In this article, you will learn how to systematically select and apply agentic AI design patterns to build reliable, scalable agent systems.
Topics we will cover include:
- Why design patterns are essential for predictable agent behavior
- Core agentic patterns such as ReAct, Reflection, Planning, and Tool Use
- How to evaluate, scale, and safely deploy agentic systems in production
Let’s get started.
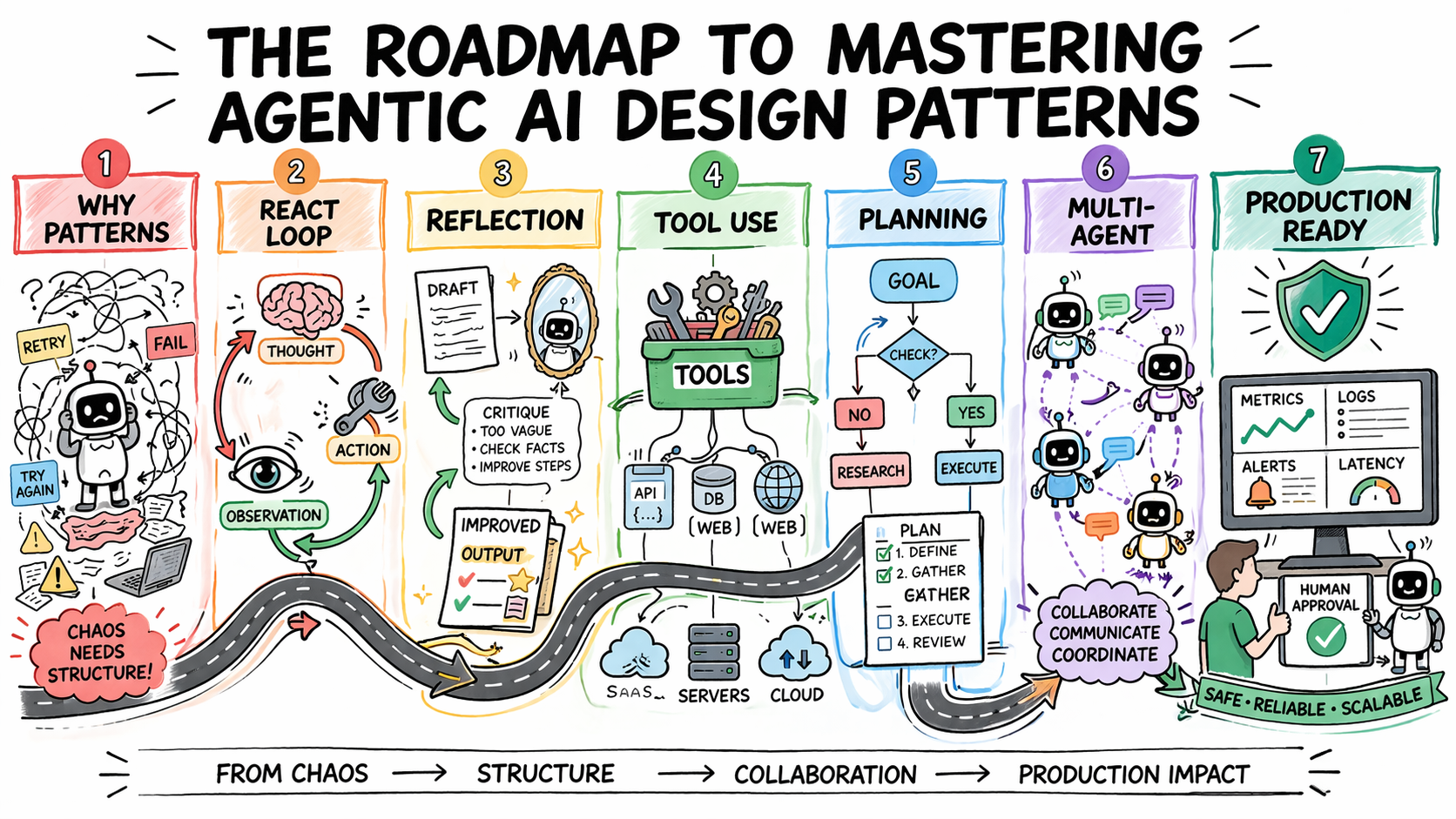
The Roadmap to Mastering Agentic AI Design Patterns
Image by Author
Introduction
Most agentic AI systems are built pattern by pattern, decision by decision, without any governing framework for how the agent should reason, act, recover from errors, or hand off work to other agents. Without structure, agent behavior is hard to predict, harder to debug, and nearly impossible to improve systematically. The problem compounds in multi-step workflows, where a bad decision early in a run affects every step that follows.
Agentic design patterns are reusable approaches for recurring problems in agentic system design. They help establish how an agent reasons before acting, how it evaluates its own outputs, how it selects and calls tools, how multiple agents divide responsibility, and when a human needs to be in the loop. Choosing the right pattern for a given task is what makes agent behavior predictable, debuggable, and composable as requirements grow.
This article offers a practical roadmap to understanding agentic AI design patterns. It explains why pattern selection is an architectural decision and then works through the core agentic design patterns used in production today. For each, it covers when the pattern fits, what trade-offs it carries, and how patterns layer together in real systems.
Step 1: Understanding Why Design Patterns Are Necessary
Before you study any specific pattern, you need to reframe what you’re actually trying to solve. The instinct for many developers is to treat agent failures as prompting failures. If the agent did the wrong thing, the fix is a better system prompt. Sometimes that is true. But more often, the failure is architectural.
An agent that loops endlessly is failing because no explicit stopping condition was designed into the loop. An agent that calls tools incorrectly does not have a clear contract for when to invoke which tool. An agent that produces inconsistent outputs given identical inputs is operating without a structured decision framework.
Design patterns exist to solve exactly these problems. They are repeatable architectural templates that define how an agent’s loop should behave: how it decides what to do next, when to stop, how to recover from errors, and how to interact reliably with external systems. Without them, agent behavior becomes almost impossible to debug or scale.
There is also a pattern-selection problem that trips up teams early. The temptation is to reach for the most capable, most sophisticated pattern available — multi-agent systems, complex orchestration, dynamic planning. But the cost of premature complexity in agentic systems is steep. More model calls mean higher latency and token costs. More agents mean more failure surfaces. More orchestration means more coordination bugs. The expensive mistake is jumping to complex patterns before you have hit clear limitations with simpler ones.
The practical implication:
- Treat pattern selection the way you would treat any production architecture decision.
- Start with the problem, not the pattern.
- Define what the agent needs to do, what can go wrong, and what “working correctly” looks like.
- Then pick the simplest pattern that handles those requirements.
Further learning: AI agent design patterns | Google Cloud and Agentic AI Design Patterns Introduction and walkthrough | Amazon Web Services.
Step 2: Learning the ReAct Pattern as Your Default Starting Point
ReAct — Reasoning and Acting — is the most foundational agentic design pattern and the right default for most complex, unpredictable tasks. It combines chain-of-thought reasoning with external tool use in a continuous feedback loop.
The structure alternates between three phases:
- Thought: the agent reasons about what to do next
- Action: the agent invokes a tool, calls an API, or runs code
- Observation: the agent processes the result and updates its plan
This repeats until the task is complete or a stopping condition is reached.
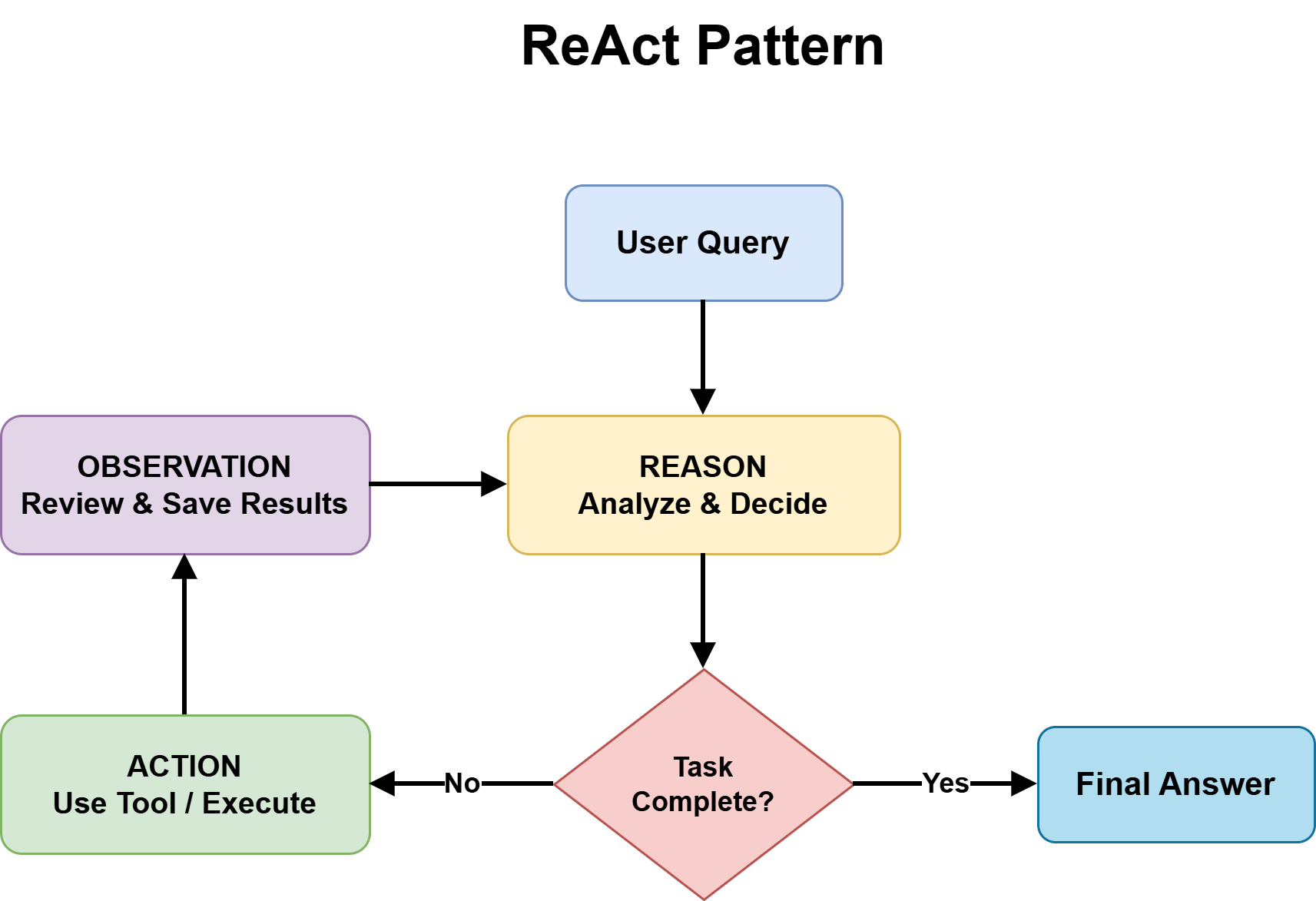
ReAct Pattern
Image by Author
What makes the pattern effective is that it externalizes reasoning. Every decision is visible, so when the agent fails, you can see exactly where the logic broke down rather than debugging a black-box output. It also prevents premature conclusions by grounding each reasoning step in an observable result before proceeding, which reduces hallucination when models jump to answers without real-world feedback.
The trade-offs are real. Each loop iteration requires an additional model call, increasing latency and cost. Incorrect tool output propagates into subsequent reasoning steps. Non-deterministic model behavior means identical inputs can produce different reasoning paths, which creates consistency problems in regulated environments. Without an explicit iteration cap, the loop can run indefinitely and costs can compound quickly.
Use ReAct when the solution path is not predetermined: adaptive problem-solving, multi-source research, and customer support workflows with variable complexity. Avoid it when speed is the priority or when inputs are well-defined enough that a fixed workflow would be faster and cheaper.
Further reading: ReAct: Synergizing Reasoning and Acting in Language Models and What Is a ReAct Agent? | IBM
Step 3: Adding Reflection to Improve Output Quality
Reflection gives an agent the ability to evaluate and revise its own outputs before they reach the user. The structure is a generation-critique-refinement cycle: the agent produces an initial output, assesses it against defined quality criteria, and uses that assessment as the basis for revision. The cycle runs for a set number of iterations or until the output meets a defined threshold.
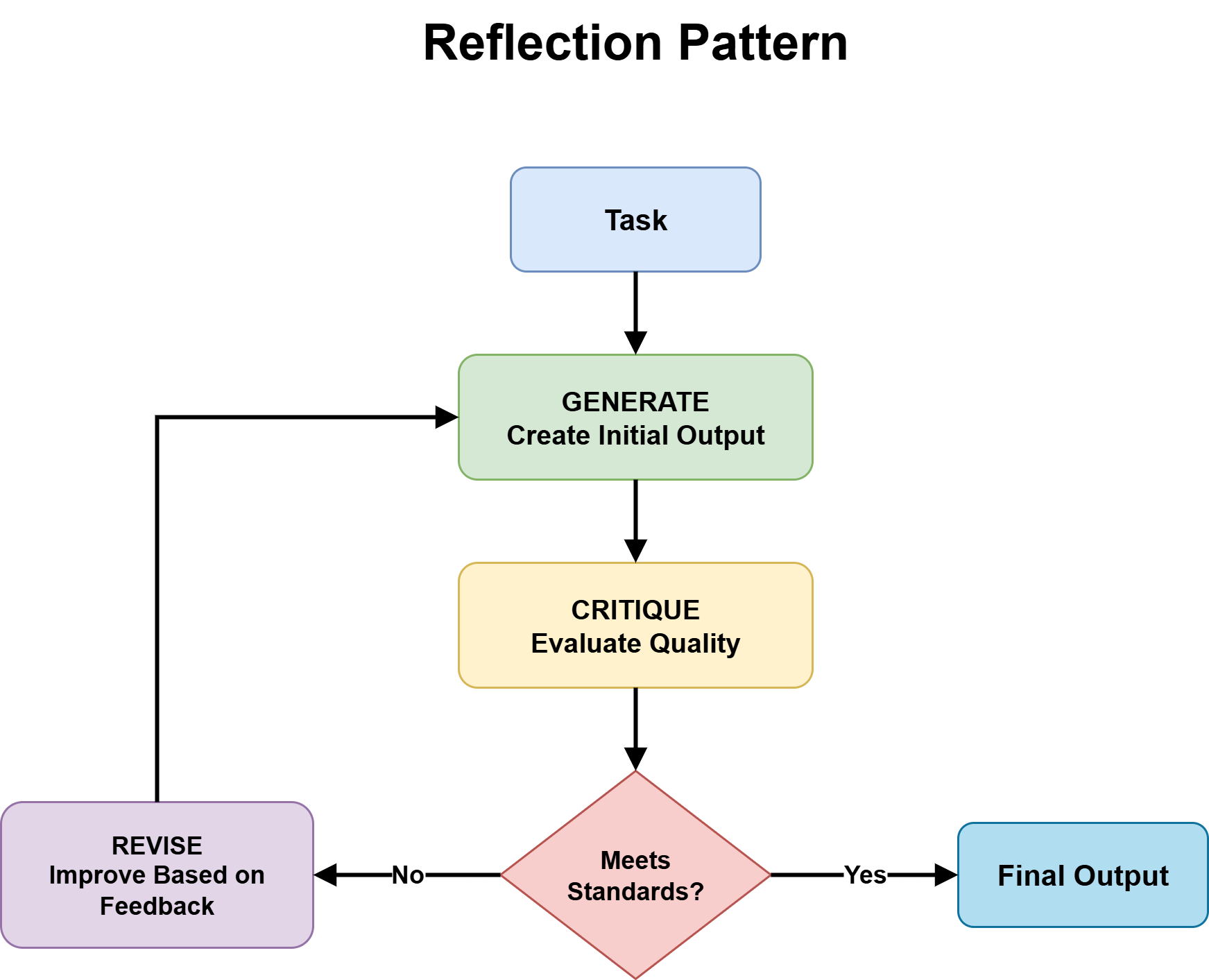
Reflection Pattern
Image by Author
The pattern is particularly effective when critique is specialized. An agent reviewing code can focus on bugs, edge cases, or security issues. One reviewing a contract can check for missing clauses or logical inconsistencies. Connecting the critique step to external verification tools — a linter, a compiler, or a schema validator — compounds the gains further, because the agent receives deterministic feedback rather than relying solely on its own judgment.
However, a few design decisions matter. The critic should be independent from the generator — at minimum, a separate system prompt with different instructions; in high-stakes applications, a different model entirely. This prevents the critic from inheriting the same blind spots as the generator and producing shallow self-agreement rather than genuine evaluation. Explicit iteration bounds are also non-negotiable. Without a maximum loop count, an agent that keeps finding marginal improvements will stall rather than converge.
Reflection is the right pattern when output quality matters more than speed and when tasks have clear enough correctness criteria to evaluate systematically. It adds cost and latency that are not worth paying for simple factual queries or applications with strict real-time constraints.
Further reading: Agentic Design Patterns: Reflection and Reflection Agents | LangChain blog.
Step 4: Making Tool Use a First-Class Architectural Decision
Tool use is the pattern that turns an agent from a knowledge system into an action system. Without it, an agent has no current information, no access to external systems, and no ability to trigger actions in the real world. With it, an agent can call APIs, query databases, execute code, retrieve documents, and interact with software platforms. For almost every production agent handling real-world tasks, tool use is the foundation everything else builds upon.
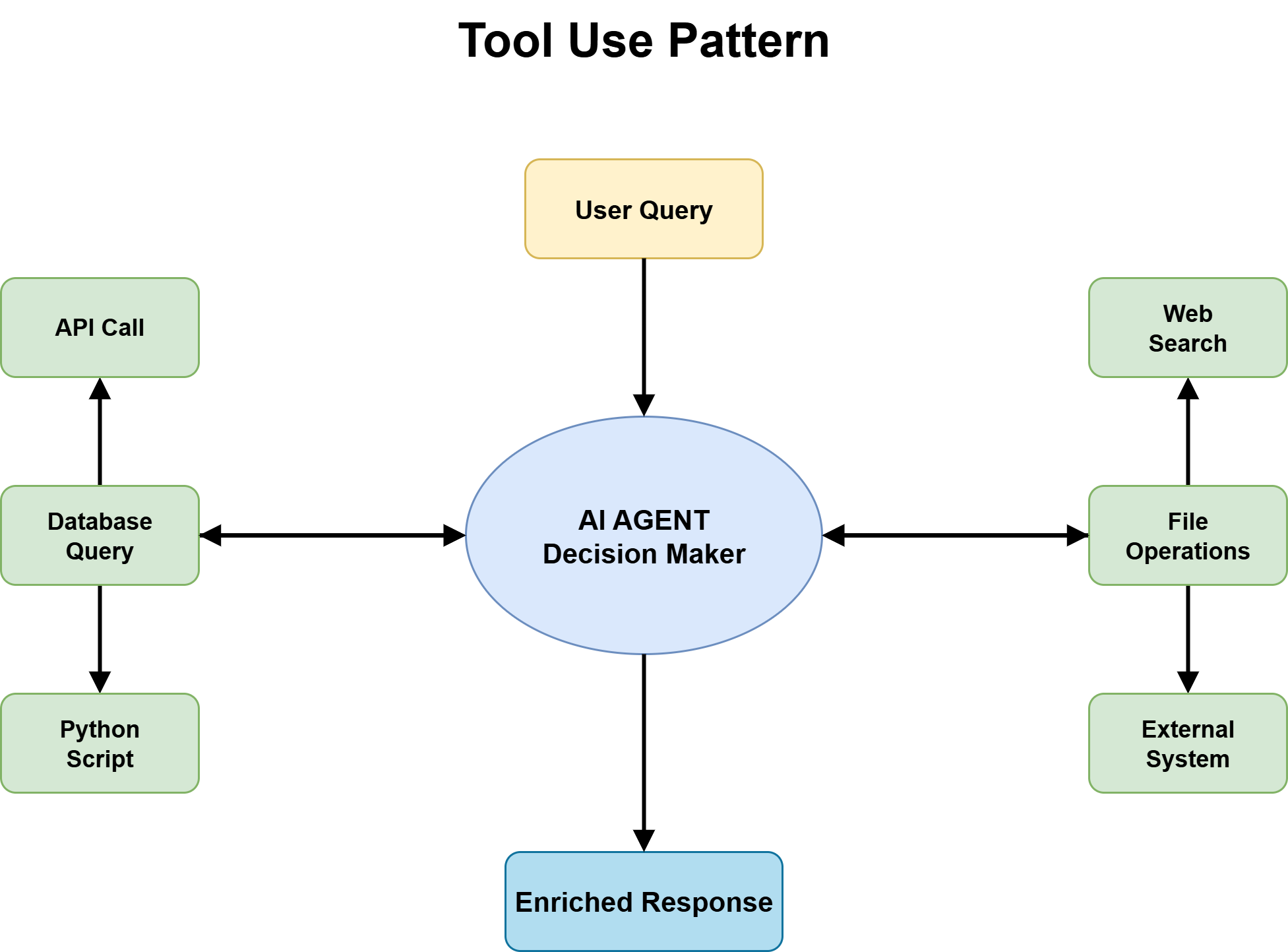
Tool Use Pattern
Image by Author
The most important architectural decision is defining a fixed tool catalog with strict input and output schemas. Without clear schemas, the agent guesses how to call tools, and those guesses fail under edge cases. Tool descriptions need to be precise enough for the agent to reason correctly about which tool applies to a given situation. Too vague and you get mismatched calls; too narrow and the agent misses valid use cases.
The second critical decision is handling tool failures. An agent that inherits its tools’ reliability problems without any failure-handling logic is fragile in proportion to the instability of its external dependencies. APIs rate-limit, time out, return unexpected formats, and change behavior after updates. Your agent’s tool layer needs explicit error handling, retry logic, and graceful degradation paths for when tools are unavailable.
Tool selection accuracy is a subtler but equally important concern. As tool libraries grow, agents must reason over larger catalogs to find the right tool for each task. Performance on tool selection tends to degrade as catalog size increases. A useful design principle is to structure tool interfaces so that distinctions between tools are clear and unambiguous.
Finally, tool use carries a security surface that agent developers often underestimate. Once an agent can interact with real systems — submitting forms, updating records, triggering transactions — the blast radius of errors grows significantly. Sandboxed execution environments and human approval gates are essential for high-risk tool invocations.
Further reading: Tool Use Design Pattern and Mastering LLM Tool Calling: The Complete Framework for Connecting Models to the Real World
Step 5: Knowing When to Plan Before Acting
Planning is the pattern for tasks where complexity or coordination requirements are high enough that ad-hoc reasoning through a ReAct loop is not sufficient. Where ReAct improvises step by step, planning breaks the goal into ordered subtasks with explicit dependencies before execution begins.
There are two broad implementations:
- Plan-and-Execute: an LLM generates a complete task plan, then a separate execution layer works through the steps.
- Adaptive Planning: the agent generates a partial plan, executes it, and re-evaluates before generating the next steps.
Planning pays off on tasks with real coordination requirements: multi-system integrations that must happen in a specific sequence, research tasks synthesizing across multiple sources, and development workflows spanning design, implementation, and testing. The main benefit is surfacing hidden complexity before execution starts, which prevents costly mid-run failures.
The trade-offs are straightforward. Planning requires an additional model call upfront, which is not worth it for simple tasks. It also assumes the task structure is knowable in advance, which is not always the case.
Use planning when the task structure is articulable upfront and coordination between steps is complex enough to benefit from explicit sequencing. Default to ReAct when it is not.
Further reading: Agentic Design Patterns: Planning
Step 6: Designing for Multi-Agent Collaboration
Multi-agent systems distribute work across specialized agents, each with focused expertise, a specific tool set, and a clearly defined role. A coordinator manages routing and synthesis; specialists handle what they are optimized for.
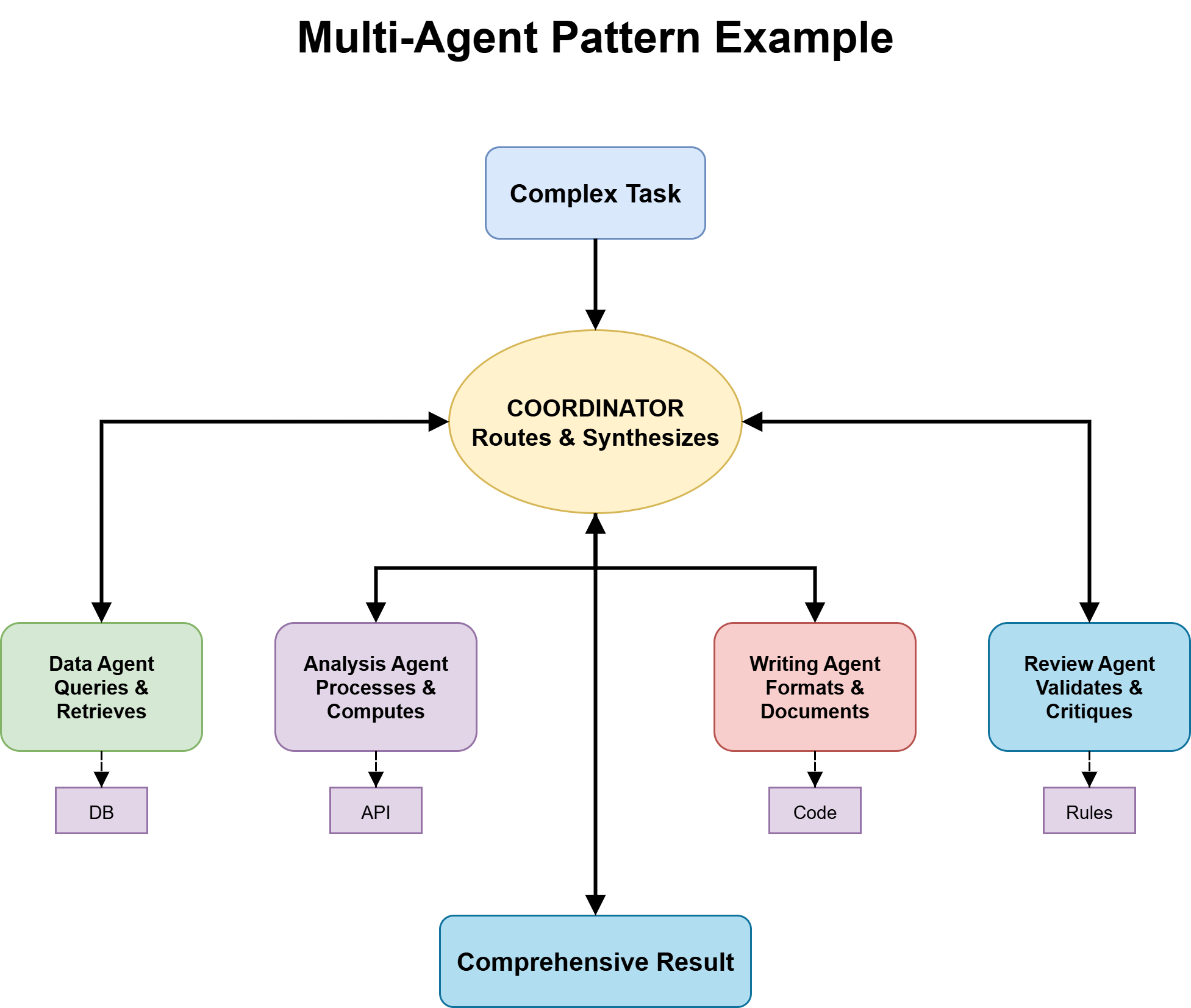
Multi-Agent System
Image by Author
The benefits are real — better output quality, independent improvability of each agent, and more scalable architecture — but so is the coordination complexity. Getting this right requires answering key questions early.
Ownership — which agent has write authority over shared state — must be defined explicitly. Routing logic determines whether the coordinator uses an LLM or deterministic rules. Most production systems use a hybrid approach. Orchestration topology shapes how agents interact:
- Sequential — Agent A → B → C
- Concurrent — parallel execution with merging logic
- Debate — agents critique each other’s outputs
Start with a single capable agent using ReAct and appropriate tools. Move to multi-agent architecture only when a clear bottleneck emerges.
Further reading: Agent Factory: The New Era of Agentic AI – Microsoft Azure and What is a Multi-Agent System? | IBM
Step 7: Evaluating Your Pattern Choices and Designing for Production Safety
Pattern selection is only half the work. Making those patterns reliable in production requires deliberate evaluation, explicit safety design, and ongoing monitoring.
Define pattern-specific evaluation criteria.
- For ReAct agents: are tool calls aligned with reasoning?
- For Reflection: are outputs improving or stagnating?
- For multi-agent systems: is routing accurate and output coherent?
Build failure mode tests early. Probe tool misuse, infinite loops, routing failures, and degraded performance under long context. Treat observability as a requirement. Step-level traces are essential for debugging.
Design guardrails based on risk. Use validation, rate limiting, and approval gates where needed. The OWASP Top 10 for LLM Applications is a useful reference.
Plan for human-in-the-loop workflows. Treat human oversight as a design pattern, not a fallback.
Leverage existing agent orchestration frameworks like LangGraph, AutoGen, CrewAI, and Guardrails AI.
Further reading: Evaluating AI Agents | DeepLearning.AI
Conclusion
Agentic AI design patterns are not a checklist to complete once. They are architectural tools that evolve alongside your system.
Start with the simplest pattern that works, add complexity only when necessary, and invest heavily in observability and evaluation. This approach leads to systems that are not only functional, but reliable and scalable.