

Samsung Galaxy S26 Ultra India Launch: South Korean Giant Samsung has prepared its flagship Galaxy S26 series for the next Galaxy Unpacked event. The Galaxy S26 lineup is set to come with three models which includes the Galaxy S26, Galaxy S26 Plus and the premium Galaxy S26 Ultra. The battery for the Galaxy S26+ has now been certified by India’s Bureau of Indian Standards (BIS). However, the base Galaxy S26 and S26 Ultra have already picked up this battery certification. Adding further, the Bureau of Indian Standards (BIS) has approved battery packs for a Samsung phone with the model number SM-S946. This phone is believed to be the Galaxy S26+. Earlier, BIS had also approved batteries for other Galaxy S26 models, including SM-S942 (Galaxy S26/Pro), SM-S947 (the canceled Galaxy S26 Edge), and SM-S948 (Galaxy S26 Ultra). The certification does not reveal detailed specifications, it confirms that Samsung has begun clearing mandatory approvals ahead of the official launch. The Samsung is likely to ship the phone with One UI 8.5 based on Android 16 right out of the box. The Galaxy S26 Ultra is expected to carry forward the boxy look of the S25 Ultra. Add Zee News as a Preferred Source Samsung Galaxy S26 Ultra Specifications (Expected) The Samsung Galaxy S26 Ultra is expected to feature a large 6.9-inch Dynamic AMOLED display with a 1440 x 3120 QHD+ resolution, 19.5:9 aspect ratio, and 498 PPI, delivering sharp and immersive visuals. The screen is also tipped to use Samsung’s AI-powered Flex Magic Pixel technology, which intelligently controls light emission for better efficiency and viewing comfort. Under the hood, the flagship is likely to be powered by the next-generation Snapdragon 8 Elite Gen 5 chipset, paired with 12GB of RAM and storage options of 256GB, 512GB, and 1TB. Despite retaining a 5,000mAh battery similar to previous models, the Galaxy S26 Ultra is said to offer faster charging speeds, supporting 60W wired charging and 20W wireless charging. On the photography front, the device is tipped to sport a powerful 200-megapixel primary camera, complemented by a 50-megapixel ultra-wide lens, a 50-megapixel telephoto camera with 5x optical zoom, and an additional 10-megapixel telephoto sensor, making it a strong contender for mobile photography enthusiasts. (Also Read: OnePlus 15R Launched In India With Qualcomm Snapdragon 8 Gen 5; Check Camera, Battery, Display, Price, Sale Date And , Bank Offers Other Specs) Samsung Galaxy S26 Ultra India Launch And Price (Expected) According to recent reports, Samsung is likely to unveil the Galaxy S26 series at a Galaxy Unpacked event on February 25, 2026, with San Francisco tipped as the possible venue. In India, the Galaxy S26 Ultra is expected to be priced at around Rs 1,34,999.

World’s Richest Person: Did You Know? xAI CEO Elon Musk’s Current Net Worth After US Court Restores Tesla Pay Package | Technology News
World’s Richest Person: xAI and SpaceX CEO Elon Musk’s net worth has jumped to nearly $750 billion after a US court brought back his Tesla stock options worth $139 billion. According to Forbes’ billionaires list, this move puts Musk closer to becoming the world’s first trillionaire. The Delaware Supreme Court in the US restored Musk’s 2018 Tesla pay deal, cancelling an earlier lower-court decision that had rejected it. The court said that removing the pay package completely would mean Musk was not paid at all for his work over the past six years. This decision overturned a 2024 ruling that had cancelled the package. Based on Tesla’s latest share price, the 2018 pay deal is worth about $139 billion. If Musk uses all the stock options, his ownership in Tesla would increase from 12.4% to 18.1%.The 2018 pay deal provided Musk options to buy about 304 million shares at a discounted price if Tesla met specific milestones. Tesla’s board had warned that Elon Musk, the world’s richest person, leading the SpaceX rocket venture, could leave the electric car company if his pay was disrupted. Add Zee News as a Preferred Source Tesla CEO Becomes First Person To Surpass $600 Billion Net Worth Earlier this week, the Tesla CEO became the first person ever to surpass $600 billion in net worth over reports that SpaceX was likely to go public. With his company SpaceX reportedly launching a tender offer, valuing the firm at $800 billion, Musk’s net worth has surged by $168 billion to an estimated $677 billion. SpaceX is aiming for an initial public offering (IPO) next year that may value the firm at around $1.5 trillion. Also, Musk’s 12 per cent stake in electric vehicle maker Tesla is worth $197 billion, excluding stock options. Moreover, Musk’s xAI Holdings is reportedly in talks to raise new funding at around $230 billion valuation. Musk owns a 53 per cent stake in xAI Holdings, worth $60 billion. (With IANS Inputs)
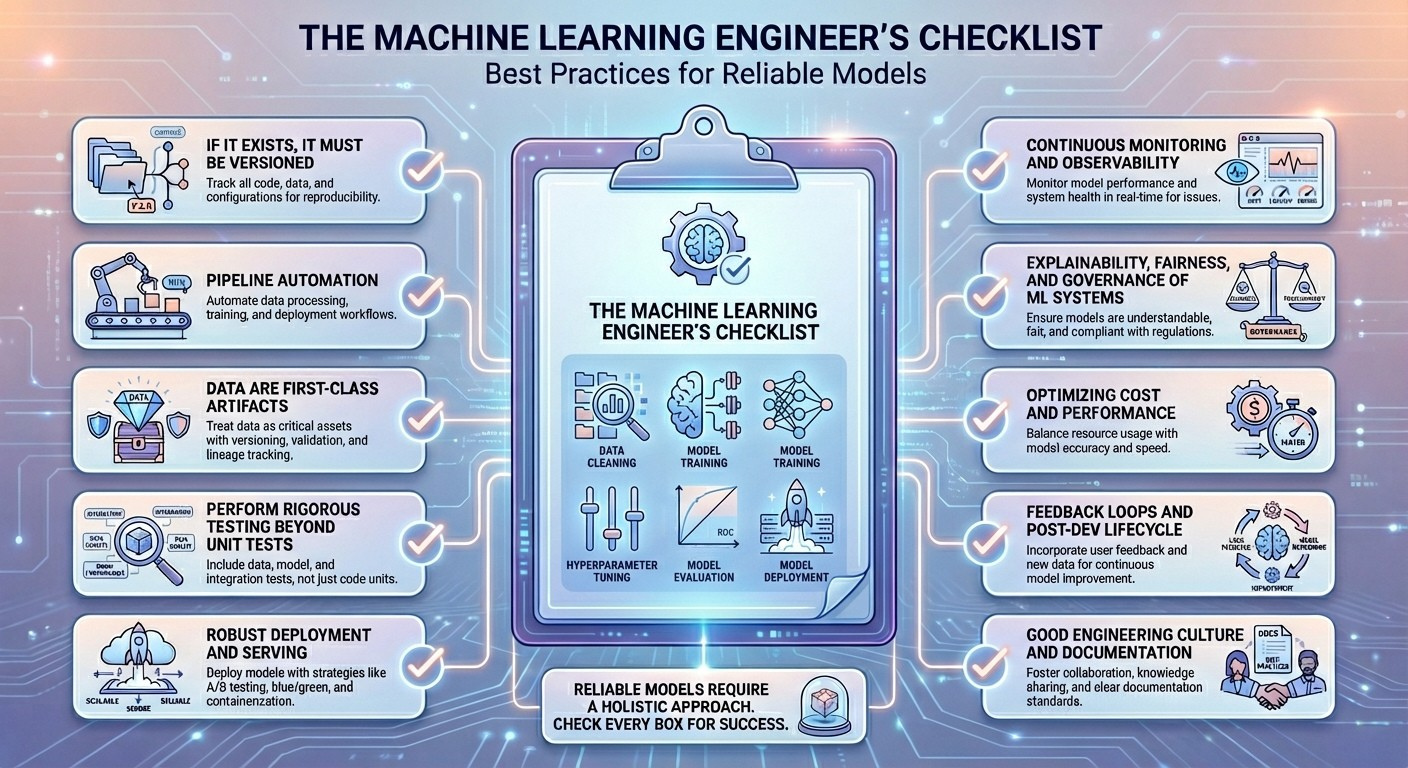
The Machine Learning Engineer’s Checklist: Best Practices for Reliable Models
The Machine Learning Engineer’s Checklist: Best Practices for Reliable ModelsImage by Editor Introduction Building newly trained machine learning models that work is a relatively straightforward endeavor, thanks to mature frameworks and accessible computing power. However, the real challenge in the production lifecycle of a model begins after the first successful training run. Once deployed, a model operates in a dynamic, unpredictable environment where its performance can degrade rapidly, turning a successful proof-of-concept into a costly liability. Practitioners often encounter issues like data drift, where the characteristics of the production data change over time; concept drift, where the underlying relationship between input and output variables evolves; or subtle feedback loops that bias future training data. These pitfalls — which range from catastrophic model failures to slow, insidious performance decay — are often the result of lacking the right operational rigor and monitoring systems. Building reliable models that keep performing well in the long run is a different story, one that requires discipline, a robust MLOps pipeline, and, of course, skill. This article focuses on exactly that. By providing a systematic approach to tackle these challenges, this research-backed checklist outlines essential best practices, core skills, and sometimes not-to-miss tools that every machine learning engineer should be familiar with. By adopting the principles outlined in this guide, you will be equipped to transform your initial models into maintainable, high-quality production systems, ensuring they remain accurate, unbiased, and resilient to the inevitable shifts and challenges of the real world. Without further ado, here is the list of 10 machine learning engineer best practices I curated for you and your upcoming models to shine at their best in terms of long-term reliability. The Checklist 1. If It Exists, It Must Be Versioned Data snapshots, code for training models, hyperparameters used, and model artifacts — everything matters, and everything is subject to variations across your model lifecycle. Therefore, everything surrounding a machine learning model should be properly versioned. Just imagine, for instance, that your image classification model’s performance, which used to be great, starts to drop after a concrete bug fix. With versioning, you will be able to reproduce the old model settings and isolate the root cause of the problem more safely. There is no rocket science here — versioning is widely known across the engineering community, with core skills like managing Git workflows, data lineage, and experiment tracking; and specific tools like DVC, Git/GitHub, MLflow, and Delta Lake. 2. Pipeline Automation As part of continuous integration and continuous delivery (CI/CD) principles, repeatable processes that involve data preprocessing through training, validation, and deployments should be encapsulated in pipelines with automated running and testing underneath them. Suppose a nightly set-up pipeline that fetches new data — e.g. images captured by a sensor — runs validation tests, retrains the model if needed (because of data drift, for example), re-evaluates business key performance indicators (KPIs), and pushes the updated model(s) to staging. This is a common example of pipeline automation, and it takes skills like workflow orchestration, fundamentals of technologies like Docker and Kubernetes, and test automation knowledge. Commonly useful tools here include: Airflow, GitLab CI, Kubeflow, Flyte, and GitHub Actions. 3. Data Are First-Class Artifacts The rigor with which software tests are applied in any software engineering project must be present for enforcing data quality and constraints. Data is the essential nourishment of machine learning models from inception to serving in production; hence, the quality of whatever data they ingest must be optimal. A solid understanding of data types, schema designs, and data quality issues like anomalies, outliers, duplicates, and noise is vital to treat data as first-class assets. Tools like Evidently, dbt tests, and Deequ are designed to help with this. 4. Perform Rigorous Testing Beyond Unit Tests Testing machine learning systems involves specific tests for aspects like pipeline integration, feature logic, and statistical consistency of inputs and outputs. If a refactored feature engineering script applies a subtle modification in a feature’s original distribution, your system may pass basic unit tests, but through distribution tests, the issue might be detected in time. Test-driven development (TDD) and knowledge of statistical hypothesis tests are strong allies to “put this best practice into practice,” with imperative tools under the radar like the pytest library, customized data drift tests, and mocking in unit tests. 5. Robust Deployment and Serving Having a robust machine learning model deployment and serving in production entails that the model should be packaged, reproducible, scalable to large settings, and have the ability to roll back safely if needed. The so-called blue–green strategy, based on deploying into two “identical” production environments, is a way to ensure incoming data traffic can be shifted back quickly in the event of latency spikes. Cloud architectures together with containerization help to this end, with specific tools like Docker, Kubernetes, FastAPI, and BentoML. 6. Continuous Monitoring and Observability This is probably already in your checklist of best practices, but as an essential of machine learning engineering, it is worth pointing it out. Continuous monitoring and observability of the deployed model involves monitoring data drift, model decay, latency, cost, and other domain-specific business metrics beyond just accuracy or error. For example, if the recall metric of a fraud detection model drops upon the emergence of new fraud patterns, properly set drift alerts may trigger the need for retraining the model with fresh transaction data. Prometheus and business intelligence tools like Grafana can help a lot here. 7. Explainability, Fairness, and Governance of ML Systems Another essential for machine learning engineers, this best practice aims at ensuring the delivery of models with transparent, compliant, and responsible behavior, understanding and adhering to existing national or regional regulations — for instance, the European Union AI Act. An example of the application of these principles could be a loan classification model that triggers fairness checks before being deployed to guarantee no protected groups are unreasonably rejected. For interpretability and governance, tools like SHAP, LIME, model registries, and Fairlearn are highly recommended. 8. Optimizing Cost and Performance

5 Agentic Coding Tips & Tricks
5 Agentic Coding Tips & TricksImage by Editor Introduction Agentic coding only feels “smart” when it ships correct diffs, passes tests, and leaves a paper trail you can trust. The fastest way to get there is to stop asking an agent to “build a feature” and start giving it a workflow it cannot escape. That workflow should force clarity (what changes), evidence (what passed), and containment (what it can touch). The tips below are concrete patterns you can drop into daily work with code agents, whether you are using a CLI agent, an IDE assistant, or a custom tool-using model. 1. Use A Repo Map To Prevent Blind Refactors Agents get generic when they do not understand the topology of your codebase. They default to broad refactors because they cannot reliably locate the right seams. Give the agent a repo map that is short, opinionated, and anchored in the parts that matter. Create a machine-readable snapshot of your project structure and key entry points. Keep it under a few hundred lines. Update it when major folders change. Then feed the map into the agent before any coding. Here’s a simple generator you can keep in tools/repo_map.py: from pathlib import Path INCLUDE_EXT = {“.py”, “.ts”, “.tsx”, “.go”, “.java”, “.rs”} SKIP_DIRS = {“node_modules”, “.git”, “dist”, “build”, “__pycache__”} root = Path(__file__).resolve().parents[1] lines = [] for p in sorted(root.rglob(“*”)): if any(part in SKIP_DIRS for part in p.parts): continue if p.is_file() and p.suffix in INCLUDE_EXT: rel = p.relative_to(root) lines.append(str(rel)) print(“\n”.join(lines[:600])) from pathlib import Path INCLUDE_EXT = {“.py”, “.ts”, “.tsx”, “.go”, “.java”, “.rs”} SKIP_DIRS = {“node_modules”, “.git”, “dist”, “build”, “__pycache__”} root = Path(__file__).resolve().parents[1] lines = [] for p in sorted(root.rglob(“*”)): if any(part in SKIP_DIRS for part in p.parts): continue if p.is_file() and p.suffix in INCLUDE_EXT: rel = p.relative_to(root) lines.append(str(rel)) print(“\n”.join(lines[:600])) Add a second section that names the real “hot” files, not everything. Example: Entry Points: api/server.ts (HTTP routing) core/agent.ts (planning + tool calls) core/executor.ts (command runner) packages/ui/App.tsx (frontend shell) Key Conventions: Never edit generated files in dist/ All DB writes go through db/index.ts Feature flags live in config/flags.ts This reduces the agent’s search space and stops it from “helpfully” rewriting half the repository because it got lost. 2. Force Patch-First Edits With A Diff Budget Agents derail when they edit like a human with unlimited time. Force them to behave like a disciplined contributor: propose a patch, keep it small, and explain the intent. A practical trick is a diff budget, an explicit limit on lines changed per iteration. Use a workflow like this: Agent produces a plan and a file list Agent produces a unified diff only You apply the patch Tests run Next patch only if needed If you are building your own agent loop, make sure to enforce it mechanically. Example pseudo-logic: MAX_CHANGED_LINES = 120 def count_changed_lines(unified_diff: str) -> int: return sum(1 for line in unified_diff.splitlines() if line.startswith((“+”, “-“)) and not line.startswith((“+++”, “—“))) changed = count_changed_lines(diff) if changed > MAX_CHANGED_LINES: raise ValueError(f”Diff too large: {changed} changed lines”) MAX_CHANGED_LINES = 120 def count_changed_lines(unified_diff: str) -> int: return sum(1 for line in unified_diff.splitlines() if line.startswith((“+”, “-“)) and not line.startswith((“+++”, “—“))) changed = count_changed_lines(diff) if changed > MAX_CHANGED_LINES: raise ValueError(f“Diff too large: {changed} changed lines”) For manual workflows, bake the constraint into your prompt: Output only a unified diff Hard limit: 120 changed lines total No unrelated formatting or refactors If you need more, stop and ask for a second patch Agents respond well to constraints that are measurable. “Keep it minimal” is vague. “120 changed lines” is enforceable. 3. Convert Requirements Into Executable Acceptance Tests Vague requests can prevent an agent from properly editing your spreadsheet, let alone coming up with proper code. The fastest way to make an agent concrete, regardless of its design pattern, is to translate requirements into tests before implementation. Treat tests as a contract the agent must satisfy, not a best-effort add-on. A lightweight pattern: Write a failing test that captures the feature behavior Run the test to confirm it fails for the right reason Let the agent implement until the test passes Example in Python (pytest) for a rate limiter: import time from myapp.ratelimit import SlidingWindowLimiter def test_allows_n_requests_per_window(): lim = SlidingWindowLimiter(limit=3, window_seconds=1) assert lim.allow(“u1”) assert lim.allow(“u1”) assert lim.allow(“u1”) assert not lim.allow(“u1”) time.sleep(1.05) assert lim.allow(“u1”) import time from myapp.ratelimit import SlidingWindowLimiter def test_allows_n_requests_per_window(): lim = SlidingWindowLimiter(limit=3, window_seconds=1) assert lim.allow(“u1”) assert lim.allow(“u1”) assert lim.allow(“u1”) assert not lim.allow(“u1”) time.sleep(1.05) assert lim.allow(“u1”) Now the agent has a target that is objective. If it “thinks” it is done, the test decides. Combine this with tool feedback: the agent must run the test suite and paste the command output. That one requirement kills an entire class of confident-but-wrong completions. Prompt snippet that works well: Step 1: Write or refine tests Step 2: Run tests Step 3: Implement until tests pass Always include the exact commands you ran and the final test summary. If tests fail, explain the failure in one paragraph, then patch. 4. Add A “Rubber Duck” Step To Catch Hidden Assumptions Agents make silent assumptions about data shapes, time zones, error handling, and concurrency. You can surface those assumptions with a forced “rubber duck” moment, right before coding. Ask for three things, in order: Assumptions the agent is making What could break those assumptions? How will we validate them? Keep it short and mandatory. Example: Before coding: list 5 assumptions For each: one validation step using existing code or logs If any assumption cannot be validated, ask one clarification question and stop This creates a pause that often prevents bad architectural commits. It also gives you an easy review checkpoint. If you disagree with an assumption, you can correct it before the agent writes code that bakes it in. A common win is catching data contract mismatches early. Example: the agent assumes a timestamp is ISO-8601, but the API returns epoch milliseconds. That one mismatch can cascade into “bugfix” churn. The rubber duck step flushes it out. 5.
Instagram Hashtag Feature: Meta-Owned Platform Limits Number Of Hashtags For Reels And Posts; Know Why And Follow Tips For Optimal Use | Technology News
Instagram Hashtag Feature: Instagram, owned by Meta, has updated its hashtag feature, limiting the number of hashtags in posts and reels. Users can now add up to five hashtags, reduced from the previous limit of 30. This change comes as evidence grows that hashtags may no longer work the way they used to. Instagram explained that using fewer and more targeted hashtags instead of generic ones can improve both content performance and the overall experience on the platform. However, a similar approach applies to Instagram’s sister app, Threads, where users can add only one tag per post. According to Mosseri, this design choice encourages community building rather than focusing on “engagement hacking.” The limit of five hashtags comes after a year of testing, during which some users were allowed only three tags. Meta found that using focused and relevant hashtags not only boosts content performance but also improves the overall user experience by reducing clutter and spam in captions. The new limit will be rolled out gradually as Instagram updates all accounts. Add Zee News as a Preferred Source Earlier this month, Instagram started testing a change that could affect content creators. The company was trying out a rule that lets users add only three hashtags per post, a big change from the old limit since 2011, according to a report by HT. Instagram did not officially announce the test, but some Reddit users said they got error messages when they tried to add more than three hashtags. Not all users were affected, which shows that Meta was testing the change with a small group before deciding to apply it to everyone. (Also Read: Google Issues Travel Warning For Employees Amid 12-Month US Visa Delay; Check H-1B Visa Fees) Instagram Hashtag Feature: Tips For Optimal Use Choose hashtags carefully and use ones that match your content. For example, if you create beauty videos, use beauty-related hashtags so people interested in beauty can find you. Avoid using too many generic or unrelated hashtags like #reels or #explore. These don’t help your content show up in Explore and might actually lower how well your posts perform.

Google Issues Travel Warning For Employees Amid 12-Month US Visa Delay; Check H-1B Visa Fees | Technology News
Google Alerts Visa Employees: Google has warned some employees in the US on visas to avoid traveling abroad. The company said visa re-entry processing at US embassies and consulates could be delayed for up to a year, according to Business Insider. According to the Google’s external immigration counsel, BAL Immigration Law, warned employees who need a visa stamp that traveling abroad could keep them from returning to the U.S. for several months because of long appointment delays, according to Business Insider. The internal memo said US embassies and consulates are facing visa stamping delays of up to 12 months. It advised employees to avoid international travel unless it’s absolutely necessary. This affects workers on H-1B, H-4, F, J, and M visas. Add Zee News as a Preferred Source It is important to note that the delays are being reported across several countries as US missions grapple with routine visa backlogs following the rollout of enhanced social media screening requirements. These checks apply to H-1B workers and their dependents, as well as students and exchange visitors on F, J, and M visas, Business Insider reported. Google’s Legal Advisory On the other hand, Google’s legal advisory noted that the disruption spans multiple visa categories but did not specify next steps for employees who are already outside the US and facing postponed appointments. A Google spokesperson declined to comment, Business Insider reported. The US Department of State confirmed the delays, telling Business Insider on Friday, December 19, that it is conducting “online presence reviews for applicants.” A spokesperson said visa appointments might be rescheduled as staffing and resources change, and applicants can request expedited processing in certain cases. (Also Read: Gmail Vs Zoho Mail Comparison: Why People Are Moving Away From Gmail? Check Security And Safety Features; Here’s How To Switch) H-1B Visa Programme The H-1B program, which gives out 85,000 new visas each year, is an important way for major US tech companies like Google, Amazon, Microsoft, and Meta to hire skilled workers. Under the Trump administration, the program became controversial, with critics saying stricter rules and higher costs make it harder for companies to hire foreign talent. The H-1B visa is widely used to hire skilled workers from India and China. This year, a $100,000 fee for new applications added more attention to the program. In September, Google’s parent company, Alphabet, advised employees to avoid traveling abroad and urged H-1B visa holders to stay in the U.S., according to an email seen by Reuters.

How to Fine-Tune a Local Mistral or Llama 3 Model on Your Own Dataset
In this article, you will learn how to fine-tune open-source large language models for customer support using Unsloth and QLoRA, from dataset preparation through training, testing, and comparison. Topics we will cover include: Setting up a Colab environment and installing required libraries. Preparing and formatting a customer support dataset for instruction tuning. Training with LoRA adapters, saving, testing, and comparing against a base model. Let’s get to it. How to Fine-Tune a Local Mistral/Llama 3 Model on Your Own Dataset Introduction Large language models (LLMs) like Mistral 7B and Llama 3 8B have shaken the AI field, but their broad nature limits their application to specialized areas. Fine-tuning transforms these general-purpose models into domain-specific experts. For customer support, this means an 85% reduction in response time, a consistent brand voice, and 24/7 availability. Fine-tuning LLMs for specific domains, such as customer support, can dramatically improve their performance on industry-specific tasks. In this tutorial, we’ll learn how to fine-tune two powerful open-source models, Mistral 7B and Llama 3 8B, using a customer support question-and-answer dataset. By the end of this tutorial, you’ll learn how to: Set up a cloud-based training environment using Google Colab Prepare and format customer support datasets Fine-tune Mistral 7B and Llama 3 8B using Quantized Low-Rank Adaptation (QLoRA) Evaluate model performance Save and deploy your custom models Prerequisites Here’s what you will need to make the most of this tutorial. A Google account for accessing Google Colab. You can check Colab here to see if you are ready to access. A Hugging Face account for accessing models and datasets. You can sign up here. After you have access to Hugging Face, you will need to request access to these 2 gated models: Mistral: Mistral-7B-Instruct-v0.3 Llama 3: Meta-Llama-3-8B-Instruct And as far as the requisite knowledge you should have before starting, here’s a concise overview: Basic Python programming Be familiar with Jupyter notebooks Understanding of machine learning concepts (helpful but not required) Basic command-line knowledge You should now be ready to get started. The Fine-Tuning Process Fine-tuning adapts a pre-trained LLM to specific tasks by continuing training on domain-specific data. Unlike prompt engineering, fine-tuning actually modifies model weights. Step 1: Getting Started with Google Colab Visit Google Colab Create new notebook: File → New Notebook Give it a preferred name Set GPU: Runtime → Change runtime type → T4 GPU Step 2: Install Unsloth (Run This First) Here, we will install Unsloth and its dependencies. Unsloth handles CUDA setup automatically. !pip install “unsloth[colab-new] @ git+https://github.com/unslothai/unsloth.git” !pip install –no-deps xformers trl peft accelerate bitsandbytes print(“Unsloth installed successfully!”) !pip install “unsloth[colab-new] @ git+https://github.com/unslothai/unsloth.git” !pip install —no–deps xformers trl peft accelerate bitsandbytes print(“Unsloth installed successfully!”) Step 3: Import Unsloth and Setup The next step is to import Unsloth and perform basic checks. from unsloth import FastLanguageModel import torch from trl import SFTTrainer from transformers import TrainingArguments from datasets import Dataset import pandas as pd import numpy as np print(“Unsloth loaded successfully!”) print(f”PyTorch: {torch.__version__}”) print(f”CUDA: {torch.cuda.is_available()}”) print(f”GPU: {torch.cuda.get_device_name(0) if torch.cuda.is_available() else ‘None’}”) from unsloth import FastLanguageModel import torch from trl import SFTTrainer from transformers import TrainingArguments from datasets import Dataset import pandas as pd import numpy as np print(“Unsloth loaded successfully!”) print(f“PyTorch: {torch.__version__}”) print(f“CUDA: {torch.cuda.is_available()}”) print(f“GPU: {torch.cuda.get_device_name(0) if torch.cuda.is_available() else ‘None’}”) Step 4: Create Customer Support Dataset We will supply realistic customer support data in this section for the purpose of fine-tuning the model. print(“Creating customer support Q&A dataset…”) # Create realistic customer support data customer_support_data = [ { “instruction”: “You are a helpful customer support agent. Answer clearly and professionally.”, “input”: “How do I reset my password?”, “output”: “To reset your password: 1) Click ‘Forgot Password’ on the login page 2) Enter your registered email 3) Check your inbox for the reset link 4) Click the link and create a new password. Check your spam folder if not received within 5 minutes.” }, { “instruction”: “You are a helpful customer support agent. Answer clearly and professionally.”, “input”: “My payment was declined, what should I do?”, “output”: “Common solutions: 1) Check that the card has sufficient funds 2) Ensure the card is not expired 3) Contact your bank to unblock the transaction 4) Try an alternative payment method like PayPal 5) Wait 24 hours before retrying.” }, { “instruction”: “You are a helpful customer support agent. Answer clearly and professionally.”, “input”: “How do I cancel my subscription?”, “output”: “To cancel: 1) Log in to your account 2) Go to ‘Billing & Subscriptions’ 3) Click ‘Cancel Subscription’ 4) Confirm cancellation. Your access continues until the end of the billing period. No partial refunds.” }, { “instruction”: “You are a helpful customer support agent. Answer clearly and professionally.”, “input”: “The app keeps crashing on startup”, “output”: “Troubleshooting steps: 1) Update the app to the latest version 2) Restart your device 3) Clear the app cache/data 4) Reinstall the app 5) Ensure 500MB free storage 6) Update your device OS. If it persists, contact support with error logs.” }, { “instruction”: “You are a helpful customer support agent. Answer clearly and professionally.”, “input”: “Where is my order tracking information?”, “output”: “You can find tracking: 1) Check the confirmation email 2) Log into your account > Orders 3) Click the tracking number. Standard shipping: 3-5 business days. Contact the carrier with the tracking number for the exact location.” }, { “instruction”: “You are a helpful customer support agent. Answer clearly and professionally.”, “input”: “How do I contact customer support?”, “output”: “Support options: 1) Live chat: Mon–Fri 9AM–6PM EST 2) Email: support@company.com (response within 24h) 3) Phone: 1-800-123-4567 4) Twitter: @CompanySupport. Please have your account email ready.” }, { “instruction”: “You are a helpful customer support agent. Answer clearly and professionally.”, “input”: “Can I get a refund?”, “output”: “Refund policy: 1) Digital products: Refund within 14 days if not used 2) Subscriptions: No refunds for partial months 3) Physical goods: Return within 30 days with receipt. Contact billing@company.com with your order ID.” }, { “instruction”: “You are a helpful customer support agent. Answer clearly

India–AI Impact Summit 2026: How India Is Setting Standards For Ethical And Inclusive AI – Details | Technology News
New Delhi: As India prepares to host the India–AI Impact Summit 2026 in the national capital this February, a set of research-led initiatives is emerging as the knowledge backbone of the global event, positioning the country as a hub for responsible and impact-driven artificial intelligence, particularly for the Global South. At the centre of the effort are five research casebooks and a dedicated research symposium being developed by IndiaAI in partnership with leading international and domestic institutions. These initiatives focus on real-world AI deployments and aim to guide countries on scaling AI solutions that are ethical, inclusive and sustainable. One of the key initiatives is the AI for Energy Casebook, developed with the International Energy Agency, which documents how AI is being used to forecast renewable energy, improve grid reliability and enhance industrial efficiency. The casebook compiles proven deployments to support energy security and sustainability, especially in emerging economies. Add Zee News as a Preferred Source In healthcare, IndiaAI has partnered with the World Health Organisation to document AI use cases across the Global South. The casebook highlights deployed solutions in diagnostics, disease surveillance, maternal health, telemedicine and supply-chain optimisation, capturing both impact and lessons for responsible scaling. Another major initiative is the Compendium on Gender-Transformative AI Solutions, curated with UN Women India. It focuses on AI innovations that advance gender equality by supporting women’s safety, financial inclusion, health, education, skilling and climate resilience, while addressing bias through evidence-based design. The education-focused compendium, developed with CSF and the EkStep Foundation, showcases scalable AI solutions improving foundational learning, supporting teachers and enhancing inclusion across emerging economies. Selected case studies will be presented at the summit and contribute to a global evidence base for AI adoption in education. In agriculture, IndiaAI is working with the Government of Maharashtra’s AI and Agritech Innovation Centre and the World Bank to compile deployed AI solutions delivering measurable benefits to farmers and agricultural systems. Complementing these publications, the Research Symposium on AI and Its Impact will be held on February 18, 2026, at Bharat Mandapam. The symposium will bring together leading researchers from India and the Global South, showcasing high-impact research and strengthening links between policy, research and real-world implementation. Together, these initiatives aim to anchor the India–AI Impact Summit 2026 in evidence-based insights, reinforcing India’s role as a global leader in responsible AI innovation.
Gmail Vs Zoho Mail Comparison: Why People Are Moving Away From Gmail? Check Security And Safety Features; Here’s How To Switch | Technology News
Gmail vs Zoho Mail Comparison: In the world of fast-paced technology, Email is something most people use every day, and for a long time. Gmail has been the most popular email service. People like it because it is easy to use and works well with other Google apps. Now, as we are heading towards new year 2026, things are begin to change. Some well-known people, including Home Minister Amit Shah, have reportedly switched from Gmail to Zoho Mail. This move has made many people think more about privacy, safety, and why other email services like Zoho Mail are becoming popular. Amid the recent buzz around the Arratai app, a homegrown messaging app by Zoho, the company’s email platform is also gaining attention, especially among professionals and organizations. It is important to note that switching from Gmail to Zoho Mail may feel like a big step, but the process is simpler than many people expect. Gmail vs Zoho Mail: Why People Are Choosing Zoho Mail? Add Zee News as a Preferred Source Gmail is equipped with many helpful features, but it also shows ads and is closely linked to other Google services. Some users feel their inbox looks cluttered and want a cleaner, simpler email experience. Others worry about privacy and prefer an email service that does not scan emails for ads. On the other hand, Zoho Mail offers a clean, ad-free inbox. The platform is mainly built for professionals, businesses, and users who want better control over their email and data. (Also Read: OnePlus 15R Launched In India With Qualcomm Snapdragon 8 Gen 5; Check Camera, Battery, Display, Price, Sale Date And , Bank Offers Other Specs) How To Transfer From Gmail To Zoho Mail Step 1: Create a Zoho Mail account: Visit the Zoho Mail website and sign up. You can choose a free plan or a paid plan based on your needs. Step 2: Enable IMAP in Gmail: Go to Gmail Settings > Forwarding and POP/IMAP, then turn on IMAP so Zoho can access your emails. Step 3: Open Zoho’s migration tool: In Zoho Mail settings, go to the Import/Export section and select the Migration Wizard. Step 4: Migrate your data: Use the Migration Wizard to import your emails, folders, and contacts from Gmail to Zoho Mail. Step 5: Set up email forwarding: In Gmail settings, enable forwarding to your new Zoho Mail address to avoid missing new emails. Step 6: Update contacts and accounts: Inform your contacts about your new email address and update it on banking, subscriptions, and social media services. Zoho Mail: Security And Safety Features Zoho Mail strongly focuses on security and safety. It provides encryption, powerful spam protection, and tools to help organisations manage emails securely. Users also get a calendar, notes, and a task manager, making it easy to handle all work-related tasks in one place.

India’s Digital Economy To Reach $1.2 Trillion By 2030, Led By AI Depth: Report | Technology News
India’s digital economy is projected to reach $1.2 trillion by 2029–30, as the depth of AI capabilities is expected to shape the next phase of growth, a report said on Friday. The report by TeamLease Digital said India’s AI market could touch $17 billion by 2027, with AI talent expected to double to nearly 1.25 million professionals, accounting for about 16 per cent of global AI talent. The growth is being driven by enterprise AI spending, national digital rails, and a strong STEM pipeline, the report said, adding that high-value AI roles are expanding rapidly while demand for legacy roles is plateauing. Add Zee News as a Preferred Source The firm identified six enterprise-grade AI skills emerging as foundational by 2026. These include Simulation Governance, which can fetch salaries of Rs 26–35 LPA; Agent Design with expected pay of Rs 25–32 LPA; AI Orchestration (Rs 24–30 LPA); Prompt Engineering (Rs 22–28 LPA); LLM Safety and Tuning (Rs 20–26 LPA); and AI Compliance and Risk Operations (Rs 18–24 LPA). Globally, up to 40 per cent of roles are expected to be impacted by AI, particularly in sectors such as IT services, healthcare, BFSI, and customer experience. The report emphasised that organisations are increasingly treating AI capability building as an enterprise-wide priority, extending beyond data science to leadership, operations, risk, and compliance, while prioritising broad-based upskilling and hybrid human–AI workflows. It added that the strongest demand is for enterprise-grade AI skills that support governance, trust, orchestration, and scalability, rather than generic AI roles. Demand for these skills is concentrated in hubs such as Bengaluru, Hyderabad, and Pune, driven by global capability centres, AI-first startups, and large enterprises across BFSI, healthcare, and manufacturing. The report noted that the importance of mid-level professionals is increasing, as they can bridge applied AI with governance, orchestration, and real-world business needs.



