

Telecom Security Reforms: In a significant push to strengthen India’s telecom security ecosystem while easing regulatory burdens on the industry, the Department of Telecommunications (DoT), through the National Centre for Communication Security (NCCS), has rolled out a set of transformative reforms aimed at boosting indigenous manufacturing and testing capabilities, Union Minister of Communications Jyotiraditya Scindia said on Monday. “These transformative reforms will strengthen telecom security, reduce compliance burdens, enable sustainable industry growth, and reinforce PM @narendramodi ji’s vision of ‘Make in India, Make for the World,’” he said. The key reforms include the extension of the Pro Tem Security Certification Scheme for original equipment manufacturers (OEMs) for two years and reduced fees for Telecom Security Testing Laboratories (TSTLs), the minister added. Scindia said the reforms align with the DSS principle of “Design in India, Solve in India, Scale for the World.” Add Zee News as a Preferred Source “These measures deliver a crucial boost to ease of doing business for telecom equipment manufacturers, with a 90 percent reduction in compliance burden for women-led and MSME testing laboratories, while other testing labs will benefit from a 50 percent reduction. Central and state government testing agencies, Indian Institutes of Technology (IITs), and other government institutions have been granted a complete waiver of testing fees,” the minister said. Highlighting the impact of the policy, Scindia said it empowers manufacturers and accelerates innovation. “By simplifying security verification while maintaining robust safeguards, the policy empowers manufacturers, accelerates innovation, and expands broadband penetration nationwide,” he said. “These reforms also enable the development of swadeshi telecom security testing infrastructure and reinforce Bharat as a trusted telecom manufacturing and testing hub. Together, these transformative steps advance our shared vision of Atmanirbhar Bharat with security, scale, and speed,” he added in his post.

Tech Billionaire Elon Musk Accuses Microsoft Co-Founder Bill Gates, Calls Him A ‘Liar’; Check Their Net Worth | Technology News
Elon Musk Vs Bill Gates Net Worth: Tesla CEO Elon Musk and Microsoft co-founder Bill Gates are once again in the spotlight after the tech billionaire openly called Gates a “liar” on social media platform X. The tussle started when the world’s richest man Elon Musk reacted to a post that played down Bill Gates’ concerns about cuts in funding to the United States Agency for International Development (USAID). Elon Musk, who leads Tesla and SpaceX, replied to a post on X which said that anyone who believes USAID funding cuts caused deaths is “too stupid.” The post was referring to Gates’ earlier comments, where he warned that reducing USAID funding could lead to loss of lives. Billionaire Elon Musk responded by calling the claim “completely false.” Musk asserted Bill Gates was spreading a lie, even though he has more than $80 billion in his non-government group, which Musk said could be used to help save lives. Add Zee News as a Preferred Source It is completely false. Bill Gates is pushing this lie, despite having over $80 billion dollars in his NGO that he could easily spend to save these alleged lives that are being lost. Why doesn’t he? Bill Gates is a liar. Always has been. — Elon Musk (@elonmusk) December 29, 2025 Elon Musk Vs Bill Gates: What’s New This clash is not new. The disagreement between Elon Musk and Bill Gates started in May 2023. At that time, Bill Gates said Elon Musk was indirectly harming the world’s poorest children by supporting big cuts in foreign aid. Bill Gates warned that cutting USAID funding could lead to more cases of serious diseases like measles, HIV, and polio. Microsoft Co-founder Makes Bold Statement In an interview with the Financial Times, Bill Gates made a strong statement. He stated that the idea of “the world’s richest man killing the world’s poorest children” was very disturbing. At that time, Elon Musk was leading the Department of Government Efficiency (DOGE), a task force under the Donald Trump administration focused on cutting government spending. In February, the agency effectively shut down USAID, calling it a “criminal organisation” and saying it was “time for it to die.” (Also Read: Best Flagship Smartphones 2025 Launched In India) Billionaire Elon Musk Cancelled Grants Bill Gates also claimed that the tech billionaire cancelled funding for hospitals in Mozambique’s Gaza Province. He said these grants helped stop the spread of HIV. Adding further, Bill Gates said he would like Elon Musk to visit the children who were infected with HIV after the funding was cut. Elon Musk Vs Bill Gates: Net Worth According to the Forbes Real-Time Billionaires List, Tesla and SpaceX founder Elon Musk, currently the world’s richest person with an estimated net worth of $480.5 billion (around Rs 39.88 lakh crore), is on track to become the world’s first Trillionaire. According to Forbes, Bill Gates’ net worth stands at US$115.1 billion (around Rs 9.55 lakh crore).

What Is Virtual Private Network? How VPN Works And Why Users Choose It: Pros and Cons Explained, Check How To Install | Technology News
VPN Benefits: With the rapid growth of the internet, online privacy and data security have become major concerns for users worldwide. It often begins with a simple click, whether it is checking a bank balance during a coffee break, ordering groceries late at night, scrolling through social media, or logging in for a work call from home. Every day, millions of people leave behind digital footprints without realizing how much personal information travels across the internet. To stay safe in this digital environment, many users rely on a VPN, also known as a Virtual Private Network. What Is VPN? A VPN is a service that helps protect your online activity by creating a secure connection between your device and the internet. When you connect to a VPN, your real IP address is hidden and replaced with the IP address of the VPN server. This makes it harder for websites, advertisers, and third parties to track your online behavior or location. In simple terms, a VPN acts as a protective layer between you and the internet, helping you browse more safely and privately. Add Zee News as a Preferred Source How Does VPN Work? When a VPN is turned on, it encrypts the data sent from your device. This encrypted data is then routed through a VPN server before reaching the website you want to visit. The website sees the VPN server’s location instead of your real location. When the website sends information back, it follows the same secure path. Because the data is encrypted, even if someone tries to intercept it, they cannot read or misuse it. This is especially useful when using public Wi-Fi networks at airports, cafés, hotels, or malls. VPN Benefits: One of the biggest benefits of using a VPN is improved privacy. Since your IP address is hidden, websites and advertisers cannot easily track your browsing habits. This helps reduce targeted ads and protects your personal information. Security is another major advantage. VPNs protect sensitive data such as login details, payment information, and private messages. This is important for remote workers and students who access important accounts online. VPNs also allow users to access region-restricted content. Some websites, apps, and streaming platforms limit access based on location. By connecting to a server in another country, users can view content that may not be available in their region. Another benefit is protection from internet speed throttling. Some internet service providers slow down connections during streaming or gaming. A VPN can help prevent this by hiding your online activity. VPN Cons: Using a VPN also comes with certain drawbacks that users should be aware of. Internet speeds may slow down because data is encrypted and routed through an additional server, which is more noticeable with free or heavily loaded VPN services. Not all VPN providers are trustworthy, as some free options may track user activity or display ads, which can compromise privacy instead of improving it. The high-quality VPN services usually require a paid subscription, making them less appealing for users looking for free solutions. In some cases, websites and streaming platforms block VPN traffic, limiting access even when the VPN is active. VPN usage is also restricted or regulated in certain countries, so users must be aware of local laws and policies. Adding further, running a VPN continuously can increase battery consumption on mobile devices and may use more data. Why Users Choose THESE VPNs Users prefer VPN services that offer strong security, fast speeds, and reliable performance. Features such as a no-log policy, which means the VPN does not store user activity, are highly valued. Easy-to-use apps, support for multiple devices, and customer support also play a key role in choosing a VPN. Meanwhile, the trusted VPN providers focus on user privacy and provide consistent service across smartphones, laptops, and other devices. (Also Read: Apple’s iPhone 17 Pro With 48MP Triple Camera Gets Hefty Discount On THIS Platform; Check Display, Battery And Other Specs) How To Install VPN For Android Users Step 1: Open the Google Play Store on your Android phone and search for a trusted VPN app. Step 2: Install the VPN app by tapping the Install button and wait for the download to complete. Step 3: Open the app and sign up or log in using your email or existing account details. Step 4: Allow VPN connection permission when prompted, as this is required for the app to work. Step 5: Select a server location and tap Connect to activate the VPN on your device. How To Install VPN For iOS Users Step 1: Open the App Store on your iPhone or iPad and search for a trusted VPN app. Step 2: Download and install the app by tapping Get and completing Face ID, Touch ID, or password verification. Step 3: Launch the VPN app and sign up or log in using your email or existing account details. Step 4: Allow VPN configuration access when iOS asks for permission to add VPN settings. Step 5: Choose a server location and tap Connect to activate the VPN on your device. Conclusion As online risks continue to rise, staying safe on the internet has become more important than ever. Every click, message, and login carries personal information. A VPN helps protect this data quietly in the background. Whether it is for better privacy, stronger security, or access to global content, VPNs allow users to browse with confidence. Choosing the right VPN makes everyday internet use safer, smoother, and more private.

Apple’s iPhone 17 Pro With 48MP Triple Camera Gets Hefty Discount On THIS Platform; Check Display, Battery And Other Specs | Technology News
iPhone 17 Pro Discount Price In India: As 2025 gets closer to its end, the smartphone market is full of exciting deals. Among them, one phone that truly made a strong impact this year is the Apple iPhone 17 Pro. With its powerful performance and premium design, it stayed in the spotlight all year. Now, as people prepare to say goodbye to 2025, Vijay Sales is offering the iPhone 17 Pro (256 GB Variant) at a hefty discount, giving buyers a great chance to upgrade to Apple’s flagship smartphone. Notably, the smartphone is offered in three different colour options, which include Cosmic Orange, Deep Blue, and Silver. iPhone 17 Pro Discount Price The flagship smartphone is now available on Vijay Sales with a price cut that makes it more tempting for buyers. Originally priced at Rs 1,34,900, the phone is being sold at Rs 1,25,490 after a 7% discount of Rs 9,410. The savings do not stop there. Buyers using an ICICI Bank credit card can get an additional flat discount of Rs 5,000. This extra offer further reduces the final price to Rs 1,20,490, making the premium smartphone easier to buy for those looking for a good deal. (Also Read: New Year 2026 WhatsApp Scams: What Should You Do If Targeted? How To Identify And Stay Safe) Add Zee News as a Preferred Source iPhone 17 Pro Specifications The smartphone features a large 6.3-inch LTPO Super Retina XDR OLED display with a smooth 120Hz refresh rate and an impressive peak brightness of 3,000 nits for clear viewing even in bright light. It is powered by the Apple A19 Pro chipset, paired with a 6-core Apple GPU, delivering fast and reliable performance. The phone runs on iOS 26.2 with the new Liquid Glass theme for a refined user experience. It is powered by a 3,998mAh battery with 25W MagSafe wireless charging keeps it running. On the photography front, the smartphone offers a triple 48MP rear camera setup, including a primary sensor with sensor-shift OIS, an ultra-wide lens, and a periscope telephoto lens with 4x optical zoom, while an 18MP front camera handles selfies. Adding further, the iPhone 17 Pro comes with advanced security and sensor features, led by Face ID powered by TrueDepth technology built into the Center Stage front camera. It is equipped with a LiDAR scanner, barometer, high dynamic range gyro, high-g accelerometer, proximity sensor, and dual ambient light sensors for improved accuracy and performance. The device supports Dual SIM functionality with nano-SIM and eSIM options. For communication, it offers FaceTime audio, VoLTE, Wi-Fi calling, SharePlay, screen sharing, Spatial Audio, and Voice Isolation along with Wide Spectrum microphone modes for clearer calls.

Evaluating Perplexity on Language Models
A language model is a probability distribution over sequences of tokens. When you train a language model, you want to measure how accurately it predicts human language use. This is a difficult task, and you need a metric to evaluate the model. In this article, you will learn about the perplexity metric. Specifically, you will learn: What is perplexity, and how to compute it How to evaluate the perplexity of a language model with sample data Let’s get started. Evaluating Perplexity on Language ModelsPhoto by Lucas Davis. Some rights reserved. Overview This article is divided into two parts; they are: What Is Perplexity and How to Compute It Evaluate the Perplexity of a Language Model with HellaSwag Dataset What Is Perplexity and How to Compute It Perplexity is a measure of how well a language model predicts a sample of text. It is defined as the inverse of the geometric mean of the probabilities of the tokens in the sample. Mathematically, perplexity is defined as: $$PPL(x_{1:L}) = \prod_{i=1}^L p(x_i)^{-1/L} = \exp\big(-\frac{1}{L} \sum_{i=1}^L \log p(x_i)\big)$$ Perplexity is a function of a particular sequence of tokens. In practice, it is more convenient to compute perplexity as the mean of the log probabilities, as shown in the formula above. Perplexity is a metric that quantifies how much a language model hesitates about the next token on average. If the language model is absolutely certain, the perplexity is 1. If the language model is completely uncertain, then every token in the vocabulary is equally likely; the perplexity is equal to the vocabulary size. You should not expect perplexity to go beyond this range. Evaluate the Perplexity of a Language Model with HellaSwag Dataset Perplexity is a dataset-dependent metric. One dataset you can use is HellaSwag. It is a dataset with train, test, and validation splits. It is available on the Hugging Face hub, and you can load it with the following code: import datasets dataset = datasets.load_dataset(“HuggingFaceFW/hellaswag”) print(dataset) for sample in dataset[“validation”]: print(sample) break import datasets dataset = datasets.load_dataset(“HuggingFaceFW/hellaswag”) print(dataset) for sample in dataset[“validation”]: print(sample) break Running this code will print the following: DatasetDict({ train: Dataset({ features: [‘ind’, ‘activity_label’, ‘ctx_a’, ‘ctx_b’, ‘ctx’, ‘endings’, ‘source_id’, ‘split’, ‘split_type’, ‘label’], num_rows: 39905 }) test: Dataset({ features: [‘ind’, ‘activity_label’, ‘ctx_a’, ‘ctx_b’, ‘ctx’, ‘endings’, ‘source_id’, ‘split’, ‘split_type’, ‘label’], num_rows: 10003 }) validation: Dataset({ features: [‘ind’, ‘activity_label’, ‘ctx_a’, ‘ctx_b’, ‘ctx’, ‘endings’, ‘source_id’, ‘split’, ‘split_type’, ‘label’], num_rows: 10042 }) }) {‘ind’: 24, ‘activity_label’: ‘Roof shingle removal’, ‘ctx_a’: ‘A man is sitting on a roof.’, ‘ctx_b’: ‘he’, ‘ctx’: ‘A man is sitting on a roof. he’, ‘endings’: [ ‘is using wrap to wrap a pair of skis.’, ‘is ripping level tiles off.’, “is holding a rubik’s cube.”, ‘starts pulling up roofing on a roof.’ ], ‘source_id’: ‘activitynet~v_-JhWjGDPHMY’, ‘split’: ‘val’, ‘split_type’: ‘indomain’, ‘label’: ‘3’} 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 DatasetDict({ train: Dataset({ features: [‘ind’, ‘activity_label’, ‘ctx_a’, ‘ctx_b’, ‘ctx’, ‘endings’, ‘source_id’, ‘split’, ‘split_type’, ‘label’], num_rows: 39905 }) test: Dataset({ features: [‘ind’, ‘activity_label’, ‘ctx_a’, ‘ctx_b’, ‘ctx’, ‘endings’, ‘source_id’, ‘split’, ‘split_type’, ‘label’], num_rows: 10003 }) validation: Dataset({ features: [‘ind’, ‘activity_label’, ‘ctx_a’, ‘ctx_b’, ‘ctx’, ‘endings’, ‘source_id’, ‘split’, ‘split_type’, ‘label’], num_rows: 10042 }) }) {‘ind’: 24, ‘activity_label’: ‘Roof shingle removal’, ‘ctx_a’: ‘A man is sitting on a roof.’, ‘ctx_b’: ‘he’, ‘ctx’: ‘A man is sitting on a roof. he’, ‘endings’: [ ‘is using wrap to wrap a pair of skis.’, ‘is ripping level tiles off.’, “is holding a rubik’s cube.”, ‘starts pulling up roofing on a roof.’ ], ‘source_id’: ‘activitynet~v_-JhWjGDPHMY’, ‘split’: ‘val’, ‘split_type’: ‘indomain’, ‘label’: ‘3’} You can see that the validation split has 10,042 samples. This is the dataset you will use in this article. Each sample is a dictionary. The key “activity_label” describes the activity category, and the key “ctx” provides the context that needs to be completed. The model is expected to complete the sequence by selecting one of the four endings. The key “label”, with values 0 to 3, indicates which ending is correct. With this, you can write a short code to evaluate your own language model. Let’s use a small model from Hugging Face as an example: import datasets import torch import torch.nn.functional as F import tqdm import transformers model = “openai-community/gpt2″ # Load the model torch.set_default_device(“cuda” if torch.cuda.is_available() else “cpu”) tokenizer = transformers.AutoTokenizer.from_pretrained(model) model = transformers.AutoModelForCausalLM.from_pretrained(model) # Load the dataset: HellaSwag has train, test, and validation splits dataset = datasets.load_dataset(“hellaswag”, split=”validation”) # Evaluate the model: Compute the perplexity of each ending num_correct = 0 for sample in tqdm.tqdm(dataset): # tokenize text from the sample text = tokenizer.encode(” ” + sample[“activity_label”] + “. ” + sample[“ctx”]) endings = [tokenizer.encode(” ” + x) for x in sample[“endings”]] # 4 endings groundtruth = int(sample[“label”]) # integer, 0 to 3 # generate logits for each ending perplexities = [0.0] * 4 for i, ending in enumerate(endings): # run the entire input and ending to the model input_ids = torch.tensor(text + ending).unsqueeze(0) output = model(input_ids).logits # extract the logits for each token in the ending logits = output[0, len(text)-1:, :] token_probs = F.log_softmax(logits, dim=-1) # accumulate the probability of generating the ending log_prob = 0.0 for j, token in enumerate(ending): log_prob += token_probs[j, token] # convert the sum of log probabilities to perplexity perplexities[i] = torch.exp(-log_prob / len(ending)) # print the perplexity of each ending print(sample[“activity_label”] + “. ” + sample[“ctx”]) correct = perplexities[groundtruth] == min(perplexities) for i, p in enumerate(perplexities): if i == groundtruth: symbol=”(O)” if correct else ‘(!)’ elif p == min(perplexities): symbol=”(X)” else: symbol=” “ print(f”Ending {i}: {p:.4g} {symbol} – {sample[‘endings’][i]}”) if correct: num_correct += 1 print(f”Accuracy: {num_correct}/{len(dataset)} = {num_correct / len(dataset):.4f}”) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49

Practical Agentic Coding with Google Jules
Practical Agentic Coding with Google JulesImage by Editor Introducing Google Jules If you have an interest in agentic coding, there’s a pretty good chance you’ve heard of Google Jules by now. But if not, now’s the time to learn all about it. Jules is an autonomous, asynchronous agentic coding assistant developed by Google DeepMind, which harnesses the Gemini family of models and is designed to integrate directly with existing code repositories and autonomously perform development tasks. You can think of Jules as your highly specialized, off-site dev contractor. Jules isn’t meant to be used by you or your team directly from within your local IDE. Instead, you hand over your entire GitHub repo to this contractor — I know, I know… unnerving. Jules then takes and securely duplicates the repo in an isolated cloud virtual machine (VM), where it studies the entire project under the guidance of its expert programming knowledge — gained from Gemini 3 (for paying customers; Gemini 2.5 — with usage limits — otherwise). It then drafts a detailed plan, executes on the modification requests, test those changes, and finally submits a pull request for your inspection and approval. It also uses files like README.md or AGENTS.md for project context and environment hints. This pipeline allows you to delegate complex coding and development tasks without having Jules interfere with your daily work, ensuring safety and quality control. Let’s summarize the important points of how Jules operates: Autonomous, agentic operation: Jules is genuinely an autonomous agent that reads code and understands intent, moving beyond the role of a co-pilot or code-completion sidekick. It is truly an agentic service designed for work delegation, allowing users to outsource explicit instructions for tasks like improving test coverage or performing surgical code modernizations. Asynchronous workflow: Jules operates asynchronously in the background inside a cloud VM. This allows developers to focus on other tasks while it toils away. This non-blocking approach lets you assign a task and move on to other work inside the codebase yourself, avoiding interruptions to your immediate flow. Comprehensive codebase context: Jules isn’t about code snippets. It analyzes complex, multi-file projects and aims to understand the full context of your existing codebase to intelligently reason about changes. This ability is necessary for handling complex, multi-step operations within full repositories. Audio changelogs and summaries: Jules is able to provide audio summaries of recent commits (an audio changelog), transforming the project history into a contextual changelog that users can listen to. Do you like NotebookLM’s audio overviews? Jules brings that sensibility to your codebase. When it comes to interacting with Jules, you have a few options. First, the Jules tools CLI is a command-line interface (featuring the jules command) that allows developers to interact with the agent from their terminal. This enables scripting and automation, and facilitates piping output from other CLI tools, such as sending your repos issue list directly to Jules (gh issue list) or extract a list of tasks from jq and pipe it directly to the CLI to create new tasks for the agent. There is also the Jules API, which allows for deeper customization via programmatic access. With the API, you can integrate more tools and services such as Slack or Jira, which allows you to message tasks to Jules or assigning tickets to it, respectively, automating bug fixing, feature implementation, and CI/CD pipelines. Add the triggering capabilties from Github issues directly and you have a robust set of approaches for engaging with your agentic development workflow. Using Google Jules with an Existing GitHub Repository The process for using Google Jules generally involves initial setup, task prompting, and subsequent human review and approval. Let’s do a quick walkthrough using a toy repo of mine. Step 1: Initial Access and Authentication Visit the official Google Jules website and click “Try Jules”. Authenticate using your Google account and accept the privacy notice. Authenticate to “Try Jules” Once authenticated, your screen should look like this: Step 2: Connect to GitHub Click “Connect to GitHub Account” and select the specific repositories where you want to allow Jules to access. Connect to GitHub to reap the rewards Step 3: Select Repository and Branch Once set up, select the target repository and branch from the Jules dashboard or selector. Select the target repository and branch I have selected a simple key/value database implemented in Java that only leverages the language’s built-in data structures. Step 4: Prompt the Task Write your prompt detailing the required task (e.g. code refactoring, bug fixing, generating unit tests). Tasks can also be triggered via a GitHub issue or label. Jules is recommended for explicit instructions that can drive unattended batch work against source code in GitHub.com. Prompt the required task in detail Here we will see how Jules does at converting the codebase from Java to Python. Step 5: Generate, Review and Approve the Plan Click Give me a plan. Jules will analyze the codebase and query, derive a detailed plan, and list the affected files. You can modify the presented plan before, during, and after execution. After reviewing the proposed plan and reasoning, approve it by clicking Approve plan to begin implementation. I selected the option to submit and run the task without a formal approval process, given the light work I am asking of Jules. Step 6: Execution and Verification Jules clones the repository into its secure cloud VM environment, applies all the changes, runs relevant test cases, and captures the differences. Google Jules toils away while I do something else Step 7: Review Changes and Publish Finally, it’s time to review the implemented changes (the diff). Reviewing the changes that Google Jules implemented Upon approval, click Publish branch. Jules publishes the feature branch in the original repository and automatically opens a pull request targeting the main branch for final merging. Inspecting the pull request that Jules creates Of course, it’s great that Jules does all of this, but does it work? I downloaded the generated code and ran it to test. Looks good

Instagram Hit By Brief Outage; Several Users Report Login And App Issues On Meta-Owned Platform, Netizens React | Technology News
Instagram Outage: Instagram users faced an unexpected disruption early Sunday as the Meta-owned platform suffered a brief outage, mainly affecting users in the United States. According to outage-tracking website Downdetector, complaints peaked around 4:10 a.m. EST, when more than 180 users reported problems accessing the popular photo and video-sharing app. Several users said they were unable to log in or load content during the outage. Frustrated users took to other social media platforms to share screenshots of the issue, which showed a blank screen with a circular refresh icon and no clear error message. Instagram Outage: Downdetector Data Add Zee News as a Preferred Source Downdetector data showed that 45 per cent of affected users reported app-related issues, while 41 per cent faced login problems. Another 14 per cent said their feed or timeline was not loading properly. The outage appeared to have a limited impact in India. According to Downdetector, only about 10 users in the country reported issues accessing Instagram, suggesting the problem was largely confined to certain regions. Meta Official Statement Awaited Meta has not issued any official statement explaining the reason behind the outage or how long the disruption lasted. As Instagram went down, social media platforms were quickly flooded with user reactions. One user asked, “Is Insta down?” while another joked, “Jimin really got that Insta baddie aesthetic down.” Netizens Reaction #instagramdown is this happening to anyone else ?? pic.twitter.com/nUZ8fjP9EV (@xoxolillyy_) December 28, 2025 Ilhan Omar’s daughter posted on Instagram, wishing death to the “colonial empire from LA to Rafah.” She’s just saying what Ilhan’s too scared to admit: they hate the United States and want to burn it down—and they’re not even hiding it anymore. pic.twitter.com/RmfpgpH6SZ — Eyal Yakoby (@EYakoby) December 27, 2025 Instagram down? Unable to upload, keeps getting stuck and repeating the cycle.. worse when you’ve got deadlines ffs pic.twitter.com/6zGY0PJvr9 — J.E. (@JackEmson99) December 24, 2025 Yes. It has happened again. Instagram is down. And now everyone is on twitter. #instagramdown pic.twitter.com/n7lM4SI6Xv — Amit. (@iiamitverma) February 26, 2025 This is not the first time a Meta-owned platform has faced technical issues. Earlier this year, WhatsApp experienced multiple outages that affected users worldwide, including in India. In one such incident in September, thousands of users were unable to send messages or upload status updates, leading to widespread complaints across social media. (With IANS Inputs)

Google Chrome Extension For Cryptocurrency Binance-Owned Trust Wallet Hacked; Users Lose Rs 58,00,00,000; Here’s How to Ensure Security And Stay Safe | Technology News
Google Chrome Extension Hacked: A malicious security breach hit Binance-owned Trust Wallet. Hackers stole more than $7 million (approx Rs 58,00,00,000) by draining funds from some user wallets. The problem was linked to Trust Wallet’s Google Chrome extension. After the incident, Binance co-founder Changpeng Zhao said that affected users will get their money back. He shared this update on social media platform X (formerly Twitter) and said the company will step in to limit the damage. However, two days later on Saturday, Trust Wallet CEO Eowyn Chen shared a detailed update on X (formerly Twitter). She explained how the incident happened, the steps taken to stop the attack, and what the company has learned so far from its investigation. Trust Wallet Breach Affected Only Select Users Add Zee News as a Preferred Source According to Trust Wallet CEO Eowyn Chen, the investigation has found that the security issue only affected users who opened and logged into Trust Wallet’s Browser Extension version 2.68. Adding further, she also noted that the breach does not affect any mobile app users, any other versions of browser extension users, as well as extension v2.68 users who opened and logged in after 26 December, 11:00 UTC. Hence, all these users remain unaffected by the incident and their accounts, data, and assets are considered secure. Trust Wallet Breach Affected: What Steps Company Has Taken To limit the impact of the incident, the company has taken a few steps. The harmful website linked to the attack has been reported to the domain registrar, NiceNIC, and has now been blocked. This means users who are still using Extension version 2.68 are safe from any further loss. The company has also stopped all new releases by closing its release APIs for the next two weeks. At the same time, Trust Wallet has started collecting reports from affected users and is working on refunds. Some parts of the refund process are still being worked out. Trust Wallet Breach: How To Ensure Security And Stay Safe Step 1: Do not open the Trust Wallet Browser Extension on your desktop to keep your wallet safe and avoid further risks. Step 2: Open Chrome Extensions by pasting this link into your browser’s address bar: chrome://extensions/?id=egjidjbpglichdcondbcbdnbeeppgdph. Step 3: Find Trust Wallet and turn the toggle Off if it is still enabled. Step 4: Enable Developer mode by clicking the option in the top-right corner of the page. Step 5: Click the Update button that appears in the top-left corner to refresh the extension. Step 6: Check the extension version and make sure it shows version 2.69, which is the latest and secure version.
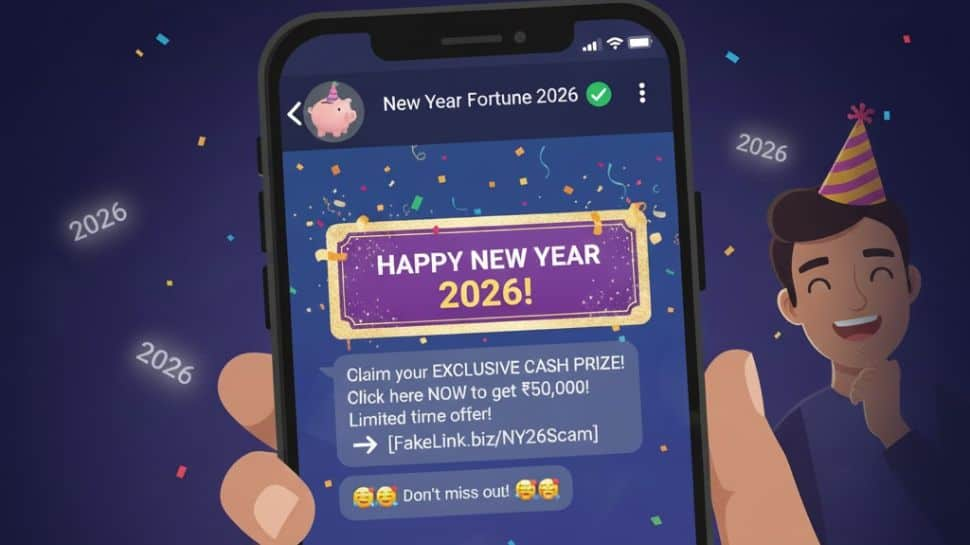
New Year 2026 WhatsApp Scams: What Should You Do If Targeted? How To Identify And Stay Safe | Technology News
New Year 2026 WhatsApp Scams: As New Year 2026 gets closer, phones start buzzing with wishes, messages and celebration plans. While most of these messages bring joy, some hide a serious risk. Cyber experts warn that scammers are becoming more active on WhatsApp during the festive season. They use fake offers, links and messages to trick users. Since millions of people use WhatsApp to greet friends and family at this time, fraudsters see it as an easy chance to target and trap unsuspecting users. Why Do WhatsApp Scams Increase Around New Year? Cybersecurity experts say scammers take advantage of excitement and reduced alertness during festivals. People expect gifts, discounts and surprise messages at this time. Fraudsters use brand names, emotional language and urgent warnings to make fake messages look genuine and push users to act without checking. Add Zee News as a Preferred Source What Are the Most Common New Year WhatsApp Scams? One of the most reported scams involves fake New Year rewards or gift offers. Messages claim users have won cashback, vouchers or prizes and ask them to click a link. These links usually lead to fake websites that steal personal or banking information. Another common method is fake party invites or event passes. These messages contain short or unknown links that may install harmful software on the phone or redirect users to unsafe websites. Scammers also circulate New Year greeting images or videos. Though they appear harmless, downloading such files can infect devices with malware that silently steals data. A serious threat is WhatsApp account takeover scams. In these cases, fraudsters ask users to share the six-digit OTP, claiming it is needed for verification. Once shared, scammers gain full access to the account and use it to cheat others. How Can Users Identify WhatsApp Scams? Experts say scam messages often share common signs. They create urgency, promise big rewards, or ask for immediate action. Messages from unknown numbers, spelling mistakes, strange links, or requests for OTPs, PINs or bank details should be treated as red flags. Legitimate companies and WhatsApp do not ask for such information through messages. How Can Users Stay Safe? Users are advised not to click on unknown links or download files from unverified sources. Enabling two-step verification adds an extra layer of security to WhatsApp accounts. Offers should always be checked on official websites or apps. Suspicious messages should be reported and blocked using WhatsApp’s reporting feature. This helps prevent scams from spreading further. What Should You Do If You Are Targeted? If an account is compromised, users should immediately contact WhatsApp support and alert their bank if financial details were shared. Quick action can help reduce losses. (Also Read: Want To Change Your Gmail Address Name Without Losing Data? Here’s How To Do It And Check Limitations) New Year 2026 WhatsApp Scams: Conclusion As we inch closer to celebrate new beginnings, staying alert online is just as important as celebrating safely offline. WhatsApp scams thrive on excitement and quick reactions, but a little caution can go a long way. Avoid clicking on unknown links, never share OTPs or personal details, and always verify offers before acting. By staying calm, informed and alert, users can protect themselves from scams and welcome the New Year without unwanted trouble.

Training a Model with Limited Memory using Mixed Precision and Gradient Checkpointing
Training a language model is memory-intensive, not only because the model itself is large but also because the long sequences in the training data batches. Training a model with limited memory is challenging. In this article, you will learn techniques that enable model training in memory-constrained environments. In particular, you will learn about: Low-precision floating-point numbers and mixed-precision training Using gradient checkpointing Let’s get started! Training a Model with Limited Memory using Mixed Precision and Gradient CheckpointingPhoto by Meduana. Some rights reserved. Overview This article is divided into three parts; they are: Floating-point Numbers Automatic Mixed Precision Training Gradient Checkpointing Let’s get started! Floating-Point Numbers The default data type in PyTorch is the IEEE 754 32-bit floating-point format, also known as single precision. It is not the only floating-point type you can use. For example, most CPUs support 64-bit double-precision floating-point, and GPUs often support half-precision floating-point as well. The table below lists some floating-point types: Data Type PyTorch Type Total Bits Sign Bit Exponent Bits Mantissa Bits Min Value Max Value eps IEEE 754 double precision torch.float64 64 1 11 52 -1.79769e+308 1.79769e+308 2.22045e-16 IEEE 754 single precision torch.float32 32 1 8 23 -3.40282e+38 3.40282e+38 1.19209e-07 IEEE 754 half precision torch.float16 16 1 5 10 -65504 65504 0.000976562 bf16 torch.bfloat16 16 1 8 7 -3.38953e+38 3.38953e+38 0.0078125 fp8 (e4m3) torch.float8_e4m3fn 8 1 4 3 -448 448 0.125 fp8 (e5m2) torch.float8_e5m2 8 1 5 2 -57344 57344 0.25 fp8 (e8m0) torch.float8_e8m0fnu 8 1 8 0 1.70141e+38 5.87747e-39 1.0 fp6 (e3m2) 6 1 3 2 -28 28 0.25 fp6 (e2m3) 6 1 2 3 -7.5 7.5 0.125 fp4 (e2m1) 4 1 2 1 -6 6 Floating-point numbers are binary representations of real numbers. Each consists of a sign bit, several bits for the exponent, and several bits for the mantissa. They are laid out as shown in the figure below. When sorted by their binary representation, floating-point numbers retain their order by real-number value. Floating-point number representation. Figure from Wikimedia. Different floating-point types have different ranges and precisions. Not all types are supported by all hardware. For example, fp4 is only supported in Nvidia’s Blackwell architecture. PyTorch supports only a few data types. You can run the following code to print information about various floating-point types: import torch from tabulate import tabulate # float types: float_types = [ torch.float64, torch.float32, torch.float16, torch.bfloat16, torch.float8_e4m3fn, torch.float8_e5m2, torch.float8_e8m0fnu, ] # collect finfo for each type table = [] for dtype in float_types: info = torch.finfo(dtype) try: typename = info.dtype except: typename = str(dtype) table.append([typename, info.max, info.min, info.smallest_normal, info.eps]) headers = [‘data type’, ‘max’, ‘min’, ‘smallest normal’, ‘eps’] print(tabulate(table, headers=headers)) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 import torch from tabulate import tabulate # float types: float_types = [ torch.float64, torch.float32, torch.float16, torch.bfloat16, torch.float8_e4m3fn, torch.float8_e5m2, torch.float8_e8m0fnu, ] # collect finfo for each type table = [] for dtype in float_types: info = torch.finfo(dtype) try: typename = info.dtype except: typename = str(dtype) table.append([typename, info.max, info.min, info.smallest_normal, info.eps]) headers = [‘data type’, ‘max’, ‘min’, ‘smallest normal’, ‘eps’] print(tabulate(table, headers=headers)) Pay attention to the min and max values for each type, as well as the eps value. The min and max values indicate the range a type can support (the dynamic range). If you train a model with such a type, but the model weights exceed this range, you will get overflow or underflow, usually causing the model to output NaN or Inf. The eps value is the smallest positive number such that the type can differentiate between 1+eps and 1. This is a metric for precision. If your model’s gradient updates are smaller than eps, you will likely observe the vanishing gradient problem. Therefore, float32 is a good default choice for deep learning: it has a wide dynamic range and high precision. However, each float32 number requires 4 bytes of memory. As a compromise, you can use float16 to save memory, but you are likely to encounter overflow or underflow issues since the dynamic range is much smaller. The Google Brain team identified this problem and proposed bfloat16, a 16-bit floating-point format with the same dynamic range as float32. As a trade-off, the precision is an order of magnitude worse than float16. It turns out that dynamic range is more important than precision for deep learning, making bfloat16 highly useful. When you create a tensor in PyTorch, you can specify the data type. For example: x = torch.tensor([1.0, 2.0, 3.0], dtype=torch.float16) print(x) x = torch.tensor([1.0, 2.0, 3.0], dtype=torch.float16) print(x) There is a straightforward way to change the default to a different type, such as bfloat16. This is handy for model training. All you need to do is set the following line before you create any model or optimizer: # set default dtype to bfloat16 torch.set_default_dtype(torch.bfloat16) # set default dtype to bfloat16 torch.set_default_dtype(torch.bfloat16) Just by doing this, you force all your model weights and gradients to be bfloat16 type. This saves half of the memory. In the previous article, you were advised to set the batch size to 8 to fit a GPU with only 12GB of VRAM. With bfloat16, you should be able to set the batch size to 16. Note that attempting to use 8-bit float or lower-precision types may not work. This is because you need hardware support and PyTorch to perform the corresponding mathematical operations. You can try the following code (requires a CUDA device) and find that you will need extra effort to operate on 8-bit float: dtype = torch.float8_e4m3fn # Define a tensor with float8 will see # NotImplementedError: “normal_kernel_cuda” not implemented for ‘Float8_e4m3fn’ x = torch.randn(16, 16, dtype=dtype, device=”cuda”) # Create in float32 and convert to float8 works x = torch.randn(16, 16, device=”cuda”).to(dtype) # But matmul is not supported. You will see # NotImplementedError: “addmm_cuda” not implemented for ‘Float8_e4m3fn’ y = x @ x.T # The correct way to run matrix



