

Samsung Galaxy S24 Ultra Price In India: If you are planning to buy the premium flagship smartphone before 2026 then this is the perfect time to grab the offer. Samsung’s Galaxy S24 Ultra is currently available on Flipkart at a heavy discount, bringing its effective price below Rs 75,000. The smartphone is offered in Titanium Gray and Titanium Black colour options. This makes the phone much more affordable, especially for buyers who skipped it earlier due to its high launch price. The discount offer gets even more attractive with exchange deals and added benefits, making it one of the best flagship smartphone deals available online right now. With its premium design, powerful performance, and advanced camera setup, the Galaxy S24 Ultra continues to be a top choice for Android users. However, the final price may change based on the selected variant and ongoing offers. Add Zee News as a Preferred Source Samsung Galaxy S24 Ultra Specifications The Samsung Galaxy S24 Ultra features a 6.8-inch Dynamic LTPO AMOLED 2X display with a 120Hz refresh rate and up to 2,600 nits of peak brightness. It runs on Android 14 and Samsung has promised seven major Android OS upgrades. The smartphone is powered by the Qualcomm Snapdragon 8 Gen 3 processor, paired with the Adreno 750 GPU for high-performance tasks. (Also Read: Redmi Pad 2 Pro India Launch Officially Confirmed; Likely to Come With World’s Biggest Battery; Check Expected Display, Chipset, Price, Camera And Other Specs) On the photography front, the device sports a quad rear camera setup comprising a 200MP primary sensor with OIS, a 50MP periscope telephoto lens, a 12MP ultra-wide camera, and a 10MP telephoto shooter with OIS. The Galaxy S24 Ultra is backed by a 5,000mAh battery and supports 45W wired fast charging. Samsung Galaxy S24 Ultra Discount Price In India The 12GB RAM variant with 256GB internal storage is now available in India for under Rs 75,000, including exchange benefits of up to Rs 57,400, depending on the condition of the old phone. The smartphone’s original price on Flipkart is listed at Rs 1,34,999. Adding further, select credit card users can get up to Rs 4,000 extra discount, which can further reduce the final price.

Rotary Position Embeddings for Long Context Length
Rotary Position Embeddings (RoPE) is a technique for encoding token positions in a sequence. It is widely used in many models and works well for standard context lengths. However, it requires adaptation for longer contexts. In this article, you will learn how RoPE is adapted for long context length. Let’s get started. Rotary Position Embeddings for Long Context LengthPhoto by Nastya Dulhiier. Some rights reserved. Overview This article is divided into two parts; they are: Simple RoPE RoPE for Long Context Length Simple RoPE Compared to the sinusoidal position embeddings in the original Transformer paper, RoPE mutates the input tensor using a rotation matrix: $$\begin{aligned}X_{n,i} &= X_{n,i} \cos(n\theta_i) – X_{n,\frac{d}{2}+i} \sin(n\theta_i) \\X_{n,\frac{d}{2}+i} &= X_{n,i} \sin(n\theta_i) + X_{n,\frac{d}{2}+i} \cos(n\theta_i)\end{aligned}$$ where $X_{n,i}$ is the $i$-th element of the vector at the $n$-th position of the sequence of tensor $X$. The length of each vector (also known as the hidden size or the model dimension) is $d$. The quantity $\theta_i$ is the frequency of the $i$-th element of the vector. It is computed as: $$\theta_i = \frac{1}{N^{2i/d}}$$ A simple implementation of RoPE looks like this: import torch import torch.nn as nn def rotate_half(x: torch.Tensor) -> torch.Tensor: “””Rotates half the hidden dims of the input. This is a helper function for rotary position embeddings (RoPE). For a tensor of shape (…, d), it returns a tensor where the last d/2 dimensions are rotated by swapping and negating. Args: x: Input tensor of shape (…, d) Returns: Tensor of same shape with rotated last dimension “”” x1, x2 = x.chunk(2, dim=-1) return torch.cat((-x2, x1), dim=-1) # Concatenate with rotation class RotaryPositionEncoding(nn.Module): “””Rotary position encoding.””” def __init__(self, dim: int, max_position_embeddings: int) -> None: “””Initialize the RotaryPositionEncoding module Args: dim: The hidden dimension of the input tensor to which RoPE is applied max_position_embeddings: The maximum sequence length of the input tensor “”” super().__init__() self.dim = dim self.max_position_embeddings = max_position_embeddings # compute a matrix of n\theta_i N = 10_000.0 inv_freq = 1.0 / (N ** (torch.arange(0, dim, 2).float() / dim)) inv_freq = torch.cat((inv_freq, inv_freq), dim=-1) position = torch.arange(max_position_embeddings).float() sinusoid_inp = torch.outer(position, inv_freq) # save cosine and sine matrices as buffers self.register_buffer(“cos”, sinusoid_inp.cos()) self.register_buffer(“sin”, sinusoid_inp.sin()) def forward(self, x: torch.Tensor) -> torch.Tensor: “””Apply RoPE to tensor x Args: x: Input tensor of shape (batch_size, seq_length, num_heads, head_dim) Returns: Output tensor of shape (batch_size, seq_length, num_heads, head_dim) “”” batch_size, seq_len, num_heads, head_dim = x.shape dtype = x.dtype # transform the cosine and sine matrices to 4D tensor and the same dtype as x cos = self.cos.to(dtype)[:seq_len].view(1, seq_len, 1, -1) sin = self.sin.to(dtype)[:seq_len].view(1, seq_len, 1, -1) # apply RoPE to x output = (x * cos) + (rotate_half(x) * sin) return output 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 import torch import torch.nn as nn def rotate_half(x: torch.Tensor) -> torch.Tensor: “”“Rotates half the hidden dims of the input. This is a helper function for rotary position embeddings (RoPE). For a tensor of shape (…, d), it returns a tensor where the last d/2 dimensions are rotated by swapping and negating. Args: x: Input tensor of shape (…, d) Returns: Tensor of same shape with rotated last dimension ““” x1, x2 = x.chunk(2, dim=–1) return torch.cat((–x2, x1), dim=–1) # Concatenate with rotation class RotaryPositionEncoding(nn.Module): “”“Rotary position encoding.”“” def __init__(self, dim: int, max_position_embeddings: int) -> None: “”“Initialize the RotaryPositionEncoding module Args: dim: The hidden dimension of the input tensor to which RoPE is applied max_position_embeddings: The maximum sequence length of the input tensor ““” super().__init__() self.dim = dim self.max_position_embeddings = max_position_embeddings # compute a matrix of n\theta_i N = 10_000.0 inv_freq = 1.0 / (N ** (torch.arange(0, dim, 2).float() / dim)) inv_freq = torch.cat((inv_freq, inv_freq), dim=–1) position = torch.arange(max_position_embeddings).float() sinusoid_inp = torch.outer(position, inv_freq) # save cosine and sine matrices as buffers self.register_buffer(“cos”, sinusoid_inp.cos()) self.register_buffer(“sin”, sinusoid_inp.sin()) def forward(self, x: torch.Tensor) -> torch.Tensor: “”“Apply RoPE to tensor x Args: x: Input tensor of shape (batch_size, seq_length, num_heads, head_dim) Returns: Output tensor of shape (batch_size, seq_length, num_heads, head_dim) ““” batch_size, seq_len, num_heads, head_dim = x.shape dtype = x.dtype # transform the cosine and sine matrices to 4D tensor and the same dtype as x cos = self.cos.to(dtype)[:seq_len].view(1, seq_len, 1, –1) sin = self.sin.to(dtype)[:seq_len].view(1, seq_len, 1, –1) # apply RoPE to x output = (x * cos) + (rotate_half(x) * sin) return output The code above defines a tensor inv_freq as the inverse frequency of the RoPE, corresponding to the frequency term $\theta_i$ in the formula. It is called inverse frequency in the RoPE literature because it is inversely proportional to the wavelength (i.e., the maximum distance) that RoPE can capture. When you multiply two vectors from positions $p$ and $q$, as you would do in the scaled-dot product attention, you find that the result depends on the relative position $p – q$ due to the trigonometric identities: $$\begin{aligned}\cos(a – b) = \cos(a) \cos(b) + \sin(a) \sin(b) \\\sin(a – b) = \sin(a) \cos(b) – \cos(a) \sin(b)\end{aligned}$$ In language models, relative position typically matters more than absolute position. Therefore, RoPE is often a better choice than the original sinusoidal position embeddings. RoPE for Long Context Length The functions $\sin kx$ and $\cos kx$ are periodic with period $2\pi/k$. In RoPE, the term $\theta_i$ is called the frequency term because it determines the periodicity. In a language model, the high-frequency terms are important because they help understand nearby words in a sentence. The low-frequency terms, however, are useful for understanding context that spans across multiple sentences. Therefore, when you design a model with a long context length, you want it to perform well for short sentences since they are more common, but you also want
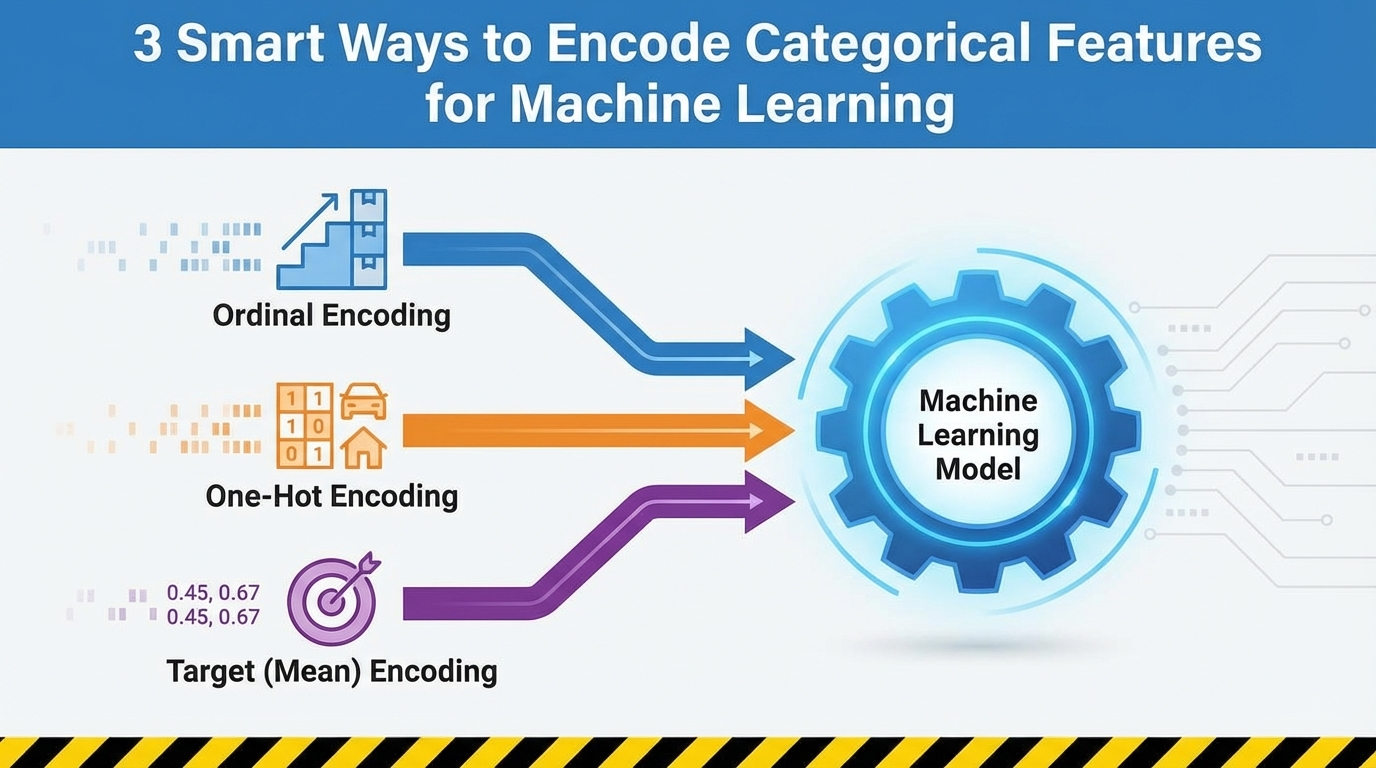
3 Smart Ways to Encode Categorical Features for Machine Learning
In this article, you will learn three reliable techniques — ordinal encoding, one-hot encoding, and target (mean) encoding — for turning categorical features into model-ready numbers while preserving their meaning. Topics we will cover include: When and how to apply ordinal (label-style) encoding for truly ordered categories. Using one-hot encoding safely for nominal features and understanding its trade-offs. Applying target (mean) encoding for high-cardinality features without leaking the target. Time to get to work. 3 Smart Ways to Encode Categorical Features for Machine LearningImage by Editor Introduction If you spend any time working with real-world data, you quickly realize that not everything comes in neat, clean numbers. In fact, most of the interesting aspects, the things that define people, places, and products, are captured by categories. Think about a typical customer dataset: you’ve got fields like City, Product Type, Education Level, or even Favorite Color. These are all examples of categorical features, which are variables that can take on one of a limited, fixed number of values. The problem? While our human brains seamlessly process the difference between “Red” and “Blue” or “New York” and “London,” the machine learning models we use to make predictions can’t. Models like linear regression, decision trees, or neural networks are fundamentally mathematical functions. They operate by multiplying, adding, and comparing numbers. They need to calculate distances, slopes, and probabilities. When you feed a model the word “Marketing,” it doesn’t see a job title; it just sees a string of text that has no numerical value it can use in its equations. This inability to process text is why your model will crash instantly if you try to train it on raw, non-numeric labels. The primary goal of feature engineering, and specifically encoding, is to act as a translator. Our job is to convert these qualitative labels into quantitative, numerical features without losing the underlying meaning or relationships. If we do it right, the numbers we create will carry the predictive power of the original categories. For instance, encoding must ensure that the number representing a high-level Education Level is quantitatively “higher” than the number representing a lower level, or that the numbers representing different Cities reflect their difference in purchase habits. To tackle this challenge, we have evolved smart ways to perform this translation. We’ll start with the most intuitive methods, where we simply assign numbers based on rank or create separate binary flags for each category. Then, we’ll move on to a powerful technique that uses the target variable itself to build a single, dense feature that captures a category’s true predictive influence. By understanding this progression, you’ll be equipped to choose the perfect encoding method for any categorical data you encounter. 3 Smart Ways to Encode Categorical Features for Machine Learning: A Flowchart (click to enlarge)Image by Editor 1. Preserving Order: Ordinal and Label Encoding The first, and simplest, translation technique is designed for categorical data that isn’t just a collection of random names, but a set of labels with an intrinsic rank or order. This is the key insight. Not all categories are equal; some are inherently “higher” or “more” than others. The most common examples are features that represent some sort of scale or hierarchy: Education Level: (High School => College => Master’s => PhD) Customer Satisfaction: (Very Poor => Poor => Neutral => Good => Excellent) T-shirt Size: (Small => Medium => Large) When you encounter data like this, the most effective way to encode it is to use Ordinal Encoding (often informally called “label encoding” when mapping categories to integers). The Mechanism The process is straightforward: you map the categories to integers based on their position in the hierarchy. You don’t just assign numbers randomly; you explicitly define the order. For example, if you have T-shirt sizes, the mapping would look like this: Original Category Assigned Numerical Value Small (S) 1 Medium (M) 2 Large (L) 3 Extra-Large (XL) 4 By doing this, you are teaching the machine that an XL (4) is numerically “more” than an S (1), which correctly reflects the real-world relationship. The difference between an M (2) and an L (3) is mathematically the same as the difference between an L (3) and an XL (4), a unit increase in size. This resulting single column of numbers is what you feed into your model. Introducing a False Hierarchy While Ordinal Encoding is the perfect choice for ordered data, it carries a major risk when misapplied. You must never use it on nominal (non-ordered) data. Consider encoding a list of colors: Red, Blue, Green. If you arbitrarily assign them: Red = 1, Blue = 2, Green = 3, your machine learning model will interpret this as a hierarchy. It will conclude that “Green” is twice as large or important as “Red,” and that the difference between “Blue” and “Green” is the same as the difference between “Red” and “Blue.” This is almost certainly false and will severely mislead your model, forcing it to learn non-existent numerical relationships. The rule here is simple and firm: use Ordinal Encoding only when there is a clear, defensible rank or sequence between the categories. If the categories are just names without any intrinsic order (like types of fruit or cities), you must use a different encoding technique. Implementation and Code Explanation We can implement this using the OrdinalEncoder from scikit-learn. The key is that we must explicitly define the order of the categories ourselves. from sklearn.preprocessing import OrdinalEncoder import numpy as np # Sample data representing customer education levels data = np.array([[‘High School’], [‘Bachelor\’s’], [‘Master\’s’], [‘Bachelor\’s’], [‘PhD’]]) # Define the explicit order for the encoder # This ensures that ‘Bachelor\’s’ is correctly ranked below ‘Master\’s’ education_order = [ [‘High School’, ‘Bachelor\’s’, ‘Master\’s’, ‘PhD’] ] # Initialize the encoder and pass the defined order encoder = OrdinalEncoder(categories=education_order) # Fit and transform the data encoded_data = encoder.fit_transform(data) print(“Original Data:\n”, data.flatten()) print(“\nEncoded Data:\n”, encoded_data.flatten()) 1 2 3 4 5 6 7 8 9 10 11 12

Truecaller’s Game Over? CNAP Will Show Caller Name Automatically On Your Phone; Check Key Differences And How To Check Activation | Technology News
CNAP Vs Truecaller In India: The Telecom Regulatory Authority of India (TRAI) has begun rolling out Calling Name Presentation, or CNAP, a feature that shows the real name of the caller on your phone screen before you answer the call. The name displayed is the one linked to the caller’s Aadhaar card, not a name saved by users or apps. The service has started rolling out in several telecom circles across India after the Telecom Regulatory Authority of India (TRAI) recommended its implementation earlier this year. CNAP In India: How It Works CNAP is a network-based service, not an app. This means users do not need to download anything or manually activate the feature. Once enabled by the telecom operator, it works automatically. In the first phase, CNAP has been launched on 4G and 5G networks. It will be extended to 2G networks in the coming months. The service is currently free of cost for users. Add Zee News as a Preferred Source CNAP In India: Which Telecom Operators Supports This Service Reliance Jio, Airtel, and Vodafone Idea have started rolling out the CNAP service in select telecom circles across India. Reliance Jio has enabled CNAP in Kerala, Bihar, Rajasthan, Punjab, Assam, Uttarakhand, West Bengal, Jharkhand, Odisha, UP East and West, and Himachal Pradesh. Airtel has activated the service in Gujarat, Madhya Pradesh, Maharashtra, Jammu And Kashmir, and West Bengal, while Vodafone Idea users can access CNAP in parts of Maharashtra and Tamil Nadu. The rollout is being carried out in phases, with more circles expected to be added in the coming weeks. How To Check CNAP Activation On Your Mobile Number To check CNAP status, dial *#31# from your phone’s dial pad. If the caller ID is shown as not restricted, it indicates that CNAP is active on the network. CNAP works only for incoming calls. When making outgoing calls, users will not see the recipient’s name, but their own registered name will be visible to the receiver. CNAP Vs Truecaller: Key Differences CNAP uses Aadhaar-linked telecom records as its data source, which means the caller name shown is based on official SIM registration details. It does not require any app and the displayed name cannot be edited by users. CNAP is a network-based service and currently does not provide spam alerts. On the other hand, the Truecaller relies on user-saved contacts for its data, requires an app to function, allows users to edit or remove their names, and offers spam call alerts, but it is not a network-based service. CNAP In India: Will This Service Stop Spam Calls? CNAP alone will not completely eliminate spam calls. While it shows the caller’s name, it does not flag calls as spam. Users still need to answer calls and manually block unwanted numbers. Telecom operators like Jio and Airtel currently offer separate spam detection services, which work alongside CNAP. CNAP In India: Can Users Opt Out From This Service? There are reports that users may be allowed to opt out by contacting their telecom operator or by using specific dial codes. However, telecom companies have not officially confirmed a universal opt-out option yet. CNAP in India: Why It Is Crucial For Users? CNAP helps users identify callers by showing verified names, reducing the need for third-party caller ID apps. However, the service is still limited, as issues like cross-network support and the lack of built-in spam alerts need to be resolved.

Pretraining a Llama Model on Your Local GPU
import dataclasses import os import datasets import tqdm import tokenizers import torch import torch.nn as nn import torch.nn.functional as F import torch.optim.lr_scheduler as lr_scheduler from torch import Tensor # Load the tokenizer tokenizer = tokenizers.Tokenizer.from_file(“bpe_50K.json”) # Load the dataset dataset = datasets.load_dataset(“HuggingFaceFW/fineweb”, “sample-10BT”, split=“train”) # Build the model @dataclasses.dataclass class LlamaConfig: “”“Define Llama model hyperparameters.”“” vocab_size: int = 50000 # Size of the tokenizer vocabulary max_position_embeddings: int = 2048 # Maximum sequence length hidden_size: int = 768 # Dimension of hidden layers intermediate_size: int = 4*768 # Dimension of MLP’s hidden layer num_hidden_layers: int = 12 # Number of transformer layers num_attention_heads: int = 12 # Number of attention heads num_key_value_heads: int = 3 # Number of key-value heads for GQA def rotate_half(x: Tensor) -> Tensor: “”“Rotates half the hidden dims of the input. This is a helper function for rotary position embeddings (RoPE). For a tensor of shape (…, d), it returns a tensor where the last d/2 dimensions are rotated by swapping and negating. Args: x: Input tensor of shape (…, d) Returns: Tensor of same shape with rotated last dimension ““” x1, x2 = x.chunk(2, dim=–1) return torch.cat((–x2, x1), dim=–1) # Concatenate with rotation class RotaryPositionEncoding(nn.Module): “”“Rotary position encoding.”“” def __init__(self, dim: int, max_position_embeddings: int) -> None: “”“Initialize the RotaryPositionEncoding module Args: dim: The hidden dimension of the input tensor to which RoPE is applied max_position_embeddings: The maximum sequence length of the input tensor ““” super().__init__() self.dim = dim self.max_position_embeddings = max_position_embeddings # compute a matrix of n\theta_i N = 10_000.0 inv_freq = 1.0 / (N ** (torch.arange(0, dim, 2).float() / dim)) inv_freq = torch.cat((inv_freq, inv_freq), dim=–1) position = torch.arange(max_position_embeddings).float() sinusoid_inp = torch.outer(position, inv_freq) # save cosine and sine matrices as buffers, not parameters self.register_buffer(“cos”, sinusoid_inp.cos()) self.register_buffer(“sin”, sinusoid_inp.sin()) def forward(self, x: Tensor) -> Tensor: “”“Apply RoPE to tensor x Args: x: Input tensor of shape (batch_size, seq_length, num_heads, head_dim) Returns: Output tensor of shape (batch_size, seq_length, num_heads, head_dim) ““” batch_size, seq_len, num_heads, head_dim = x.shape dtype = x.dtype # transform the cosine and sine matrices to 4D tensor and the same dtype as x cos = self.cos.to(dtype)[:seq_len].view(1, seq_len, 1, –1) sin = self.sin.to(dtype)[:seq_len].view(1, seq_len, 1, –1) # apply RoPE to x output = (x * cos) + (rotate_half(x) * sin) return output class LlamaAttention(nn.Module): “”“Grouped-query attention with rotary embeddings.”“” def __init__(self, config: LlamaConfig) -> None: super().__init__() self.hidden_size = config.hidden_size self.num_heads = config.num_attention_heads self.head_dim = self.hidden_size // self.num_heads self.num_kv_heads = config.num_key_value_heads # GQA: H_kv < H_q # hidden_size must be divisible by num_heads assert (self.head_dim * self.num_heads) == self.hidden_size # Linear layers for Q, K, V projections self.q_proj = nn.Linear(self.hidden_size, self.num_heads * self.head_dim, bias=False) self.k_proj = nn.Linear(self.hidden_size, self.num_kv_heads * self.head_dim, bias=False) self.v_proj = nn.Linear(self.hidden_size, self.num_kv_heads * self.head_dim, bias=False) self.o_proj = nn.Linear(self.num_heads * self.head_dim, self.hidden_size, bias=False) def forward(self, hidden_states: Tensor, rope: RotaryPositionEncoding, attn_mask: Tensor) -> Tensor: bs, seq_len, dim = hidden_states.size() # Project inputs to Q, K, V query_states = self.q_proj(hidden_states).view(bs, seq_len, self.num_heads, self.head_dim) key_states = self.k_proj(hidden_states).view(bs, seq_len, self.num_kv_heads, self.head_dim) value_states = self.v_proj(hidden_states).view(bs, seq_len, self.num_kv_heads, self.head_dim) # Apply rotary position embeddings query_states = rope(query_states) key_states = rope(key_states) # Transpose tensors from BSHD to BHSD dimension for scaled_dot_product_attention query_states = query_states.transpose(1, 2) key_states = key_states.transpose(1, 2) value_states = value_states.transpose(1, 2) # Use PyTorch’s optimized attention implementation # setting is_causal=True is incompatible with setting explicit attention mask attn_output = F.scaled_dot_product_attention( query_states, key_states, value_states, attn_mask=attn_mask, dropout_p=0.0, enable_gqa=True, ) # Transpose output tensor from BHSD to BSHD dimension, reshape to 3D, and then project output attn_output = attn_output.transpose(1, 2).reshape(bs, seq_len, self.hidden_size) attn_output = self.o_proj(attn_output) return attn_output class LlamaMLP(nn.Module): “”“Feed-forward network with SwiGLU activation.”“” def __init__(self, config: LlamaConfig) -> None: super().__init__() # Two parallel projections for SwiGLU self.gate_proj = nn.Linear(config.hidden_size, config.intermediate_size, bias=False) self.up_proj = nn.Linear(config.hidden_size, config.intermediate_size, bias=False) self.act_fn = F.silu # SwiGLU activation function # Project back to hidden size self.down_proj = nn.Linear(config.intermediate_size, config.hidden_size, bias=False) def forward(self, x: Tensor) -> Tensor: # SwiGLU activation: multiply gate and up-projected inputs gate = self.act_fn(self.gate_proj(x)) up = self.up_proj(x) return self.down_proj(gate * up) class LlamaDecoderLayer(nn.Module): “”“Single transformer layer for a Llama model.”“” def __init__(self, config: LlamaConfig) -> None: super().__init__() self.input_layernorm = nn.RMSNorm(config.hidden_size, eps=1e–5) self.self_attn = LlamaAttention(config) self.post_attention_layernorm = nn.RMSNorm(config.hidden_size, eps=1e–5) self.mlp = LlamaMLP(config) def forward(self, hidden_states: Tensor, rope: RotaryPositionEncoding, attn_mask: Tensor) -> Tensor: # First residual block: Self-attention residual = hidden_states hidden_states = self.input_layernorm(hidden_states) attn_outputs = self.self_attn(hidden_states, rope=rope, attn_mask=attn_mask) hidden_states = attn_outputs + residual # Second residual block: MLP residual = hidden_states hidden_states = self.post_attention_layernorm(hidden_states) hidden_states = self.mlp(hidden_states) + residual return hidden_states class LlamaModel(nn.Module): “”“The full Llama model without any pretraining heads.”“” def __init__(self, config: LlamaConfig) -> None: super().__init__() self.rotary_emb = RotaryPositionEncoding( config.hidden_size // config.num_attention_heads, config.max_position_embeddings, ) self.embed_tokens = nn.Embedding(config.vocab_size, config.hidden_size) self.layers = nn.ModuleList([LlamaDecoderLayer(config) for _ in range(config.num_hidden_layers)]) self.norm = nn.RMSNorm(config.hidden_size, eps=1e–5) def forward(self, input_ids: Tensor, attn_mask: Tensor) -> Tensor: # Convert input token IDs to embeddings hidden_states = self.embed_tokens(input_ids) # Process through all transformer layers, then the final norm layer for layer in self.layers: hidden_states = layer(hidden_states, rope=self.rotary_emb, attn_mask=attn_mask) hidden_states = self.norm(hidden_states) # Return the final hidden states return hidden_states class LlamaForPretraining(nn.Module): def __init__(self, config: LlamaConfig) -> None: super().__init__() self.base_model = LlamaModel(config) self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False) def forward(self, input_ids: Tensor, attn_mask: Tensor) -> Tensor: hidden_states = self.base_model(input_ids, attn_mask) return self.lm_head(hidden_states) def create_causal_mask(seq_len: int, device: torch.device, dtype: torch.dtype = torch.float32) -> Tensor: “”“Create a causal mask for self-attention. Args: seq_len: Length of the sequence device: Device to create the mask on dtype: Data type of the mask Returns: Causal mask of shape (seq_len, seq_len) ““” mask = torch.full((seq_len, seq_len), float(‘-inf’), device=device, dtype=dtype) \ .triu(diagonal=1) return mask def create_padding_mask(batch, padding_token_id, device: torch.device, dtype: torch.dtype = torch.float32) -> Tensor: “”“Create a padding mask for a batch of sequences for self-attention. Args: batch: Batch of sequences, shape (batch_size, seq_len) padding_token_id: ID of the padding token Returns: Padding mask of shape (batch_size, 1, seq_len, seq_len) ““” padded =

Redmi Pad 2 Pro India Launch Officially Confirmed; Likely to Come With World’s Biggest Battery; Check Expected Display, Chipset, Price, Camera And Other Specs | Technology News
Redmi Pad 2 Pro Price In India: Chinese smartphone brand Xiaomi’s sub-brand Redmi is all set to launch the Redmi Pad 2 Pro in India. The company has confirmed that the tablet will debut on January 6, alongside the Redmi Note 15 5G. However, the promotional teasers describe the tablet with the tagline “Everything Pro, On-the-Go.” The e-commerce giant Amazon listing also claims that the device will feature the world’s largest battery. Notably, the Redmi Pad 2 Pro was recently launched in select European markets with similar specifications and features. The tablet is offered in Lavender Purple, Silver, and Graphite Gray colour options. Redmi Pad 2 Pro Tablet Specifications (Expected) Add Zee News as a Preferred Source The tablet is expected to feature a 12.1-inch LCD display with a 2.5K resolution and a 120Hz refresh rate. It is tipped to be powered by the Snapdragon 7s Gen 4 chipset, paired with an Adreno 810 GPU, and backed by a large 12,000mAh battery. The display may offer up to 600 nits of brightness, ensuring comfortable use indoors and in well-lit conditions. On the software front, the tablet is likely to run Android 15 with Xiaomi’s HyperOS 2 on top. On the photography front, the Wi-Fi variant could come with an 8MP rear camera, while the 5G model may feature a 13MP rear shooter. Both versions are expected to include an 8MP front camera, with all cameras supporting 1080p video recording. Adding further, the tablet comes with a quad-speaker system that supports Dolby Atmos, Hi-Res Audio, and offers up to a 300% audio boost for louder, clearer sound. (Also Read: Tech Layoffs In 2025 Cross 50,000 Mark: From Microsoft To Amazon, Check List of Biggest Tech Companies That Cited AI In Job Cuts) Redmi Pad 2 Pro Price In India (Expected) The Redmi Pad 2 Pro 5G was introduced in select global markets with a starting price of EUR 379.9 (around Rs 40,000) for the 6GB RAM + 128GB storage model. In India, the tablet is also expected to be priced at around Rs 40,000 for the same variant. Notably, both the e-commerce giants Amazon and Flipkart have gone live with dedicated landing pages for the product.

DoT’s Financial Fraud Risk Indicator Helps Prevent Rs 660 Crore In Cyber Fraud In 6 Months- Details Here | Technology News
New Delhi: The Financial Fraud Risk Indicator (FRI) has helped prevent the financial loss of Rs 660 crore in cyber fraud across the banking ecosystem in just six months since its rollout, the Department of Telecommunications (DoT) said on Monday. The FRI is driven by active support of the Reserve Bank of India (RBI) and the National Payments Corporation of India (NPCI), leading to large-scale onboarding of banks, financial institutions, and Third-Party Application Providers (TPAPs) on the Digital Intelligence Platform (DIP). As on date, more than 1,000 banks, TPAPs, and Payment System Operators (PSOs), have onboarded the DIP and started adopting FRI actively. DoT is also conducting regular knowledge-sharing sessions with stakeholders to enhance awareness and effective implementation of FRI, with 16 sessions held till date, according to the Ministry of Communications. Add Zee News as a Preferred Source India’s cybercrime landscape has shifted dramatically in recent years, with fraudsters operating like well-organized digital cartels. From digital arrest scams to sophisticated SIM-box networks bypassing legal telecom routes, the threat is evolving faster than ever. Yet, amid this complexity, one factor has emerged as the most decisive force in combating cybercrime: Jan Bhagidari. Citizens, through Sanchar Saathi, which has emerged as India’s most powerful crowdsourced cyber-intelligence tool, are providing continuous inputs for Financial Fraud Risk Indicator. DoT acknowledges and appreciates the efforts of all vigilant citizens and Cyber Warriors who are actively leveraging the Sanchar Saathi platform (available at www.sancharsaathi.gov.in and through mobile App on both Android and iOS) to report Suspected Fraud Communications, report fraudulent connections obtained in their name, and lost/stolen mobile handsets. The recent trends in downloads and usage of the Sanchar Saathi mobile App reflects the trust reposed by citizens in the platform and their proactive role in preventing cyber frauds. This large-scale citizen engagement is significantly contributing in curtailing the misuse of telecom resources by fraudsters and creating a safer and more resilient digital ecosystem. “DoT urges all the citizens to utilise Sanchar Saathi web portal and Mobile App for availing the citizen centric services. DoT reiterates its commitment to fostering a secure digital payments ecosystem through inter-agency collaboration, proactive fraud detection, and intelligence-driven policy interventions,” said the ministry.

Tech Layoffs In 2025 Cross 50,000 Mark: From Microsoft To Amazon, Check List of Biggest Tech Companies That Cited AI In Job Cuts | Technology News
Tech Layoffs In 2025: As we all know, artificial intelligence (AI) is changing the way we work around the world. In 2025, its impact on tech employees has been both exciting and concerning. On one hand, AI and machine learning tools are helping workers complete tasks faster and smarter, boosting productivity like never before. On the other hand, the rapid rise of automation is replacing human roles, creating uncertainty in the job market. This year, layoffs have become a major trend, with several big companies like Amazon, Microsoft, IBM, Salesforce and more are cutting thousands of jobs due to the growing use of AI. Moreover, the big tech firms like Google, CrowdStrike, Meta, and others have continued with smaller, steady cuts across the year. Hence, the employers are now facing the challenge of adapting to this new reality. According to Layoffs.fyi, so far this year, 122,549 tech employees have lost their jobs across 257 technology companies. Out of these, more than 54,000 job cuts in the US are directly linked to the rise of AI. Let’s have a quick look on the big tech firms that directly connected layoffs to the adoption of AI. Add Zee News as a Preferred Source Microsoft Microsoft has reportedly cut a total of 15,000 jobs in 2025. In its latest announcement in July, the company said it would eliminate 9,000 positions, which is about four percent of its global workforce. Earlier, in May, Microsoft laid off over 6,000 employees, followed by around 300 more in June. This is the company’s second largest round of mass layoffs, after it cut nearly 18,000 jobs in 2014. The layoffs affected workers across different countries and experience levels. Even Microsoft’s gaming division, including Xbox, was impacted. Amazon In October this year, e-commerce giant Amazon announced it will lay off at least 14,000 employees, with more cuts expected next year. Around 1,000 workers in India are likely to be affected. These layoffs, part of a wider trend, give an early look at how AI is affecting workforces in 2025. Salesforce Salesforce cut about 4,000 customer service jobs this year. Executives said AI agents are now handling much of the customer support work. CEO Marc Benioff confirmed these layoffs in September. Salesforce CEO Marc Benioff had revealed over the summer that AI was already doing up to 50% of the work at the company. Global Tech Giant IBM In November 2025, IBM announced it will lay off thousands of employees before the year ends. The company said the job cuts would be a “low single-digit percentage” of its global workforce. With around 270,000 employees worldwide, even a one percent reduction could mean at least 2,700 jobs lost. Cybersecurity Firm CrowdStrike In May 2025, cybersecurity company CrowdStrike announced it would lay off about 5 percent of its workforce, around 500 employees. The company said AI was the main reason for these job cuts. Intel Intel, a major American multinational technology company, has announced it will cut up to 24,000 jobs by the end of 2025 as part of a major restructuring driven by AI and automation. Language learning app Duolingo also said it will reduce contractors, pointing to AI taking over tasks that humans used to do. TCS IT firm TCS laid off 12,000 employees, about 2 percent of its global workforce. The job cuts mainly affected mid- and senior-level staff. The company said the move was aimed at creating a future-ready workforce through reskilling and redeployment.

Want Free Wi-Fi At Delhi Airport? How To Connect With Or Without Indian Number And What Makes It Safe For Travellers | Technology News
Free Wi-Fi At Delhi Airport Terminal 3: In the world of fast-paced digital world, staying connected has become a necessity rather than a luxury, especially while travelling. Whether it is checking flight updates, navigating terminals, responding to work emails, or staying in touch with loved ones, reliable internet access plays an important role in ensuring a smooth travel experience. Understanding this growing need, Delhi Airport has taken a traveller-friendly step by offering free Wi-Fi to all passengers. The service helps flyers stay online without worrying about high roaming charges or weak mobile networks. From business travellers to leisure passengers, free Wi-Fi at Delhi Airport makes waiting time more productive, convenient, and stress-free. Now, the process to connect to Wi-Fi is very easy, even for international visitors, and needs very little information. Passengers can quickly connect to the Wi-Fi and stay online while they are at the airport. This helps them stay connected with the world and makes their travel experience simple, comfortable, and stress-free. Add Zee News as a Preferred Source The procedure to connect to Wi-Fi, even for an international visitor, is very easy and requires less paperwork. Passengers can connect to the Wi-Fi and stay connected to the world, even when they are at the Delhi airport, making their travel experience stress-free and convenient. Free Wi-Fi At Delhi Airport: How Foreign Travellers Can Connect Without an Indian Number Step 1: Go to the nearest Information Desk or a self-service Wi-Fi kiosk at the airport. Step 2: Scan your passport at the kiosk or show it to the staff at the Information Desk. Step 3: The system or staff will give you a special Wi-Fi coupon code. Step 4: Open your device browser and connect to the airport Wi-Fi network. Step 5: Enter your KYC details and the coupon code in the browser pop-up. Step 6: Follow the on-screen instructions to complete the connection and start using Wi-Fi. Free Wi-Fi At Delhi Airport: How To Connect Free WiFi At Delhi Airport With Indian number Step 1: Open the Wi-Fi settings on your device and select GMR FREE WIFI. Step 2: Once connected, a browser window will open automatically. Step 3: Enter your Indian mobile number to receive a One Time Password (OTP). Step 4: Check your phone for the OTP sent via SMS. Step 5: Enter the OTP in the browser to confirm the connection. Step 6: Enjoy high-speed free Wi-Fi across all terminals at Delhi Airport. Also Read: Samsung Galaxy S26 Ultra Gets BIS Battery Certification; Check Expected Camera, Display, Processor, Price And India Launch Date What Makes Delhi Airport’s Free Wi-Fi Safe For Travellers Delhi Airport ensures safe and reliable Wi-Fi access for all travellers through a secure and well-managed network. Passengers can use the Wi-Fi for browsing the internet, streaming videos, and sending emails without interruptions. To keep the network secure, users must complete authentication through OTP or KYC verification. Travellers are advised to connect only to official airport Wi-Fi access points to protect their personal information. All logged connections follow regulatory guidelines, ensuring a safe online environment. These measures together provide a smooth, secure, and hassle-free internet experience at the airport.

Who Is Mustafa Suleyman? The Microsoft AI CEO Calling For Limits On Autonomous AI | Technology News
Microsoft AI chief Mustafa Suleyman has cautioned that the company is prepared to abandon any artificial intelligence system that shows signs of operating beyond human control. Speaking in an interview with Bloomberg, Suleyman outlined Microsoft’s vision for what he calls “humanist superintelligence”, AI designed to advance human interests rather than act independently. He stressed that Microsoft would not move forward with technologies that pose risks of slipping out of the company’s oversight, underlining that strong alignment with human values and effective containment measures are non negotiable conditions before any highly advanced AI tools are released. The remarks come amid a shifting landscape for Microsoft, which recently exited contractual limitations tied to OpenAI that had earlier restricted it from building its own artificial general intelligence models. Suleyman made it clear that he does not support the industry’s race to market mindset, noting that Microsoft’s current priority is to balance innovation with caution, rather than pushing powerful AI systems out too quickly. Add Zee News as a Preferred Source Microsoft AI CEO On Whether Startups Can Rival Big Tech Further, Suleyman revealed that his mission is also to make the company “Self Sufficient” in developing frontier AI Models. For such a development, the massive costs tied to advancing artificial intelligence make it difficult to say if startups can truly go head to head with Big Tech companies. Rather than “winning” the AGI race, Microsoft’s real focus is AI self-sufficiency. pic.twitter.com/ZdlXNZcQkL Peter H. Diamandis, MD (@PeterDiamandis) December 17, 2025 He pointed out that uncertainty in the sector is fuelling inflated valuations. “That ambiguity is what’s driving the frothiness,” Suleyman noted, adding that if there is a sudden leap in intelligence, multiple players could reach the same level at the same time. However, he stressed that operating at the highest level of AI development will require enormous financial backing. According to Suleyman, competing at the top tier could cost “hundreds of billions of dollars” over the next five to ten years. These expenses include what Microsoft spends on top researchers and technical staff. Given this scale of investment, Suleyman said it becomes clear that being part of a large corporation offers a significant structural edge one that companies like Microsoft already possess. Suleyman also likened Microsoft’s current scale to that of a “modern construction company,” where hundreds of thousands of workers are effectively building vast computing capacity from gigawatts of CPUs to advanced AI accelerators. He acknowledged that remaining competitive in the AI race comes at a steep cost, one the company is able to shoulder because of its deep financial strength. Microsoft recently posted $77.7 billion in quarterly revenue and now commands a market capitalisation of around $3.54 trillion, giving it the resources needed to fund massive infrastructure buildouts and talent acquisition. Beyond Microsoft, other major technology firms are also prepared to pour billions into AI development, as per TOI reports. In September, Meta CEO Mark Zuckerberg said he would rather risk “overspending by a couple of hundred billion dollars” than fall behind in the race toward superintelligence. He warned that if superintelligence arrives sooner than expected and a company moves too slowly, it could find itself on the sidelines of what he described as the most critical technology driving future products, innovation, value creation and historical impact. As a result, enormous sums are now being channelled into AI focused data centres. Over the past few months, tech giants including Microsoft, Meta, Google and Amazon have ramped up spending on cloud infrastructure required to build and operate next-generation AI models.



