

BSNL Wi-Fi Calling Service Price In India: On New Year, state-owned telecom operator Bharat Sanchar Nigam Limited (BSNL) rolled out its Voice over Wi-Fi (VoWiFi) service across all telecom circles in India. The advanced service, also known as Wi-Fi Calling, is now available to BSNL customers nationwide. It enables seamless and high-quality voice connectivity even in areas with poor network coverage. With this launch, the state-owned telecom service provider (TSP) aims to compete with private players such as Airtel and Jio, which have been offering VoWiFi services for several years. Notably, BSNL users do not need to download or install any application to use the VoWiFi service. BSNL VoWiFi Service: What’s New Add Zee News as a Preferred Source VoWiFi is an IMS-based service that supports seamless handovers between Wi-Fi and mobile networks. The advanced service allows customers to make and receive voice calls and messages over a Wi-Fi network. This technology ensures clear and reliable connectivity in areas with weak mobile signals, such as homes, offices, basements, and remote locations. It leverages a stable Wi-Fi connection, including BSNL Bharat Fibre and other broadband services. (Also Read: Moto G-Series Smartphone Users Alarmed After Device Reportedly Bursts Into Flames; User Slams Nehru Place Service Centre | Viral Video) BSNL VoWiFi Service: Beneficial For Remote Areas The service is especially useful in rural and remote areas where mobile network coverage is weak, provided a stable Wi-Fi connection such as BSNL Bharat Fibre or any other broadband service is available. VoWiFi also helps reduce network congestion and is available free of cost, with no extra charges for making Wi-Fi calls. BSNL announces nationwide rollout of Voice over WiFi ( VoWifi) !! When mobile signal disappears, BSNL VoWiFi steps in. Make uninterrupted voice calls over Wi-Fi on your same BSNL number anytime, anywhere. Now live across India for all BSNL customers, Because conversations… pic.twitter.com/KPUs79Lj9w — BSNL India (@BSNLCorporate) January 1, 2026 BSNL VoWiFi Service: Price And How To Activate VoWiFi is offered free of cost, with no additional charges for Wi-Fi calls, and is supported on most modern smartphones. To use the service, customers simply need to enable the Wi-Fi Calling option in their smartphone settings. For assistance with device compatibility or activation, users can visit the nearest BSNL customer service centre or contact the BSNL customer care helpline at 1800-1503. BSNL 5G Service State-run Bharat Sanchar Nigam Limited (BSNL) plans to roll out 23,000 additional 4G sites across India and upgrade its network to 5G technology. The telecom operator will use a revenue-sharing model to strengthen its services and better compete with private telecom players.

Gradient Descent:The Engine of Machine Learning Optimization
Gradient Descent: Visualizing the Foundations of Machine LearningImage by Author Editor’s note: This article is a part of our series on visualizing the foundations of machine learning. Welcome to the first entry in our series on visualizing the foundations of machine learning. In this series, we will aim to break down important and often complex technical concepts into intuitive, visual guides to help you master the core principles of the field. Our first entry focuses on the engine of machine learning optimization: gradient descent. The Engine of Optimization Gradient descent is often considered the engine of machine learning optimization. At its core, it is an iterative optimization algorithm used to minimize a cost (or loss) function by strategically adjusting model parameters. By refining these parameters, the algorithm helps models learn from data and improve their performance over time. To understand how this works, imagine the process of descending the mountain of error. The goal is to find the global minimum, which is the lowest point of error on the cost surface. To reach this nadir, you must take small steps in the direction of the steepest descent. This journey is guided by three main factors: the model parameters, the cost (or loss) function, and the learning rate, which determines your step size. Our visualizer highlights the generalized three-step cycle for optimization: Cost function: This component measures how “wrong” the model’s predictions are; the objective is to minimize this value Gradient: This step involves calculating the slope (the derivative) at the current position, which points uphill Update parameters: Finally, the model parameters are moved in the opposite direction of the gradient, multiplied by the learning rate, to move closer to the minimum Depending on your data and computational needs, there are three primary types of gradient descent to consider. Batch GD uses the entire dataset for each step, which is slow but stable. On the other end of the spectrum, stochastic GD (SGD) uses just one data point per step, making it fast but noisy. For many, mini-batch GD offers the best of both worlds, using a small subset of data to achieve a balance of speed and stability. Gradient descent is crucial for training neural networks and many other machine learning models. Keep in mind that the learning rate is a critical hyperparameter that dictates success of the optimization. The mathematical foundation follows the formula \[\theta_{new} = \theta_{old} – a \cdot \nabla J(\theta),\] where the ultimate goal is to find the optimal weights and biases to minimize error. The visualizer below provides a concise summary of this information for quick reference. Gradient Descent: Visualizing the Foundations of Machine Learning (click to enlarge)Image by Author You can click here to download a PDF of the infographic in high resolution. Machine Learning Mastery Resources These are some selected resources for learning more about gradient descent: Gradient Descent For Machine Learning – This beginner-level article provides a practical introduction to gradient descent, explaining its fundamental procedure and variations like stochastic gradient descent to help learners effectively optimize machine learning model coefficients.Key takeaway: Understanding the difference between batch and stochastic gradient descent. How to Implement Gradient Descent Optimization from Scratch – This practical, beginner-level tutorial provides a step-by-step guide to implementing the gradient descent optimization algorithm from scratch in Python, illustrating how to navigate a function’s derivative to locate its minimum through worked examples and visualizations.Key takeaway: How to translate the logic into a working algorithm and how hyperparameters affect results. A Gentle Introduction To Gradient Descent Procedure – This intermediate-level article provides a practical introduction to the gradient descent procedure, detailing the mathematical notation and providing a solved step-by-step example of minimizing a multivariate function for machine learning applications.Key takeaway: Mastering the mathematical notation and handling complex, multi-variable problems. Be on the lookout for for additional entries in our series on visualizing the foundations of machine learning. About Matthew Mayo Matthew Mayo (@mattmayo13) holds a master’s degree in computer science and a graduate diploma in data mining. As managing editor of KDnuggets & Statology, and contributing editor at Machine Learning Mastery, Matthew aims to make complex data science concepts accessible. His professional interests include natural language processing, language models, machine learning algorithms, and exploring emerging AI. He is driven by a mission to democratize knowledge in the data science community. Matthew has been coding since he was 6 years old.
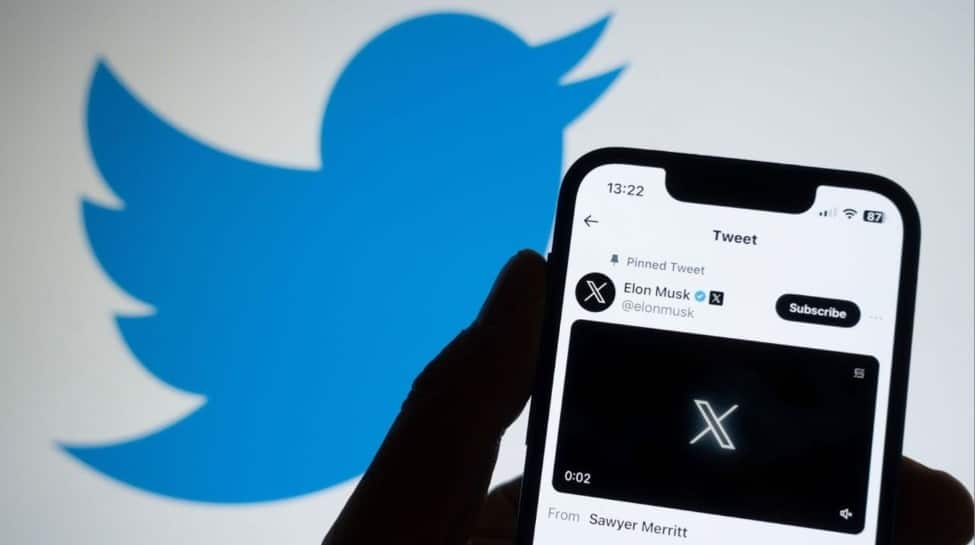
Centre Cracks Down On X Over Grok AI Misuse; Issues 72-Hour Ultimatum To Remove Obscene Content | India News
The Ministry of Electronics and Information Technology (MeitY) issued a warning to the Elon Musk-owned social media platform X (formerly Twitter) to take immediate steps to disable all “obscene, nude, indecent, and sexually explicit” content created by the AI-powered tool named Grok on the platform. The government has given the platform an ultimatum of 72 hours to submit its Action Taken Report (ATR), failing which the platform will face severe legal action and will also lose its “safe harbour” protection under Section 79 of the Information Technology Act. Grok Artificial Intelligence Misused To Target Women Add Zee News as a Preferred Source This is due to the misuse of the Grok AI facility, reported by the Centre. A four-page letter was written to the Chief Compliance Officer of X, indicating that users are creating fake accounts to host derogatory images and videos of women. The letter pointed out that it is noticed that this tool is being forced to “minimise clothing” and thereby sexualise women in the picture, which actually constitutes a grave disregard for their dignity and privacy. I would take this opportunity to thank Hon IT Minister for promptly taking note of my letter and for issuing a letter to X platform in the regard of AI led grok generating problematic content of women based on prompts that disrespect woman’s dignity and violates their consent,… pic.twitter.com/kEb1HameMn — Priyanka Chaturvedi (@priyankac19) January 2, 2026 Statutory Lapses And Legal Warnings The ministry pointed out the failure of X to abide by its statutory duty of due diligence as prescribed in the Information Technology Act, 2000, and the IT Rules, 2021. Safe Harbour in Jeopardy: Non-compliance could lead to X losing its safe harbour status, which would put it at risk to be held responsible for all third-party content that is currently published on its service. Broad Legal Action: The government issued a warning of legal action in relation to the Bharatiya Nyaya Sanhita (BNS), the Indecent Representation of Women Act, and the POCSO Act (in cases of children). Holistic Security Review Required Besides the initial removal, the Centre has also asked X to conduct an urgent technical and governance-based review of Grok. These include: Examination of Grok’s architecture design, including its structure Prompt Filtering: Enhancing protections against the production of offensive or illegal synthetic media. Accountability: Disciplinary action, like permanent suspension, against violators who misuse the AI tool. Evidence Preservation: Blocking access to illegal material without “vitiating the evidence” that might be relevant to possible criminal proceedings. Wider Crackdown On Digital Obscenity This action has been preceded by another letter, this time from an MP in the Rajya Sabha named Priyanka Chaturvedi, to IT Minister Ashwini Vaishnaw, pointing out the growing trend of “digital undressing” practices against women on this platform. VIDEO | Mumbai: Shiv Sena (UBT) MP Priyanka Chaturvedi says, “There is an AI tool on the platform X, previously known as Twitter, which is being misused. When women share photographs on social media, especially on X, people are prompting this AI tool to digitally disrobe them,… pic.twitter.com/lS637WSSr9 — Press Trust of India (@PTI_News) January 2, 2026 IT Minister Vaishwani again emphasised on Friday that social networking sites bear responsibility for content on their platforms and that “intervention” was also necessary to provide all users with a trustworthy internet. ALSO READ | Mexico Earthquake Today: 6.5 Magnitude Quake Hits Guerrero; President Sheinbaum Evacuates Briefing | SHOCKING VIDEOS

Samsung Galaxy S26 Series Leaks Reveal New Camera Island Design And Upgrades: Check Expected Key Specs | Technology News
Samsung Galaxy S26 Series: Leaks surrounding Samsung’s upcoming Galaxy S26 series have started surfacing ahead of its expected launch in early 2026. According to recent reports, the new lineup will include three models — Galaxy S26, Galaxy S26+, and Galaxy S26 Ultra. These smartphones are expected to succeed the Galaxy S25 series and bring design refinements, upgraded processors, and improved cameras. Design and Build Details Leaked images of the Galaxy S26 and Galaxy S26 Ultra show the phones in black and white colour options. Both models appear to feature a flat rear panel and a flat metal frame. The standard Galaxy S26 is seen with a pill-shaped camera module with three lenses, while the Ultra variant appears to feature a more complex rear layout with two additional lenses placed outside the main camera island. Add Zee News as a Preferred Source The bottom edge of the devices is reportedly equipped with the USB Type-C port, speaker grille, microphone, and SIM tray. Samsung #GalaxyS26Ultra pic.twitter.com/0lzaFIxYev —Steve H.McFly (OnLeaks) December 30, 2025 Expected Display and Performance According to reports, the Galaxy S26 Ultra will feature a 6.9-inch QHD Samsung M14 OLED display, while the Galaxy S26+ may offer a 6.7-inch version of the same panel. The standard Galaxy S26 is expected to come with a 6.3-inch QHD OLED display. All three models are likely to support advanced display features and high refresh rates. In terms of performance, the Galaxy S26 series is expected to use Samsung’s upcoming Exynos 2600 chipset in select regions, while other markets may receive Qualcomm’s Snapdragon 8 Elite Gen 5 processor. The phones are also tipped to run Android 16 with One UI 8.5. (Also Read: Realme 16 Pro Series India Launch Confirmed: Check Expected Prices, Colours, And Key Specs) Expected Camera and Battery The Galaxy S26 Ultra is expected to feature a quad-camera setup, led by a 200-megapixel primary sensor, alongside a 50-megapixel ultra-wide lens, a 12-megapixel telephoto lens with 3x zoom, and a 50-megapixel periscope camera offering 5x optical zoom. The Galaxy S26 and S26+ are likely to come with triple-camera systems, including a 50-megapixel main sensor. The Ultra model is expected to come with a 5,400mAh battery with support for 60W fast charging. Expected Launch Timeline Samsung is yet to officially confirm the Galaxy S26 series, but reports suggest the lineup could debut in February 2026, with sales possibly beginning in March.

Realme 16 Pro Series India Launch Confirmed: Check Expected Prices, Colours, And Key Specs | Technology News
Realme 16 Pro: The Realme 16 Pro series is set to launch in India in the first week of January 2026, and ahead of the official announcement, details about its pricing and variants have surfaced online. The lineup includes the Realme 16 Pro 5G and the Realme 16 Pro+ 5G, along with the upcoming Realme Pad 3 5G. While Realme has confirmed the launch date, pricing details are yet to be officially announced. Leaked Prices and Storage Variants According to information shared by tech blogger Paras Guglani, the Realme 16 Pro 5G is expected to start at Rs 31,999 for the base variant with 8GB RAM and 128GB storage. The 8GB RAM + 256GB storage model will likely cost Rs 33,999, while the top variant with 12GB RAM and 256GB storage may be priced at Rs 36,999. Add Zee News as a Preferred Source For the Realme 16 Pro+ 5G, the leaked pricing suggests a starting price of Rs 39,999 for the 8GB RAM + 128GB storage version. The 8GB RAM + 256GB variant is expected to be priced at Rs 41,999, while the top-end model with 12GB RAM and 256GB storage could cost Rs 44,999. Reports also suggest that buyers may receive additional merchandise when purchasing the phone offline. (Also Read: New Year’s Eve Tech Tip: How You Place Your Smartphone On Table Can Improve Privacy, Focus, Battery, And Mental Peace-Explained) Launch Timeline and Availability The Realme 16 Pro series is scheduled to launch in India on January 6, 2026. The smartphones will be sold through Flipkart and the Realme India online store. They will be available in Master Gold and Master Grey colour options and feature the brand’s new “Urban Wild” design language. Key Specifications Both smartphones in the series are confirmed to feature a large 7,000mAh Titan battery. The camera setup will include a LumaColor Image-powered triple rear camera system, led by a 200-megapixel primary sensor. The Realme 16 Pro+ 5G will be powered by the Snapdragon 7 Gen 4 chipset, while the Realme 16 Pro 5G will use the MediaTek Dimensity 7300-Max processor. As of now, Realme has not officially confirmed the leaked prices, and the final details are expected to be revealed at the official launch event.

Train Your Large Model on Multiple GPUs with Tensor Parallelism
import dataclasses import datetime import os import datasets import tokenizers import torch import torch.distributed as dist import torch.nn as nn import torch.nn.functional as F import torch.optim.lr_scheduler as lr_scheduler import tqdm from torch import Tensor from torch.distributed.checkpoint import load, save from torch.distributed.checkpoint.default_planner import DefaultLoadPlanner from torch.distributed.fsdp import FSDPModule, fully_shard from torch.distributed.tensor import Replicate, Shard from torch.distributed.tensor.parallel import ( ColwiseParallel, PrepareModuleInput, RowwiseParallel, SequenceParallel, loss_parallel, parallelize_module, ) from torch.utils.data.distributed import DistributedSampler # Set default to bfloat16 torch.set_default_dtype(torch.bfloat16) print(“NCCL version:”, torch.cuda.nccl.version()) # Build the model @dataclasses.dataclass class LlamaConfig: “”“Define Llama model hyperparameters.”“” vocab_size: int = 50000 # Size of the tokenizer vocabulary max_position_embeddings: int = 2048 # Maximum sequence length hidden_size: int = 768 # Dimension of hidden layers intermediate_size: int = 4*768 # Dimension of MLP’s hidden layer num_hidden_layers: int = 12 # Number of transformer layers num_attention_heads: int = 12 # Number of attention heads num_key_value_heads: int = 3 # Number of key-value heads for GQA class RotaryPositionEncoding(nn.Module): “”“Rotary position encoding.”“” def __init__(self, dim: int, max_position_embeddings: int) -> None: “”“Initialize the RotaryPositionEncoding module. Args: dim: The hidden dimension of the input tensor to which RoPE is applied max_position_embeddings: The maximum sequence length of the input tensor ““” super().__init__() self.dim = dim self.max_position_embeddings = max_position_embeddings # compute a matrix of n\theta_i N = 10_000.0 inv_freq = 1.0 / (N ** (torch.arange(0, dim, 2) / dim)) inv_freq = torch.cat((inv_freq, inv_freq), dim=–1) position = torch.arange(max_position_embeddings) sinusoid_inp = torch.outer(position, inv_freq) # save cosine and sine matrices as buffers, not parameters self.register_buffer(“cos”, sinusoid_inp.cos()) self.register_buffer(“sin”, sinusoid_inp.sin()) def forward(self, x: Tensor) -> Tensor: “”“Apply RoPE to tensor x. Args: x: Input tensor of shape (batch_size, seq_length, num_heads, head_dim) Returns: Output tensor of shape (batch_size, seq_length, num_heads, head_dim) ““” batch_size, seq_len, num_heads, head_dim = x.shape device = x.device dtype = x.dtype # transform the cosine and sine matrices to 4D tensor and the same dtype as x cos = self.cos.to(device, dtype)[:seq_len].view(1, seq_len, 1, –1) sin = self.sin.to(device, dtype)[:seq_len].view(1, seq_len, 1, –1) # apply RoPE to x x1, x2 = x.chunk(2, dim=–1) rotated = torch.cat((–x2, x1), dim=–1) output = (x * cos) + (rotated * sin) return output class LlamaAttention(nn.Module): “”“Grouped-query attention with rotary embeddings.”“” def __init__(self, config: LlamaConfig) -> None: super().__init__() self.hidden_size = config.hidden_size self.num_heads = config.num_attention_heads self.head_dim = self.hidden_size // self.num_heads self.num_kv_heads = config.num_key_value_heads # GQA: H_kv < H_q # hidden_size must be divisible by num_heads assert (self.head_dim * self.num_heads) == self.hidden_size # Linear layers for Q, K, V projections self.q_proj = nn.Linear(self.hidden_size, self.num_heads * self.head_dim, bias=False) self.k_proj = nn.Linear(self.hidden_size, self.num_kv_heads * self.head_dim, bias=False) self.v_proj = nn.Linear(self.hidden_size, self.num_kv_heads * self.head_dim, bias=False) self.o_proj = nn.Linear(self.num_heads * self.head_dim, self.hidden_size, bias=False) def forward(self, hidden_states: Tensor, rope: RotaryPositionEncoding, attn_mask: Tensor) -> Tensor: bs, seq_len, dim = hidden_states.size() # Project inputs to Q, K, V query_states = self.q_proj(hidden_states).view(bs, seq_len, self.num_heads, self.head_dim) key_states = self.k_proj(hidden_states).view(bs, seq_len, self.num_kv_heads, self.head_dim) value_states = self.v_proj(hidden_states).view(bs, seq_len, self.num_kv_heads, self.head_dim) # Apply rotary position embeddings query_states = rope(query_states) key_states = rope(key_states) # Transpose tensors from BSHD to BHSD dimension for scaled_dot_product_attention query_states = query_states.transpose(1, 2) key_states = key_states.transpose(1, 2) value_states = value_states.transpose(1, 2) # Use PyTorch’s optimized attention implementation # setting is_causal=True is incompatible with setting explicit attention mask attn_output = F.scaled_dot_product_attention( query_states, key_states, value_states, attn_mask=attn_mask, dropout_p=0.0, enable_gqa=True, ) # Transpose output tensor from BHSD to BSHD dimension, reshape to 3D, and then project output attn_output = attn_output.transpose(1, 2).reshape(bs, seq_len, self.hidden_size) attn_output = self.o_proj(attn_output) return attn_output class LlamaMLP(nn.Module): “”“Feed-forward network with SwiGLU activation.”“” def __init__(self, config: LlamaConfig) -> None: super().__init__() # Two parallel projections for SwiGLU self.gate_proj = nn.Linear(config.hidden_size, config.intermediate_size, bias=False) self.up_proj = nn.Linear(config.hidden_size, config.intermediate_size, bias=False) self.act_fn = F.silu # SwiGLU activation function # Project back to hidden size self.down_proj = nn.Linear(config.intermediate_size, config.hidden_size, bias=False) def forward(self, x: Tensor) -> Tensor: # SwiGLU activation: multiply gate and up-projected inputs gate = self.act_fn(self.gate_proj(x)) up = self.up_proj(x) return self.down_proj(gate * up) class LlamaDecoderLayer(nn.Module): “”“Single transformer layer for a Llama model.”“” def __init__(self, config: LlamaConfig) -> None: super().__init__() self.input_layernorm = nn.RMSNorm(config.hidden_size, eps=1e–5) self.self_attn = LlamaAttention(config) self.post_attention_layernorm = nn.RMSNorm(config.hidden_size, eps=1e–5) self.mlp = LlamaMLP(config) def forward(self, hidden_states: Tensor, rope: RotaryPositionEncoding, attn_mask: Tensor) -> Tensor: # First residual block: Self-attention residual = hidden_states hidden_states = self.input_layernorm(hidden_states) attn_outputs = self.self_attn(hidden_states, rope=rope, attn_mask=attn_mask) hidden_states = attn_outputs + residual # Second residual block: MLP residual = hidden_states hidden_states = self.post_attention_layernorm(hidden_states) hidden_states = self.mlp(hidden_states) + residual return hidden_states class LlamaModel(nn.Module): “”“The full Llama model without any pretraining heads.”“” def __init__(self, config: LlamaConfig) -> None: super().__init__() self.rotary_emb = RotaryPositionEncoding( config.hidden_size // config.num_attention_heads, config.max_position_embeddings, ) self.embed_tokens = nn.Embedding(config.vocab_size, config.hidden_size) self.layers = nn.ModuleList([ LlamaDecoderLayer(config) for _ in range(config.num_hidden_layers) ]) self.norm = nn.RMSNorm(config.hidden_size, eps=1e–5) def forward(self, input_ids: Tensor, attn_mask: Tensor) -> Tensor: # Convert input token IDs to embeddings hidden_states = self.embed_tokens(input_ids) # Process through all transformer layers, then the final norm layer for layer in self.layers: hidden_states = layer(hidden_states, rope=self.rotary_emb, attn_mask=attn_mask) hidden_states = self.norm(hidden_states) # Return the final hidden states return hidden_states class LlamaForPretraining(nn.Module): def __init__(self, config: LlamaConfig) -> None: super().__init__() self.base_model = LlamaModel(config) self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False) def forward(self, input_ids: Tensor, attn_mask: Tensor) -> Tensor: hidden_states = self.base_model(input_ids, attn_mask) return self.lm_head(hidden_states) def create_causal_mask(batch: Tensor, dtype: torch.dtype = torch.float32) -> Tensor: “”“Create a causal mask for self-attention. Args: batch: Batch of sequences, shape (batch_size, seq_len) dtype: Data type of the mask Returns: Causal mask of shape (seq_len, seq_len) ““” batch_size, seq_len = batch.shape mask = torch.full((seq_len, seq_len), float(“-inf”), device=batch.device, dtype=dtype) \ .triu(diagonal=1) return mask def create_padding_mask(batch: Tensor, padding_token_id: int, dtype: torch.dtype = torch.float32) -> Tensor: “”“Create a padding mask for a batch of sequences for self-attention. Args: batch: Batch of sequences, shape (batch_size, seq_len) padding_token_id: ID of the padding token dtype: Data type of the mask Returns: Padding mask of shape (batch_size, 1, seq_len, seq_len) ““” padded = torch.zeros_like(batch, device=batch.device, dtype=dtype) \ .masked_fill(batch == padding_token_id, float(“-inf”)) mask = padded[:,:,None] + padded[:,None,:] return mask[:, None, :, :] # Generator function to create padded sequences of

How Train Wi-Fi Works: Does Connection Get Lost At 120 km/hr? Check List Of Trains Offering Free Internet Service | Technology News
With more people relying on the internet while travelling, Wi-Fi on trains has become an important facility for passengers. Many wonder how internet works on a moving train and whether high speed—sometimes above 100 kmph affects the connection. Here’s a simple explanation of how train Wi-Fi works and which trains currently offer this service. How Train Wi-Fi Works? Train Wi-Fi does not come from satellites directly to passengers’ phones. Instead, trains are fitted with special routers and antennas on the roof. These antennas connect to nearby mobile towers using 4G or 5G networks, just like a mobile phone does. Add Zee News as a Preferred Source Inside the train, this signal is distributed to passengers through internal Wi-Fi routers installed in coaches. The system automatically switches between mobile towers as the train moves, ensuring continuous internet access. This process is known as “handover” and happens within seconds. Does Internet Stop at High Speeds? Even at speeds of 100–130 kmph, Wi-Fi generally continues to work. Modern mobile networks are designed to support fast-moving users, such as those in trains or cars. However, brief slowdowns or disconnections can happen while passing through tunnels, remote areas, forests, or regions with weak network coverage. Internet speed may also reduce when many passengers are connected at the same time, especially during peak travel hours. (Also Read: New Year’s Eve Tech Tip: How You Place Your Smartphone On Table Can Improve Privacy, Focus, Battery, And Mental Peace-Explained) Which Trains Offer Wi-Fi in India? Indian Railways provides Wi-Fi services under the RailWire program, operated by RailTel. Free Wi-Fi is available at over 6,000 railway stations across the country. Some premium trains and routes also offer onboard Wi-Fi, including: Vande Bharat Express Shatabdi Express Rajdhani Express Gatimaan Express Selected Tejas Express routes Future of Train Connectivity Indian Railways is working to expand onboard Wi-Fi and improve signal strength using advanced LTE and upcoming 5G technologies. The goal is to offer smoother internet access for work, entertainment, and communication during long journeys.

New Year’s Eve Tech Tip: How You Place Your Smartphone On Table Can Improve Privacy, Focus, Battery, And Mental Peace-Explained | Technology News
Face Down Phone Benefits: As we celebrate New Year’s Eve and spend time with family and friends, smartphones have become an important part of our daily lives. Whether we are working, attending meetings, eating, or enjoying moments with loved ones, our phone is usually kept right in front of us. However, one small thing is often ignored. Should the phone be kept with the screen facing up or down? This small habit may look not crucial, but it directly affects our concentration, peace of mind, privacy, and digital health. Today, keeping the phone screen facing up has become a common mistake. It causes many problems without us even noticing them. Your Privacy Is At Risk When Screen Faces Up Add Zee News as a Preferred Source When your phone is kept with the screen facing up, it can show your private information without you knowing it. Bank messages, OTPs, personal chats, or office notifications can be seen by people sitting nearby. Many times, we do not even notice what appeared on the screen or who may have seen it. Keeping the phone face down removes this risk immediately. At a time when digital privacy is becoming more important, this simple habit helps keep your personal information safe without any extra effort. Notifications Make It Hard to Concentrate One of the biggest strengths of a smartphone is notifications, but they can also become its biggest weakness. When the screen is facing up, every vibration or flash of light pulls your attention. Even if you do not plan to check the phone, your mind automatically shifts toward it. Keeping the phone face down removes this visual distraction and helps you stay focused on work, conversations, or studies. Over time, this habit teaches your brain that not every alert needs immediate attention. (Also Read: Moto G-Series Smartphone Users Alarmed After Device Reportedly Bursts Into Flames; User Slams Nehru Place Service Centre | Viral Video) How Screen Position Affects Your Mind When a phone keeps lighting up in front of you, your mind stays in alert mode all the time. This can make you feel tired and restless. Keeping the phone face down tells your brain that the phone is not important at that moment. As a result, you feel more calm and relaxed. Whether you are with your family or sitting alone, this habit helps you pay more attention to what is happening around you. Why Keeping the Phone Face Down Is Safer The screen and camera are the most costly and sensitive parts of a smartphone. When the phone is kept with the screen facing up, water drops, tea or coffee, and food pieces can fall on it. The camera lens can also get damaged slowly by rubbing against the table. Keeping the phone face down protects both the screen and the camera. It also lowers the chance of the phone slipping or falling, especially on smooth tables. How Face-Down Phone Saves Your Battery Every time the phone screen lights up and you unlock it, the battery gets used a little. When the phone is kept face down, notifications are less tempting, so you pick up the phone less often. This helps reduce screen time, makes the battery last longer, and puts less strain on your eyes. It also gives a small but healthy break to both the phone and the user. Focus on Real Life, Not Your Phone By keeping your phone face down, you take control instead of letting the phone control you. It also shows the people around you that you are giving them your full attention. Slowly, you start paying more attention to real-life moments instead of constant phone distractions. This balance is the key to a healthy digital life, where technology helps you instead of taking over.

Elon Musk’s xAI To Expand Computing Capacity To 2 GW | Technology News
New Delhi: Tesla and SpaceX CEO Elon Musk’s xAI company has purchased a third building near its existing Memphis sites in the US, that will bring its artificial intelligence (AI) computing capacity to almost 2 gigawatts (GW). Elon Musk has already built one data centre in Memphis, known as Colossus, and is constructing a second centre nearby dubbed Colossus 2, according to multiple reports. The newly acquired building is in Southaven, Mississippi, and adjoins the Colossus 2 facility, according to reports citing people familiar with the matter. “xAI has bought a third building called Macrohardrr,” Musk posted on social media platform X, saying it will “take @xAI training compute to almost 2GW.” A gigawatt is enough to provide electricity for about 7,50,000 US homes. Musk has publicly discussed plans to build the world’s largest data centre for AI training and previously said Colossus 2 will eventually have 5,50,000 chips from Nvidia, costing tens of billions of dollars. Add Zee News as a Preferred Source Moreover, Musk’s xAI Holdings is reportedly in talks to raise new funding at around $230 billion valuation. Musk owns a 53 per cent stake in xAI Holdings, worth $60 billion. Elon Musk took a dig at Wikipedia in October, claiming Grokipedia, developed by xAI, will surpass the popular online encyclopedia “by several orders of magnitude in breadth, depth and accuracy.” Grokipedia is an AI-powered encyclopedia that aims to challenge what Musk calls a “woke” and biased Wikipedia. He described Grokipedia as a “massive improvement over Wikipedia” and said it aligns with xAI’s mission to help humanity better understand the universe. Musk’s net worth rose to nearly $750 billion after a US court reinstated Tesla stock options worth $139 billion. According to Forbes’ billionaires index, this development has taken Musk closer to become the world’s first trillionaire.

OPPO Pad 5 Officially Confirmed To Launch In India Alongside OPPO Reno 15 Series; Check Expected Display, Camera, Price, And Other Specs | Technology News
OPPO Pad 5 Price In India: Chinese smartphone brand OPPO has confirmed that it will soon launch the OPPO Pad 5 in India. The tablet’s India debut was spotted on a Flipkart microsite created for the upcoming OPPO Reno 15 series, where the OPPO Pad 5 is mentioned at the bottom. While OPPO has not officially announced the launch date yet, the listing strongly hints that the tablet will arrive alongside or around the Reno 15 series launch. The OPPO Pad 5 has already been introduced in China, giving users an early idea of what to expect. In India, the Android tablet is likely to be available in Black and Pink colour options, although OPPO has not revealed the official names of these shades so far. OPPO Pad 5 Specifications (Expected) Add Zee News as a Preferred Source The OPPO Pad 5 is expected to sport a large 12.1-inch LCD display with an adaptive 120Hz refresh rate, going up to 144Hz for smoother visuals. The Android tablet could be powered by the MediaTek Dimensity 9400+ chipset, paired with up to 16GB of RAM and 512GB of internal storage for seamless multitasking. The tablet is likely to pack a massive 10,050mAh battery with 67W fast charging support, ensuring longer usage with quicker top-ups. On the software front, the OPPO Pad 5 is expected to run ColorOS 16 based on Android 16. For photography and video calls, it may feature an 8MP camera on both the front and rear. OPPO Pad 5 Price in India (Expected) In China, the OPPO Pad 5 is priced fromCNY 2,599 (around Rs. 32,000) for the base variant, while the top-end model costs nearly Rs. 44,000. If OPPO follows similar pricing in India, the tablet will rival the Samsung Galaxy Tab S10 FE and the Apple iPad.



