

Third-Party Apps Dangerous: Imagine scrolling through your smartphone, looking for the perfect app to make your life easier, whether it is a new camera filter, a music streaming tool, or a handy payment app. A simple download can open up so many possibilities, but not every app on your Android or iPhone is safe. Applications made by your phone’s manufacturer, called first-party apps, are generally secure. Third-party applications are created by other developers and can be risky. Downloading them from unofficial sources could put your personal data and even your bank account at serious risk. First-Party Vs Third-Party Apps: Difference Add Zee News as a Preferred Source Third-party apps are applications that are not developed by your phone’s manufacturer or the operating system provider. Unlike first-party apps, which are made by companies like Apple, Samsung, or Google and are generally secure, third-party apps are created by independent developers or external companies. They are often available on official app stores like Google Play Store or Apple App Store and can offer extra features that native apps do not provide. However, downloading third-party apps from unofficial sources can be risky, as they may steal personal data, install malware, or compromise your device’s security. Essentially, any app outside the manufacturer’s official apps is considered a third-party app, but its safety depends entirely on its source. (Also Read: Third-Party Apps, Third-Party App Download, Third-Party App Risk, Mobile Security Alert, iPhone ) Third-Party Applications Benefits Third-party apps often bridge the gaps left by a smartphone’s native applications, offering features that enhance functionality and user experience. For instance, camera apps from external developers may provide advanced filters, manual controls, and editing tools unavailable in built-in apps. Similarly, third-party apps for music, payments, or productivity give users greater flexibility and customization. By expanding the capabilities of smartphones, these apps allow consumers to tailor their devices to their specific needs, making them an essential part of modern mobile life. Hidden Risks Of Third-Party Apps While third-party apps can enhance a smartphone’s functionality, they also come with significant risks. Apps downloaded from unofficial sources may contain malware that can steal personal information, including contacts, messages, photos, and even banking details. Some apps, disguised as games or editing tools, run in the background to collect sensitive data without users’ knowledge. In extreme cases, they can compromise device security, enable unauthorized access to financial transactions, or facilitate surveillance. Even apps on official stores are not completely risk-free, as past incidents have shown that some popular applications have faced allegations of data misuse and national security concerns. (Also Read: YouTube Earnings In India: How Much Creators Earn Per 1,000 Views, Top Creator Secrets, And Monetization Rules Revealed) How To Stay Safe While Downloading Third-Party Apps Downloading third-party apps can be risky, but there are steps you can take to stay safe. Always use official sources like the Google Play Store or Apple App Store and avoid downloading APK files from unknown websites or links. Check app reviews and ratings before installing. If users report fraud or poor performance, skip the app. Pay attention to the permissions the app requests. For example, a calculator asking for access to your contacts or location is a red flag. Finally, keep apps updated regularly, as developers often release security updates to fix vulnerabilities.

Elon Musk Seeks Up To $134bn From OpenAI, Microsoft In Damages Over Fraudulent Partnership | Technology News
New Delhi: Tesla CEO and founder of AI firm xAI Elon Musk has asked a US federal court to award him $79 billion to $134 billion in damages, alleging that OpenAI and Microsoft defrauded him by abandoning OpenAI’s nonprofit mission and partnering with the software giant. Elon Musk’s lawyers filed the damages request a day after a judge denied OpenAI and Microsoft’s final bid to avoid a jury trial scheduled for late April in Oakland, California, according to multiple reports. The filing cited calculations that showed Musk is entitled to a share of OpenAI’s current $500 billion valuation as he donated $38 million in seed funding during the founding stage of the company in 2015. “Just as an early investor in a startup company may realise gains many orders of magnitude greater than the investor’s initial investment, the wrongful gains that OpenAI and Microsoft have earned — and which Musk is now entitled to disgorge — are much larger than Musk’s initial contributions,” the filing said. Add Zee News as a Preferred Source According to court papers, Musk’s side argued that $65.5 billion to $109.43 billions of alleged wrongful gains were made by OpenAI and $13.3 billion to $25.06 billion by Microsoft from Musk’s financial and non-monetary contributions, including technical and business advice. OpenAI and Microsoft have denied the allegations. Musk left OpenAI’s board in 2018, launched his own AI company in 2023, and sued OpenAI in 2024, challenging co-founder Sam Altman’s move to operate the company as a for‑profit entity. “Musk’s lawsuit continues to be baseless and a part of his ongoing pattern of harassment, and we look forward to demonstrating this at trial,” OpenAI said in a statement, adding, “this latest unserious demand is aimed solely at furthering this harassment campaign.” Meanwhile, Musk’s AI firm xAI is also suing Apple and OpenAI over an earlier integration of ChatGPT into Siri and Apple Intelligence as an optional add-on. Elon Musk alleged that Apple’s App Store practices disadvantage rivals such as Grok, and the lawsuit has survived initial dismissal.

Google Fast Pair Flaw: Earbuds, And Headphones At Risk Of Hacking And Tracking; Here’s How To Stay Protected | Technology News
Google Fast Pair Flaw: Imagine plugging in your favourite wireless earbuds, headphones or using a smart speaker, thinking you are just enjoying music or catching up on a podcast, but someone could be listening in. Google designed a wireless protocol called Fast Pair to make connecting Bluetooth devices to Android and ChromeOS easy with a single tap. Now, researchers at KU Leuven University in Belgium have discovered that the same protocol can also allow hackers to connect just as easily to hundreds of millions of earbuds, headphones, and speakers, putting users’ privacy at risk. The vulnerability is so severe that it can let hackers access your device wirelessly, track your movements, or even eavesdrop on private conversations. The concerning part is that most users do not know their devices need an urgent update. While these gadgets make life convenient, this patch is a crucial reminder that even our most trusted technology can have hidden risks, and staying protected requires action. (Also Read: WhatsApp New Feature: Users May Soon Add Profile Cover Photos Like Facebook And LinkedIn; Check Privacy Features) Add Zee News as a Preferred Source What Is Google Fast Pair It is a technology developed by Google to make connecting Bluetooth devices, like earbuds, headphones, and speakers, to Android and ChromeOS devices extremely fast and simple. Instead of going through the usual Bluetooth pairing steps, Fast Pair allows your device to detect compatible gadgets nearby and connect with just one tap. The Google fast pair also automatically syncs the device across your Google account, so you do not need to pair it separately with multiple devices. The result is an enormous collection of Fast Pair-compatible audio devices that could allow a spy or stalker to take control of speakers and microphones or, in some cases, track an unwitting target’s location, even if the victim is an iPhone user who has never owned a Google product. WhisperPair: The Hidden Threat in Your Bluetooth Devices Researchers at the Computer Security and Industrial Cryptography group of Belgium’s KU Leuven University have discovered that improper implementations of Fast Pair can be exploited in a series of attacks called WhisperPair. These attacks allow hackers to take control of vulnerable accessories. WhisperPair can be used to track users if their devices support Google’s Find Hub network and have never been paired with an Android device. The issue, tracked as CVE-2025-36911, is caused by a logic error in the key-based pairing code, where devices fail to check if they are in pairing mode. This flaw lets attackers within a range of up to 14 meters start the pairing process and complete the Fast Pair connection in seconds, effectively gaining access to the device. (Also Read: YouTube Earnings In India: How Much Creators Earn Per 1,000 Views, Top Creator Secrets, And Monetization Rules Revealed) How To Protect Your Wireless Earbuds Or Bluetooth Devices From Hacking Pointer 1: Always keep your Bluetooth devices and apps updated to fix security problems. Pointer 2: Turn off Bluetooth when you are not using it to prevent unwanted connections. Pointer 3: Avoid pairing your devices in public places where hackers could be nearby. Pointer 4: Only connect to trusted devices and remove old or unused devices from your list. Pointer 5: Watch for unusual behavior, like strange connections or fast battery drain, which could be signs of hacking.
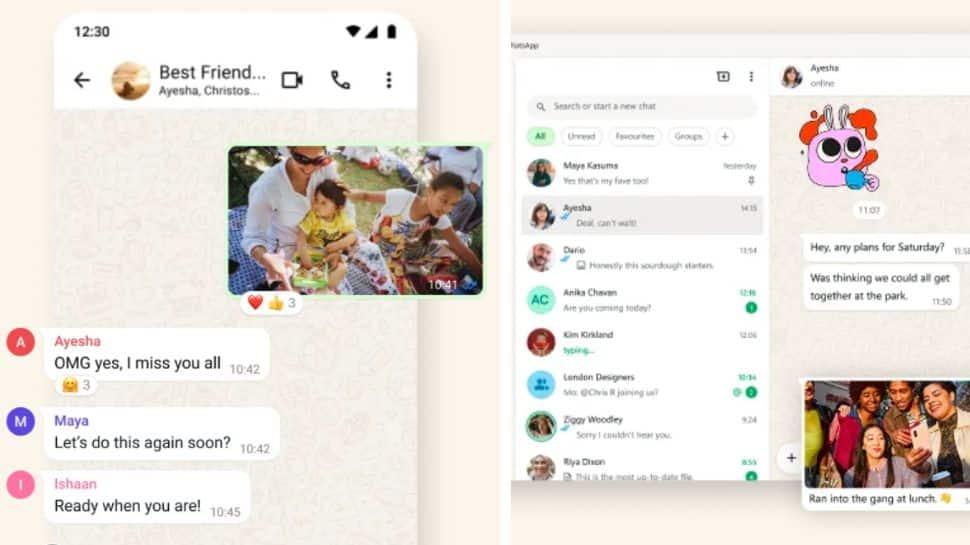
WhatsApp New Feature: Users May Soon Add Profile Cover Photos Like Facebook And LinkedIn; Check Privacy Features | Technology News
WhatsApp New Feature In 2026: Meta-owned platform WhatsApp is always adding new features to make chatting more interesting. Now, imagine opening a chat and seeing not only a profile picture but also a cover photo that shows more about the person. Just like Facebook and LinkedIn, WhatsApp is working on a new profile feature, according to a post by feature tracker WABetaInfo. This feature may allow users to add a cover photo to their profile. If introduced, it could help people express themselves better and make profiles more personal and engaging. As we all know, profile pictures and cover photos play an important role in personalising social networking accounts. Until now, cover photos were limited to WhatsApp Business accounts. However, the instant messaging platform now appears to be working on bringing this feature to all users, allowing everyone to customise their profiles in a more expressive way. According to reports, the feature is under development for both iOS and Android versions of the app and remains in the testing stage. (Also Read: YouTube Earnings In India: How Much Creators Earn Per 1,000 Views, Top Creator Secrets, And Monetization Rules Revealed) Add Zee News as a Preferred Source WhatsApp beta for Android 2.25.32.2: what’s new? WhatsApp is working on a feature that allows users to set a cover photo for their profile, and it will be available in a future update!https://t.co/LzJmwiwQMq pic.twitter.com/ShdX6nCwe5 — WABetaInfo (@WABetaInfo) October 28, 2025 WhatsApp Profile Cover Photo: What To Expect The new feature will introduce a new space in the profile section where users can add a wide image above their existing profile details. This cover photo will appear above the profile picture, name, and About section, giving users another way to share visual content. Users will be able to choose an image directly from their phone’s gallery and remove it whenever they want. The messaging platform will also offer privacy options for the cover photo. Users can choose to show it to everyone, only to saved contacts, or hide it from all users. There will also be an option to hide the cover photo from specific contacts, giving users better control over their profile visibility. WhatsApp Privacy Features Users can take several steps to improve their privacy and security on WhatsApp. Using the privacy checkup helps control what others can see on your profile, while enabling disappearing messages reduces long-term exposure of chats. Adding two-step verification with a security PIN protects the account from unauthorised access. Users can also lock the app and specific chats for extra safety. Turning on advanced security settings, including Advanced Chat Privacy, helps prevent misuse of content. Disabling read receipts gives more control over visibility, and stopping automatic media downloads protects both storage and personal privacy.

The Complete Guide to Data Augmentation for Machine Learning
In this article, you will learn practical, safe ways to use data augmentation to reduce overfitting and improve generalization across images, text, audio, and tabular datasets. Topics we will cover include: How augmentation works and when it helps. Online vs. offline augmentation strategies. Hands-on examples for images (TensorFlow/Keras), text (NLTK), audio (librosa), and tabular data (NumPy/Pandas), plus the critical pitfalls of data leakage. Alright, let’s get to it. The Complete Guide to Data Augmentation for Machine LearningImage by Author Suppose you’ve built your machine learning model, run the experiments, and stared at the results wondering what went wrong. Training accuracy looks great, maybe even impressive, but when you check validation accuracy… not so much. You can solve this issue by getting more data. But that is slow, expensive, and sometimes just impossible. It’s not about inventing fake data. It’s about creating new training examples by subtly modifying the data you already have without changing its meaning or label. You’re showing your model the same concept in multiple forms. You are teaching what’s important and what can be ignored. Augmentation helps your model generalize instead of simply memorizing the training set. In this article, you’ll learn how data augmentation works in practice and when to use it. Specifically, we’ll cover: What data augmentation is and why it helps reduce overfitting The difference between offline and online data augmentation How to apply augmentation to image data with TensorFlow Simple and safe augmentation techniques for text data Common augmentation methods for audio and tabular datasets Why data leakage during augmentation can silently break your model Offline vs Online Data Augmentation Augmentation can happen before training or during training. Offline augmentation expands the dataset once and saves it. Online augmentation generates new variations every epoch. Deep learning pipelines usually prefer online augmentation because it exposes the model to effectively unbounded variation without increasing storage. Data Augmentation for Image Data Image data augmentation is the most intuitive place to start. A dog is still a dog if it’s slightly rotated, zoomed, or viewed under different lighting conditions. Your model needs to see these variations during training. Some common image augmentation techniques are: Rotation Flipping Resizing Cropping Zooming Shifting Shearing Brightness and contrast changes These transformations do not change the label—only the appearance. Let’s demonstrate with a simple example using TensorFlow and Keras: 1. Importing Libraries import tensorflow as tf from tensorflow.keras.datasets import mnist from tensorflow.keras.layers import Dense, Flatten, Conv2D, MaxPooling2D, Dropout from tensorflow.keras.utils import to_categorical from tensorflow.keras.preprocessing.image import ImageDataGenerator from tensorflow.keras.models import Sequential import tensorflow as tf from tensorflow.keras.datasets import mnist from tensorflow.keras.layers import Dense, Flatten, Conv2D, MaxPooling2D, Dropout from tensorflow.keras.utils import to_categorical from tensorflow.keras.preprocessing.image import ImageDataGenerator from tensorflow.keras.models import Sequential 2. Loading MNIST dataset (X_train, y_train), (X_test, y_test) = mnist.load_data() # Normalize pixel values X_train = X_train / 255.0 X_test = X_test / 255.0 # Reshape to (samples, height, width, channels) X_train = X_train.reshape(-1, 28, 28, 1) X_test = X_test.reshape(-1, 28, 28, 1) # One-hot encode labels y_train = to_categorical(y_train, 10) y_test = to_categorical(y_test, 10) (X_train, y_train), (X_test, y_test) = mnist.load_data() # Normalize pixel values X_train = X_train / 255.0 X_test = X_test / 255.0 # Reshape to (samples, height, width, channels) X_train = X_train.reshape(–1, 28, 28, 1) X_test = X_test.reshape(–1, 28, 28, 1) # One-hot encode labels y_train = to_categorical(y_train, 10) y_test = to_categorical(y_test, 10) Output: Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/mnist.npz Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/mnist.npz 3. Defining ImageDataGenerator for augmentation datagen = ImageDataGenerator( rotation_range=15, # rotate images by ±15 degrees width_shift_range=0.1, # 10% horizontal shift height_shift_range=0.1, # 10% vertical shift zoom_range=0.1, # zoom in/out by 10% shear_range=0.1, # apply shear transformation horizontal_flip=False, # not needed for digits fill_mode=”nearest” # fill missing pixels after transformations ) datagen = ImageDataGenerator( rotation_range=15, # rotate images by ±15 degrees width_shift_range=0.1, # 10% horizontal shift height_shift_range=0.1, # 10% vertical shift zoom_range=0.1, # zoom in/out by 10% shear_range=0.1, # apply shear transformation horizontal_flip=False, # not needed for digits fill_mode=‘nearest’ # fill missing pixels after transformations ) 4. Building a Simple CNN Model model = Sequential([ Conv2D(32, (3, 3), activation=’relu’, input_shape=(28, 28, 1)), MaxPooling2D((2, 2)), Conv2D(64, (3, 3), activation=’relu’), MaxPooling2D((2, 2)), Flatten(), Dropout(0.3), Dense(64, activation=’relu’), Dense(10, activation=’softmax’) ]) model.compile(optimizer=”adam”, loss=”categorical_crossentropy”, metrics=[‘accuracy’]) model = Sequential([ Conv2D(32, (3, 3), activation=‘relu’, input_shape=(28, 28, 1)), MaxPooling2D((2, 2)), Conv2D(64, (3, 3), activation=‘relu’), MaxPooling2D((2, 2)), Flatten(), Dropout(0.3), Dense(64, activation=‘relu’), Dense(10, activation=‘softmax’) ]) model.compile(optimizer=‘adam’, loss=‘categorical_crossentropy’, metrics=[‘accuracy’]) 5. Training the model batch_size = 64 epochs = 5 history = model.fit( datagen.flow(X_train, y_train, batch_size=batch_size, shuffle=True), steps_per_epoch=len(X_train)//batch_size, epochs=epochs, validation_data=(X_test, y_test) ) batch_size = 64 epochs = 5 history = model.fit( datagen.flow(X_train, y_train, batch_size=batch_size, shuffle=True), steps_per_epoch=len(X_train)//batch_size, epochs=epochs, validation_data=(X_test, y_test) ) Output: 6. Visualizing Augmented Images import matplotlib.pyplot as plt # Visualize five augmented variants of the first training sample plt.figure(figsize=(10, 2)) for i, batch in enumerate(datagen.flow(X_train[:1], batch_size=1)): plt.subplot(1, 5, i + 1) plt.imshow(batch[0].reshape(28, 28), cmap=’gray’) plt.axis(‘off’) if i == 4: break plt.show() import matplotlib.pyplot as plt # Visualize five augmented variants of the first training sample plt.figure(figsize=(10, 2)) for i, batch in enumerate(datagen.flow(X_train[:1], batch_size=1)): plt.subplot(1, 5, i + 1) plt.imshow(batch[0].reshape(28, 28), cmap=‘gray’) plt.axis(‘off’) if i == 4: break plt.show() Output: Data Augmentation for Textual Data Text is more delicate. You can’t randomly replace words without thinking about meaning. But small, controlled changes can help your model generalize. A simple example using synonym replacement (with NLTK): import nltk from nltk.corpus import wordnet import random nltk.download(“wordnet”) nltk.download(“omw-1.4”) def synonym_replacement(sentence): words = sentence.split() if not words: return sentence idx = random.randint(0, len(words) – 1) synsets = wordnet.synsets(words[idx]) if synsets and synsets[0].lemmas(): replacement = synsets[0].lemmas()[0].name().replace(“_”, ” “) words[idx] = replacement return ” “.join(words) text = “The movie was really good” print(synonym_replacement(text)) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 import nltk from nltk.corpus import wordnet import random nltk.download(“wordnet”) nltk.download(“omw-1.4”) def synonym_replacement(sentence): words = sentence.split() if

iQOO Z11 Turbo Launched With 7,600mAh Battery, 100W Fast Charging, And More – Check Price, Colours, Variants | Technology News
iQOO Z11 Turbo: The Chinese smartphone maker iQOO has launched the iQOO Z11 Turbo in China as the latest addition to its Z-series lineup. The device was introduced on Thursday and is now available for purchase through the Vivo online store in the country. The phone comes in four colour options and multiple RAM and storage variants. The iQOO Z11 Turbo is offered in five configurations and colour options include Polar Night Black, Skylight White, Canglang Fuguang, and Halo Powder. Variant (RAM + Storage) wise expected prices are listed below: Add Zee News as a Preferred Source 12GB + 256GB CNY 2,699 at Rs 35,999 16GB + 256GB CNY 2,999 at Rs 39,000 12GB + 512GB CNY 3,199 at Rs 41,000 16GB + 512GB CNY 3,499 at Rs 45,000 16GB + 1TB CNY 3,999 at Rs 52,000 The smartphone features a 6.59-inch amoled display with 1.5K resolution and a 144Hz refresh rate. It supports HDR content and offers a high screen-to-body ratio of over 94 percent. The phone runs on Android 16-based OriginOS 6 and supports dual SIM functionality. iQOO has also confirmed IP68 and IP69 ratings, making the device resistant to dust and water.

The Beginner’s Guide to Computer Vision with Python
In this article, you will learn how to complete three beginner-friendly computer vision tasks in Python — edge detection, simple object detection, and image classification — using widely available libraries. Topics we will cover include: Installing and setting up the required Python libraries. Detecting edges and faces with classic OpenCV tools. Training a compact convolutional neural network for image classification. Let’s explore these techniques. The Beginner’s Guide to Computer Vision with PythonImage by Editor Introduction Computer vision is an area of artificial intelligence that gives computer systems the ability to analyze, interpret, and understand visual data, namely images and videos. It encompasses everything from classical tasks like image filtering, edge detection, and feature extraction, to more advanced tasks such as image and video classification and complex object detection, which require building machine learning and deep learning models. Thankfully, Python libraries like OpenCV and TensorFlow make it possible — even for beginners — to create and experiment with their own computer vision solutions using just a few lines of code. This article is designed to guide beginners interested in computer vision through the implementation of three fundamental computer vision tasks: Image processing for edge detection Simple object detection, like faces Image classification For each task, we provide a minimal working example in Python that uses freely available or built-in data, accompanied by the necessary explanations. You can reliably run this code in a notebook-friendly environment such as Google Colab, or locally in your own IDE. Setup and Preparation An important prerequisite for using the code provided in this article is to install several Python libraries. If you run the code in a notebook, paste this command into an initial cell (use the prefix “!” in notebooks): pip install opencv-python tensorflow scikit-image matplotlib numpy pip install opencv–python tensorflow scikit–image matplotlib numpy Image Processing With OpenCV OpenCV is a Python library that offers a range of tools for efficiently building computer vision applications—from basic image transformations to simple object detection tasks. It is characterized by its speed and broad range of functionalities. One of the primary task areas supported by OpenCV is image processing, which focuses on applying transformations to images, generally with two goals: improving their quality or extracting useful information. Examples include converting color images to grayscale, detecting edges, smoothing to reduce noise, and thresholding to separate specific regions (e.g. foreground from background). The first example in this guide uses a built-in sample image provided by the scikit-image library to detect edges in the grayscale version of an originally full-color image. from skimage import data import cv2 import matplotlib.pyplot as plt # Load a sample RGB image (astronaut) from scikit-image image = data.astronaut() # Convert RGB (scikit-image) to BGR (OpenCV convention), then to grayscale image = cv2.cvtColor(image, cv2.COLOR_RGB2BGR) gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) # Canny edge detection edges = cv2.Canny(gray, 100, 200) # Display plt.figure(figsize=(10, 4)) plt.subplot(1, 2, 1) plt.imshow(gray, cmap=”gray”) plt.title(“Grayscale Image”) plt.axis(“off”) plt.subplot(1, 2, 2) plt.imshow(edges, cmap=”gray”) plt.title(“Edge Detection”) plt.axis(“off”) plt.show() 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 from skimage import data import cv2 import matplotlib.pyplot as plt # Load a sample RGB image (astronaut) from scikit-image image = data.astronaut() # Convert RGB (scikit-image) to BGR (OpenCV convention), then to grayscale image = cv2.cvtColor(image, cv2.COLOR_RGB2BGR) gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) # Canny edge detection edges = cv2.Canny(gray, 100, 200) # Display plt.figure(figsize=(10, 4)) plt.subplot(1, 2, 1) plt.imshow(gray, cmap=“gray”) plt.title(“Grayscale Image”) plt.axis(“off”) plt.subplot(1, 2, 2) plt.imshow(edges, cmap=“gray”) plt.title(“Edge Detection”) plt.axis(“off”) plt.show() The process applied in the code above is simple, yet it illustrates a very common image processing scenario: Load and preprocess an image for analysis: convert the RGB image to OpenCV’s BGR convention and then to grayscale for further processing. Functions like COLOR_RGB2BGR and COLOR_BGR2GRAY make this straightforward. Use the built-in Canny edge detection algorithm to identify edges in the image. Plot the results: the grayscale image used for edge detection and the resulting edge map. The results are shown below: Edge detection with OpenCV Object Detection With OpenCV Time to go beyond classic pixel-level processing and identify higher-level objects within an image. OpenCV makes this possible with pre-trained models like Haar cascades, which can be applied to many real-world images and work well for simple detection use cases, e.g. detecting human faces. The code below uses the same astronaut image as in the previous section, converts it to grayscale, and applies a Haar cascade trained for identifying frontal faces. The cascade’s metadata is contained in haarcascade_frontalface_default.xml. from skimage import data import cv2 import matplotlib.pyplot as plt # Load the sample image and convert to BGR (OpenCV convention) image = data.astronaut() image = cv2.cvtColor(image, cv2.COLOR_RGB2BGR) # Haar cascade is an OpenCV classifier trained for detecting faces face_cascade = cv2.CascadeClassifier( cv2.data.haarcascades + “haarcascade_frontalface_default.xml” ) # The model requires grayscale images gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) # Detect faces faces = face_cascade.detectMultiScale( gray, scaleFactor=1.1, minNeighbors=5 ) # Draw bounding boxes output = image.copy() for (x, y, w, h) in faces: cv2.rectangle(output, (x, y), (x + w, y + h), (0, 255, 0), 2) # Display plt.imshow(cv2.cvtColor(output, cv2.COLOR_BGR2RGB)) plt.title(“Face Detection”) plt.axis(“off”) plt.show() 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 from skimage import data import cv2 import matplotlib.pyplot as plt # Load the sample image and convert to BGR (OpenCV convention) image = data.astronaut() image = cv2.cvtColor(image, cv2.COLOR_RGB2BGR) # Haar cascade is an OpenCV classifier trained for detecting faces face_cascade = cv2.CascadeClassifier( cv2.data.haarcascades + “haarcascade_frontalface_default.xml” ) # The model requires grayscale images gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) # Detect faces faces = face_cascade.detectMultiScale( gray, scaleFactor=1.1, minNeighbors=5 ) # Draw bounding boxes output = image.copy() for (x, y, w, h) in faces: cv2.rectangle(output, (x, y), (x +

Uncertainty in Machine Learning: Probability & Noise
Uncertainty in Machine Learning: Probability & NoiseImage by Author Editor’s note: This article is a part of our series on visualizing the foundations of machine learning. Welcome to the latest entry in our series on visualizing the foundations of machine learning. In this series, we will aim to break down important and often complex technical concepts into intuitive, visual guides to help you master the core principles of the field. This entry focuses on the uncertainty, probability, and noise in machine learning. Uncertainty in Machine Learning Uncertainty is an unavoidable part of machine learning, arising whenever models attempt to make predictions about the real world. At its core, uncertainty reflects a lack of complete knowledge about an outcome and is most often quantified using probability. Rather than being a flaw, uncertainty is something models must explicitly account for in order to produce reliable and trustworthy predictions. A useful way to think about uncertainty is through the lens of probability and the unknown. Much like flipping a fair coin, where the outcome is uncertain even though the probabilities are well defined, machine learning models frequently operate in environments where multiple outcomes are possible. As data flows through a model, predictions branch into different paths, influenced by randomness, incomplete information, and variability in the data itself. The goal of working with uncertainty is not to eliminate it, but to measure and manage it. This involves understanding several key components: Probability provides a mathematical framework for expressing how likely an event is to occur Noise represents irrelevant or random variation in data that obscures the true signal and can be either random or systematic Together, these factors shape the uncertainty present in a model’s predictions. Not all uncertainty is the same. Aleatoric uncertainty stems from inherent randomness in the data and cannot be reduced, even with more information. Epistemic uncertainty, on the other hand, arises from a lack of knowledge about the model or data-generating process and can often be reduced by collecting more data or improving the model. Distinguishing between these two types is essential for interpreting model behavior and deciding how to improve performance. To manage uncertainty, machine learning practitioners rely on several strategies. Probabilistic models output full probability distributions rather than single point estimates, making uncertainty explicit. Ensemble methods combine predictions from multiple models to reduce variance and better estimate uncertainty. Data cleaning and validation further improve reliability by reducing noise and correcting errors before training. Uncertainty is inherent in real-world data and machine learning systems. By recognizing its sources and incorporating it directly into modeling and decision-making, practitioners can build models that are not only more accurate, but also more robust, transparent, and trustworthy. The visualizer below provides a concise summary of this information for quick reference. You can find a PDF of the infographic in high resolution here. Uncertainty, Probability & Noise: Visualizing the Foundations of Machine Learning (click to enlarge)Image by Author Machine Learning Mastery Resources These are some selected resources for learning more about probability and noise: A Gentle Introduction to Uncertainty in Machine Learning – This article explains what uncertainty means in machine learning, explores the main causes such as noise in data, incomplete coverage, and imperfect models, and describes how probability provides the tools to quantify and manage that uncertainty.Key takeaway: Probability is essential for understanding and managing uncertainty in predictive modeling. Probability for Machine Learning (7-Day Mini-Course) – This structured crash course guides readers through the key probability concepts needed in machine learning, from basic probability types and distributions to Naive Bayes and entropy, with practical lessons designed to build confidence applying these ideas in Python.Key takeaway: Building a solid foundation in probability enhances your ability to apply and interpret machine learning models. Understanding Probability Distributions for Machine Learning with Python – This tutorial introduces important probability distributions used in machine learning, shows how they apply to tasks like modeling residuals and classification, and provides Python examples to help practitioners understand and use them effectively.Key takeaway: Mastering probability distributions helps you model uncertainty and choose appropriate statistical tools throughout the machine learning workflow. Be on the lookout for for additional entries in our series on visualizing the foundations of machine learning. About Matthew Mayo Matthew Mayo (@mattmayo13) holds a master’s degree in computer science and a graduate diploma in data mining. As managing editor of KDnuggets & Statology, and contributing editor at Machine Learning Mastery, Matthew aims to make complex data science concepts accessible. His professional interests include natural language processing, language models, machine learning algorithms, and exploring emerging AI. He is driven by a mission to democratize knowledge in the data science community. Matthew has been coding since he was 6 years old.

No More Use Of ChatGPT On WhatsApp: Meta’s New Rules End Access For 50M Users – Check How To Save Your Chat History | Technology News
OpenAI’s popular AI chatbot, ChatGPT, can no longer be used on WhatsApp starting today, January 15, 2026. This change comes after Meta, WhatsApp’s parent company, updated its business API policies to restrict general-purpose AI chatbots like ChatGPT. Over 50 million users who enjoyed chatting, creating, and learning via WhatsApp now won’t be able to use ChatGPT on WhatsApp. In October 2025, Meta introduced new rules to limit AI companies from using WhatsApp as a main hub for broad AI assistants. The policy blocks services that run open-ended conversations or share user data for AI training. OpenAI confirmed the end of support, saying they preferred to stay but must follow the terms. This affects text chats and calls to the number +1 (800) 242-8478. Users in India and worldwide will experience this OpenAI update, as WhatsApp has billions of active users. Many relied on ChatGPT for quick answers, image generation, and web searches right in their chats. Add Zee News as a Preferred Source

BGMI 4.2 Update Release Date & Time: Primewood Genesis Theme, Royal Enfield Bikes, New Modes, Abilities, And More – Check How To Download | Technology News
BGMI 4.2 Update: Krafton India is set to release the BGMI 4.2 update on January 15, 2026. The update will be rolled out in phases to avoid server overload. Android and iOS users will receive the update on the same day, but at different time windows. For Android users, the update will begin appearing on the Google Play Store from 6:30 AM IST, with wider availability expected by 11:30 AM to 12:30 PM. iOS users can expect the update between 8:30 AM and 9:30 AM IST, with the rollout completing by 12:30 PM. The update size is expected to be between 0.9GB and 1.5GB. The new update introduces a new Primewood Genesis theme and, in collaboration with Royal Enfield, players will be able to ride the Bullet 350 and Continental GT 650 in the battlegrounds. The new Primewood Genesis theme features nature-inspired environments resembling magical forests. Players will encounter special plants, high-loot zones, and interactive elements such as the Tree of Life, which can be used as cover. Some plants provide weapons and supplies, while poisonous flowers pose a threat during combat. Add Zee News as a Preferred Source



