, semantic memory stores factual knowledge and conceptual understanding. This is the facts, rules, definitions, and relationships the agent needs to reason about the world. A legal AI assistant relies heavily on semantic memory. It needs to know that contract law differs from criminal law, that certain clauses are standard in employment agreements, and that specific precedents apply in particular jurisdictions. This knowledge isn’t tied to specific cases it has worked on (that’s episodic), it’s general expertise that applies broadly. Semantic memory is often modeled using structured knowledge graphs or relational databases where entities and their relationships can be queried and reasoned over. That said, many agents also store unstructured domain knowledge in vector databases and retrieve it via RAG pipelines. When an agent needs to know “What are the side effects of combining these medications?” or “What are the standard security practices for API authentication?”, it’s querying semantic memory. The distinction between episodic and semantic memory matters for autonomous agents. Episodic memory tells the agent “Last Tuesday, when we tried approach X with client Y, it failed because of Z.” Semantic memory tells the agent “Approach X generally works best when conditions A and B are present.” Both are essential, but they serve different cognitive functions. For agents working in specialized domains, semantic memory often integrates with RAG systems to pull in domain-specific knowledge that wasn’t part of the base model’s training. This combination allows agents to maintain deep expertise without requiring massive model retraining. Over time, patterns extracted from episodic memory can be distilled into semantic knowledge, allowing agents to generalize

Moto G-Series Smartphone Users Alarmed After Device Reportedly Bursts Into Flames; User Slams Nehru Place Service Centre | Viral Video | Technology News
Motorola G-Series Phone Blast: What started as a normal day quickly turned scary when a Motorola G-series smartphone reportedly exploded inside a user’s pocket. According to a video shared by a user on X (formerly Twitter), the man was going about his daily routine when he suddenly felt intense heat, followed by a loud burst. Within moments, the phone caught fire and burned a hole in his pants, leaving him shocked and confused. People nearby rushed to help as smoke came out of the damaged device. Thankfully, the user did not suffer any serious injuries, but the incident left him shaken. Images of the burnt Motorola G-series phone later surfaced online, clearly showing the damage. The incident has raised fresh concerns about smartphone battery safety, overheating issues, and the risks of carrying phones in pockets. Notably, the device involved is believed to be the Motorola Moto G54 5G. Another Motorola G-series phone reportedly exploded in a user’s pocket, leaving a hole in the pants. The device was allegedly idle. Source: shubhxr_369 (Instagram) pic.twitter.com/uPXWvnvoUB Abhishek Yadav (@yabhishekhd) December 30, 2025 Add Zee News as a Preferred Source Motorola Service Centre: Worst Experience As per a video posted by a user on X (formerly Twitter), he said that after using the Motorola phone for about 8 to 9 months, the screen suddenly stopped responding. To fix the issue, he visited the Motorola Exclusive Service Centre in Nehru Place, but the experience was very disappointing. The service centre has no lift, making it difficult to access. It is also shared by Motorola and Lenovo, which leads to overcrowding and confusion. Motorola is really going downhill with no brakes… Just look at the condition of their service centers we tested recently…https://t.co/5qKkCTYkt3 SparkNherd (@SparkNherd) December 30, 2025 After taking a token, the user noticed that there was no display screen to show token numbers. The seating arrangement was poor, with only three chairs available. Two chairs were meant for laptop customers and just one for smartphone users. There was no staff member at the service desk, and when someone finally arrived, he did not know the token order and called customers randomly, making the token system meaningless. After completing the paperwork, the user was told on Saturday that he would receive a call on Monday with details about the phone issue. However, no one contacted him even by Thursday, showing a clear lack of coordination and poor customer support. (Also Read: Oppo Reno 15 Pro Mini Price Leaked Ahead Of Official Launch In India; Check Expected Camera, Battery, Display And Other Specs) Moto G54 5G Specifications The smartphone comes with a 6.5-inch LED display that supports a 120Hz refresh rate and offers Full HD+ resolution (2400 x 1080 pixels) for smooth and clear visuals. It is powered by the MediaTek Dimensity 7020 processor, featuring a 2.2GHz octa-core CPU and an IMG BXM-8-256 GPU for everyday performance. The device packs a 6000mAh battery with 33W fast charging support. On the back, it has a dual-camera setup with a 50-megapixel main camera with OIS and an 8-megapixel auto-focus camera, without any extra macro or depth lens. For selfies, it offers a 16-megapixel front camera and runs on Android 13, with an Android 14 update promised later. Moto G54 5G Price In India The Moto G54 5G is available in two variants. The 8GB RAM with 128GB storage model is priced at Rs 15,999, while the 12GB RAM with 256GB storage version costs Rs 18,999.

Govt Releases White Paper On Democratising Access To AI Infrastructure | Technology News
New Delhi: The Office of the Principal Scientific Adviser (PSA) to the Government on Tuesday released a white paper on democratizing access to Artificial Intelligence (AI) infrastructure. The white paper defines democratising access to AI infrastructure as making the AI infrastructure – compute, datasets, and model ecosystem available and affordable, such that it reaches a wide set of users. It refers to empowering a wide set of users to engage with and benefit from AI capabilities. When compute, datasets, and model tooling are broadly available, individuals and institutions expand what they can do, like aiming to design local language tools and adapt assistive technologies. The white paper has been prepared with inputs and feedback from domain experts and stakeholders, including the Niti Aayog, to foster informed deliberation and action in shaping India’s AI policy and governance landscape. Add Zee News as a Preferred Source “With AI becoming central to innovation and economic progress, access to compute, datasets, and model ecosystems must be made broad, affordable, and inclusive. These resources are concentrated in a few global firms and urban centres, limiting equitable participation,” the office of the PSA said in a post on social media. “For India, democratising access means treating AI infrastructure as a shared national resource, empowering innovators across regions to build local-language tools, adapt assistive technologies, and create solutions aligned with India’s diverse needs,” it added. The white paper highlights key enablers aligned with India’s AI governance vision, including expanding access to high-quality, representative datasets; providing affordable and reliable computing resources; and integrating AI with Digital Public Infrastructure (DPI). Democratising access to AI infrastructure is critical for ensuring fair and equitable opportunities and benefits across the country, from villages to cities, and from small institutions and startups to industry. Through tools and platforms like AIKosha, India AI Compute, and TGDeX, India’s AI ecosystem is supporting innovation and services by increasing access. Further, dedicated government initiatives on infrastructure development and increasing access to data and computing resources would empower the IndiaAI Mission, line ministries, sectoral regulators, and state governments, the white paper said.
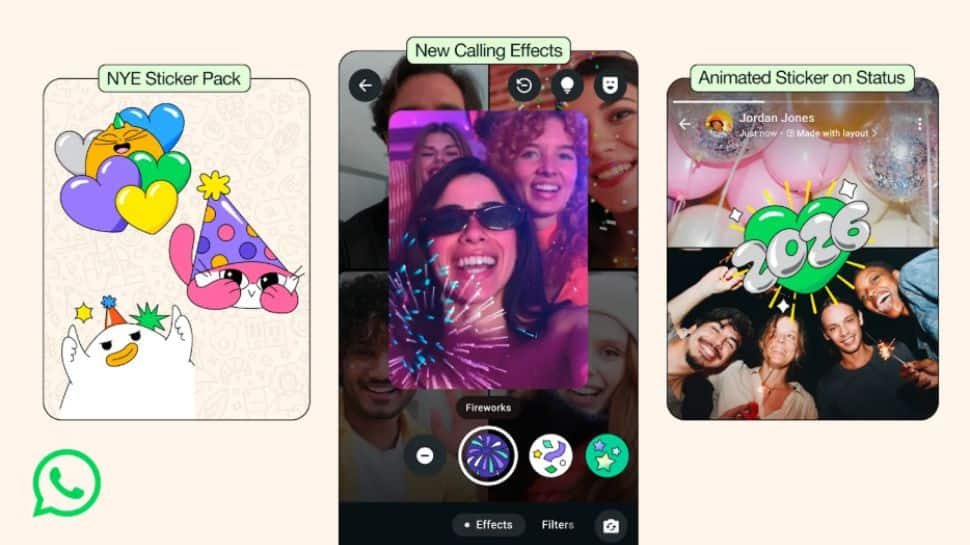
Happy New Year 2026: WhatsApp Rolls Out New Features With Video Call Effects, Status Tools And More | Technology News
WhatsApp Features For New Year 2026: WhatsApp, an instant messaging platform, has rolled out a new set of new features ahead of the New Year 2026, as the platform gets ready for its busiest day of the year. The Meta-owned platform says that New Year’s Day consistently sees the highest number of messages and calls, crossing its daily average of over 100 billion messages and nearly 2 billion calls worldwide. To mark the new year, WhatsApp is introducing four new features designed to add a festive touch to holiday greetings. These include new sticker packs, interactive effects for video calls, and more. The company is also bringing back animated confetti reactions. Adding further, WhatsApp is launching animated stickers for Status updates for the first time. Users can choose a special 2026-themed layout with animated stickers to share New Year wishes with their contacts. Add Zee News as a Preferred Source WhatsApp Features For New Year 2026 WhatsApp has added a fun and interactive touch to user conversations. It also introduced a new 2026-themed sticker pack that users can easily share in chats. During video calls, users can now apply eye-catching visual effects such as fireworks, confetti and stars through the effects option. WhatsApp has also enabled confetti emoji reactions, which trigger a special animated effect when used on messages. Adding further, the status updates are getting a celebratory upgrade with animated stickers and a dedicated 2026 layout designed specifically for New Year posts. WhatsApp Built-In Tools For New Year 2026 WhatsApp has also highlighted several easy-to-use tools to help users plan New Year celebrations smoothly in group chats. Users can create an event, pin it for everyone to see, collect RSVPs and share updates in one place. To simplify decisions, polls can be used to choose food, drinks or activities. Live location sharing helps friends reach the venue easily and ensures everyone gets home safely. Users can also send voice and video notes to share live moments with those who cannot attend the celebration.

Has GTA 6 Been Delayed Again To 2027? Check Expected Characters And India Pricing Of World’s Most Awaited Game | Technology News
GTA 6 Delayed: As we are inch closer to 2026, Rumours about another delay for Grand Theft Auto VI are once again spreading online. Several post on the social media platform now claiming that the Rockstar Games may push the much-awaited game to 2027. The GTA 6 was first announced with a trailer in December 2023 and was expected to release in 2025. Later, the company delayed it to 2026. The game was first planned for May 26, 2026, but Rockstar later said it would not meet that date. It was then moved to November 19, 2026. Since then, confusion and excitement among fans have continued to grow. GTA 6 Delay: Social Media Rumours Trigger Fresh Talk Add Zee News as a Preferred Source The revised November launch date was announced with the studio saying the extra months were essential to meet its quality standards. The recent fear of another delay seems to be coming from viral social media posts, not from official sources. When a few accounts talked about a possible delay to 2027, the rumour spread quickly online. This is total BS, I can confirm that GTA 6 is still too far out to determine if another delay is needed yet. These people are just stirring the pot for engagement. If I hear rumblings of another delay I will let you know but for now stop believing this crap. Relax GTA fans https://t.co/cu6bu0QFTd — Reece “Kiwi Talkz” Reilly (@kiwitalkz) November 28, 2025 No New Delay: Rockstar Focuses On Polishing GTA 6 However, as the talk of a 2027 delay grew louder, one familiar voice stepped in to clear the air. Reece “Kiwi Talkz” Reilly, a trusted insider known for tracking Rockstar closely, addressed the rumours head-on. He made it clear that no new delay has been planned. Rockstar Games, too, has stayed silent on any further changes, sticking to the November 2026 release. (Also Read: Oppo Reno 15 Pro Mini Price Leaked Ahead Of Official Launch In India; Check Expected Camera, Battery, Display And Other Specs) For now, the studio says the extra time is simply being used to polish the game and meet its quality goals. Moreover, the company also said the extra time would allow them to deliver the level of detail, scale, and refinement fans expect. GTA 6: New Characters And Indian Pricing The action-adventure game is set to introduce several exciting new features, including the franchise’s first-ever female lead, Lucia, alongside the male lead, Jason. Meanwhile, players can explore over 65% of buildings in the game, adding a whole new level of immersion. The game will also include unique elements like a love meter for the main characters and an in-game social media platform. According to the latest rumours, the Standard Edition of GTA 6 could be priced at around Rs 6,999 in India, giving fans a peek at both gameplay and availability details.

Oppo Reno 15 Pro Mini Price Leaked Ahead Of Official Launch In India; Check Expected Camera, Battery, Display And Other Specs | Technology News
Oppo Reno 15 Pro Mini Price In India: Oppo is set to bring the Oppo Reno15 series to the Indian market. The Chinese smartphone maker has confirmed that the standard Reno15 and Reno15 Pro will be joined by a smaller Oppo Reno15 Pro Mini this time. Oppo has revealed that the series is designed using its new HoloFusion Technology. A dedicated microsite for the upcoming smartphones is already live on an e-commerce platform. While all three models feature a similar design, they differ in their internal specifications. Notably, the Oppo Reno 15 series is expected to be available in Glacier White, Twilight Blue, and Aurora Blue colour options. The Oppo Reno 15 Pro Mini, Reno 15 Pro, and Reno 15 are likely to launch in January 2026. Oppo Reno 15 Pro Mini Price in India (Leaked) Add Zee News as a Preferred Source According to tipster Abhishek Yadav, the smartphone is said to have a box price of Rs 64,999 for the 12GB + 256GB variant. Since box prices in India are usually higher than the actual selling price, the phone could launch at around Rs 59,999. The tipster also suggests that this variant may indeed retail at Rs 59,999, with introductory bank offers possibly reducing the effective price further at launch. If this leaked pricing turns out to be accurate, it would mark a clear price hike for the Reno series. To recall, last year’s most expensive model, the OPPO Reno14 Pro, was launched at Rs 49,999 for the same 12GB + 256GB configuration. Oppo Reno 15 Pro Mini Specifications (Expected) The Oppo Reno 15 Pro Mini is expected to feature a compact yet immersive 6.32-inch AMOLED display with ultra-slim 1.6mm bezels, delivering an impressive 93.35 percent screen-to-body ratio. The handset is tipped to weigh around 187 grams and measure approximately 7.99mm in thickness. The smartphone is expected to be powered by MediaTek’s Dimensity 8450 chipset, paired with 12GB of RAM and up to 512GB of internal storage. Oppo has also confirmed robust durability, with the Reno 15 Pro Mini carrying IP66, IP68, and IP69 ratings for dust and water resistance, along with a platinum-coated USB Type-C port to enhance corrosion protection. The smartphone is further rumoured to pack a sizable 6,200mAh battery, supported by 80W fast charging. On the photography front, the device may feature a 200MP primary sensor, complemented by 50MP ultra-wide and 50MP telephoto cameras, while a 50MP front camera is likely to handle selfies and video calls.

PM Modi To Inaugurate India AI Impact Summit From Feb 15 To 20; Global CEOs, Including Bill Gates, Likely to Attend | Technology News
AI Impact Summit 2026: Prime Minister Narendra Modi will inaugurate the India AI Impact Summit and engage with global technology leaders during the high-profile event scheduled to be held from February 15 to February 20, Union Ministry of Electronics and Information Technology Secretary S Krishnan said on Monday. The Prime Minister will also host a gala dinner for visiting tech leaders as part of the summit programme. The Senior government officials said several top global CEOs have confirmed their participation. These include Bill Gates, Dario Amodei, Demis Hassabis, Shantanu Narayen and Marc Benioff. Jensen Huang is also expected to attend the summit, according to officials. India has formally invited China to take part in the summit as well. Krishnan said the invitation was extended as India positions the event as a global platform to promote the idea of “democratising AI”. The summit is expected to see participation from more than 100 countries, with invitations already sent to around 140 nations. Add Zee News as a Preferred Source “Over 100 AI leaders, including CEOs, CXOs and chief scientists, are likely to attend the main sessions,” he mentioned. Prime Minister Modi will inaugurate the AI Impact Expo on February 16. He will host a gala dinner for global technology leaders on February 18. The formal opening ceremony of the summit is scheduled for February 19, when the Prime Minister is also expected to attend a leaders’ plenary session and a CEO roundtable. A ministerial meeting of the Global Partnership on Artificial Intelligence will be held on February 20, bringing together policymakers from different countries. Other confirmed participants include Cristiano Amon and Raj Subramaniam, along with several global technology founders and academics. Krishnan said more than 50 CEOs and founders and over 100 senior academics have already confirmed their attendance. Ahead of the main summit, an innovation festival will begin on February 15 at Central Park in Connaught Place. This public event will showcase creative and social uses of artificial intelligence. During the summit week, around 800 parallel AI-related events are expected to take place across the country. The government expects more than 1.5 lakh people to attend events linked to the summit, including the expo.



