In this article, you will learn how to identify, understand, and mitigate race conditions in multi-agent orchestration systems.
Topics we will cover include:
- What race conditions look like in multi-agent environments
- Architectural patterns for preventing shared-state conflicts
- Practical strategies like idempotency, locking, and concurrency testing
Let’s get straight to it.
Handling Race Conditions in Multi-Agent Orchestration
Image by Editor
If you’ve ever watched two agents confidently write to the same resource at the same time and produce something that makes zero sense, you already know what a race condition feels like in practice. It’s one of those bugs that doesn’t show up in unit tests, behaves perfectly in staging, and then detonates in production during your highest-traffic window.
In multi-agent systems, where parallel execution is the whole point, race conditions aren’t edge cases. They’re expected guests. Understanding how to handle them is less about being defensive and more about building systems that assume chaos by default.
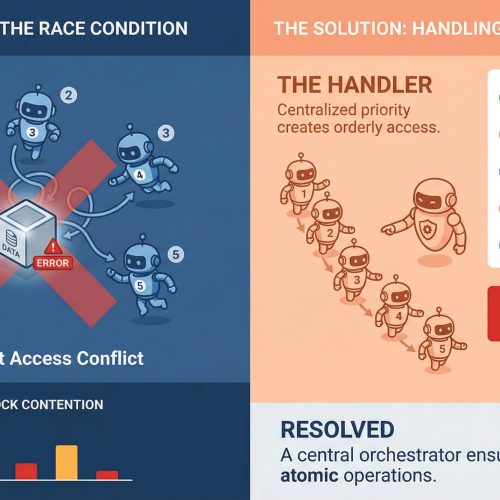
What Race Conditions Actually Look Like in Multi-Agent Systems
A race condition happens when two or more agents try to read, modify, or write shared state at the same time, and the final result depends on which one gets there first. In a single-agent pipeline, that’s manageable. In a system with five agents running concurrently, it’s a genuinely different problem.
The tricky part is that race conditions aren’t always obvious crashes. Sometimes they’re silent. Agent A reads a document, Agent B updates it half a second later, and Agent A writes back a stale version with no error thrown anywhere. The system looks fine. The data is compromised.
What makes this worse in machine learning pipelines specifically is that agents often work on mutable shared objects, whether that’s a shared memory store, a vector database, a tool output cache, or a simple task queue. Any of these can become a contention point when multiple agents start pulling from them simultaneously.
Why Multi-Agent Pipelines Are Especially Vulnerable
Traditional concurrent programming has decades of tooling around race conditions: threads, mutexes, semaphores, and atomic operations. Multi-agent large language model (LLM) systems are newer, and they are often built on top of async frameworks, message brokers, and orchestration layers that don’t always give you fine-grained control over execution order.
There’s also the problem of non-determinism. LLM agents don’t always take the same amount of time to complete a task. One agent might finish in 200ms, while another takes 2 seconds, and the orchestrator has to handle that gracefully. When it doesn’t, agents start stepping on each other, and you end up with a corrupted state or conflicting writes that the system silently accepts.
Agent communication patterns matter a lot here, too. If agents are sharing state through a central object or a shared database row rather than passing messages, they are almost guaranteed to run into write conflicts at scale. This is as much a design pattern issue as it is a concurrency issue, and fixing it usually starts at the architecture level before you even touch the code.
Locking, Queuing, and Event-Driven Design
The most direct way to handle shared resource contention is through locking. Optimistic locking works well when conflicts are rare: each agent reads a version tag alongside the data, and if the version has changed by the time it tries to write, the write fails and retries. Pessimistic locking is more aggressive and reserves the resource before reading. Both approaches have trade-offs, and which one fits depends on how often your agents are actually colliding.
Queuing is another solid approach, especially for task assignment. Instead of multiple agents polling a shared task list directly, you push tasks into a queue and let agents consume them one at a time. Systems like Redis Streams, RabbitMQ, or even a basic Postgres advisory lock can handle this well. The queue becomes your serialization point, which takes the race out of the equation for that particular access pattern.
Event-driven architectures go further. Rather than agents reading from shared state, they react to events. Agent A completes its work and emits an event. Agent B listens for that event and picks up from there. This creates looser coupling and naturally reduces the overlap window where two agents might be modifying the same thing at once.
Idempotency Is Your Best Friend
Even with solid locking and queuing in place, things still go wrong. Networks hiccup, timeouts happen, and agents retry failed operations. If those retries are not idempotent, you will end up with duplicate writes, double-processed tasks, or compounding errors that are painful to debug after the fact.
Idempotency means that running the same operation multiple times produces the same result as running it once. For agents, that often means including a unique operation ID with every write. If the operation has already been applied, the system recognizes the ID and skips the duplicate. It’s a small design choice with a significant impact on reliability.
It’s worth building idempotency in from the start at the agent level. Retrofitting it later is painful. Agents that write to databases, update records, or trigger downstream workflows should all carry some form of deduplication logic, because it makes the whole system more resilient to the messiness of real-world execution.
Testing for Race Conditions Before They Test You
The hard part about race conditions is reproducing them. They are timing-dependent, which means they often only appear under load or in specific execution sequences that are difficult to reproduce in a controlled test environment.
One useful approach is stress testing with intentional concurrency. Spin up multiple agents against a shared resource simultaneously and observe what breaks. Tools like Locust, pytest-asyncio with concurrent tasks, or even a simple ThreadPoolExecutor can help simulate the kind of overlapping execution that exposes contention bugs in staging rather than production.
Property-based testing is underused in this context. If you can define invariants that should always hold regardless of execution order, you can run randomized tests that attempt to violate them. It won’t catch everything, but it will surface many of the subtle consistency issues that deterministic tests miss entirely.
A Concrete Race Condition Example
It helps to make this concrete. Consider a simple shared counter that multiple agents update. This could represent something real, like tracking how many times a document has been processed or how many tasks have been completed.
Here’s a minimal version of the problem in pseudocode:
|
# Shared state counter = 0
# Agent task def increment_counter(): global counter value = counter # Step 1: read value = value + 1 # Step 2: modify counter = value # Step 3: write |
Now imagine two agents running this at the same time:
- Agent A reads
counter = 0 - Agent B reads
counter = 0 - Agent A writes
counter = 1 - Agent B writes
counter = 1
You expected the final value to be 2. Instead, it is 1. No errors, no warnings—just silently incorrect state. That’s a race condition in its simplest form.
There are a few ways to mitigate this, depending on your system design.
Option 1: Locking the Critical Section
The most direct fix is to ensure that only one agent can modify the shared resource at a time, shown here in pseudocode:
|
lock.acquire()
value = counter value = value + 1 counter = value
lock.release() |
This guarantees correctness, but it comes at the cost of reduced parallelism. If many agents are competing for the same lock, throughput can drop quickly.
Option 2: Atomic Operations
If your infrastructure supports it, atomic updates are a cleaner solution. Instead of breaking the operation into read-modify-write steps, you delegate it to the underlying system:
|
counter = atomic_increment(counter) |
Databases, key-value stores, and some in-memory systems provide this out of the box. It removes the race entirely by making the update indivisible.
Option 3: Idempotent Writes with Versioning
Another approach is to detect and reject conflicting updates using versioning:
|
# Read with version value, version = read_counter()
# Attempt write success = write_counter(value + 1, expected_version=version)
if not success: retry() |
This is optimistic locking in practice. If another agent updates the counter first, your write fails and retries with fresh state.
In real multi-agent systems, the “counter” is rarely this simple. It might be a document, a memory store, or a workflow state object. But the pattern is the same: any time you split a read and a write across multiple steps, you introduce a window where another agent can interfere.
Closing that window through locks, atomic operations, or conflict detection is the core of handling race conditions in practice.
Final Thoughts
Race conditions in multi-agent systems are manageable, but they demand intentional design. The systems that handle them well are not the ones that got lucky with timing; they are the ones that assumed concurrency would cause problems and planned accordingly.
Idempotent operations, event-driven communication, smart locking, and proper queue management are not over-engineering. They are the baseline for any pipeline where agents are expected to work in parallel without stepping on each other. Get those fundamentals right, and the rest becomes far more predictable.