In this article, you will learn about five major challenges teams face when scaling agentic AI systems from prototype to production in 2026.
Topics we will cover include:
- Why orchestration complexity grows rapidly in multi-agent systems.
- How observability, evaluation, and cost control remain difficult in production environments.
- Why governance and safety guardrails are becoming essential as agentic systems take real-world actions.
Let’s not waste any more time.
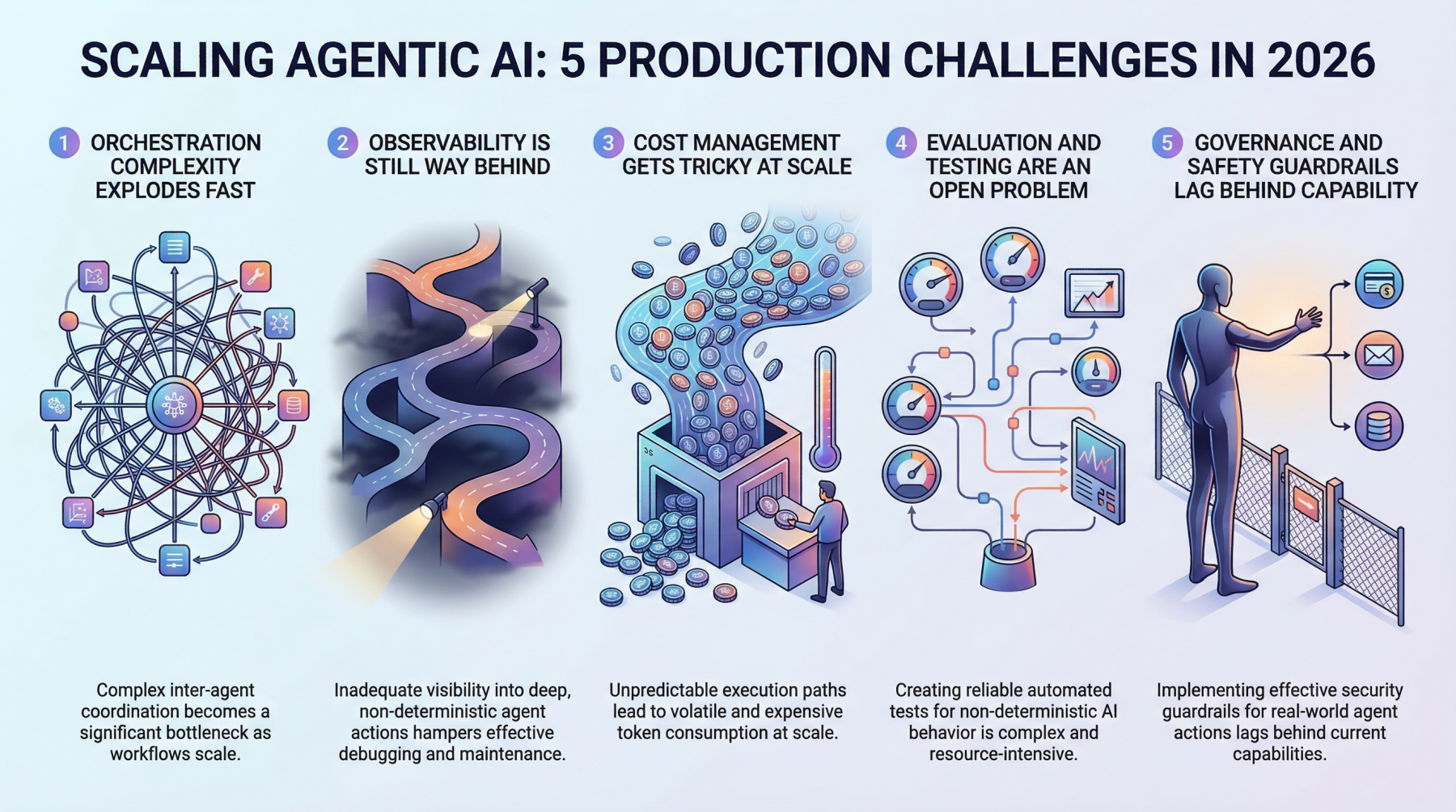
5 Production Scaling Challenges for Agentic AI in 2026
Image by Editor
Introduction
Everyone’s building agentic AI systems right now, for better or for worse. The demos look incredible, the prototypes feel magical, and the pitch decks practically write themselves.
But here’s what nobody’s tweeting about: getting these things to actually work at scale, in production, with real users and real stakes, is a completely different game. The gap between a slick demo and a reliable production system has always existed in machine learning, but agentic AI stretches it wider than anything we’ve seen before.
These systems make decisions, take actions, and chain together complex workflows autonomously. That’s powerful, and it’s also terrifying when things go sideways at scale. So let’s talk about the five biggest headaches teams are running into as they try to scale agentic AI in 2026.
1. Orchestration Complexity Explodes Fast
When you’ve got a single agent handling a narrow task, orchestration feels manageable. You define a workflow, set some guardrails, and things mostly behave. But production systems rarely stay that simple. The moment you introduce multi-agent architectures in which agents delegate to other agents, retry failed steps, or dynamically choose which tools to call, you’re dealing with orchestration complexity that grows almost exponentially.
Teams are finding that the coordination overhead between agents becomes the bottleneck, not the individual model calls. You’ve got agents waiting on other agents, race conditions popping up in async pipelines, and cascading failures that are genuinely hard to reproduce in staging environments. Traditional workflow engines weren’t designed for this level of dynamic decision-making, and most teams end up building custom orchestration layers that quickly become the hardest part of the entire stack to maintain.
The real kicker is that these systems behave differently under load. An orchestration pattern that works beautifully at 100 requests per minute can completely fall apart at 10,000. Debugging that gap requires a kind of systems thinking that most machine learning teams are still developing.
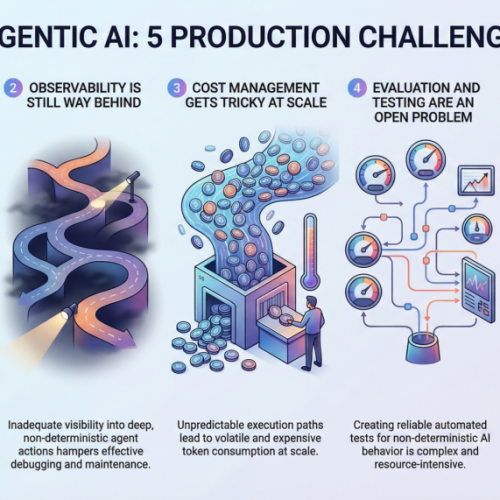
2. Observability Is Still Way Behind
You can’t fix what you can’t see, and right now, most teams can’t see nearly enough of what their agentic systems are doing in production. Traditional machine learning monitoring tracks things like latency, throughput, and model accuracy. Those metrics still matter, but they barely scratch the surface of agentic workflows.
When an agent takes a 12-step journey to answer a user query, you need to understand every decision point along the way. Why did it choose Tool A over Tool B? Why did it retry step 4 three times? Why did the final output completely miss the mark, despite every intermediate step looking fine? The tracing infrastructure for this kind of deep observability is still immature. Most teams cobble together some combination of LangSmith, custom logging, and a lot of hope.
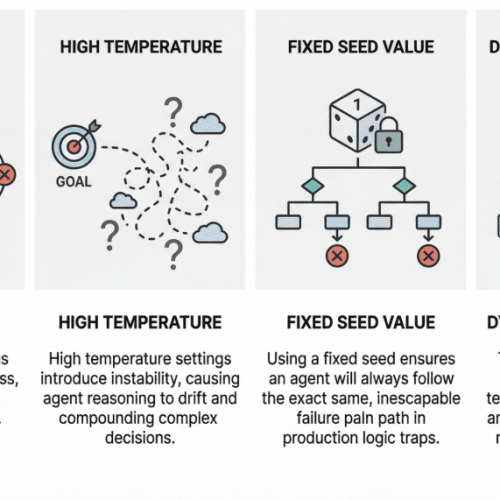
What makes it harder is that agentic behavior is non-deterministic by nature. The same input can produce wildly different execution paths, which means you can’t just snapshot a failure and replay it reliably. Building robust observability for systems that are inherently unpredictable remains one of the biggest unsolved problems in the space.
3. Cost Management Gets Tricky at Scale
Here’s something that catches a lot of teams off guard: agentic systems are expensive to run. Each agent action typically involves one or more LLM calls, and when agents are chaining together dozens of steps per request, the token costs add up shockingly fast. A workflow that costs $0.15 per execution sounds fine until you’re processing 500,000 requests a day.
Smart teams are getting creative with cost optimization. They’re routing simpler sub-tasks to smaller, cheaper models while reserving the heavy hitters for complex reasoning steps. They’re caching intermediate results aggressively and building kill switches that terminate runaway agent loops before they burn through budget. But there’s a constant tension between cost efficiency and output quality, and finding the right balance requires ongoing experimentation.
The billing unpredictability is what really stresses out engineering leads. Unlike traditional APIs, where you can estimate costs pretty accurately, agentic systems have variable execution paths that make cost forecasting genuinely difficult. One edge case can trigger a chain of retries that costs 50 times more than the normal path.
4. Evaluation and Testing Are an Open Problem
How do you test a system that can take a different path every time it runs? That’s the question keeping machine learning engineers up at night. Traditional software testing assumes deterministic behavior, and traditional machine learning evaluation assumes a fixed input-output mapping. Agentic AI breaks both assumptions simultaneously.
Teams are experimenting with a range of approaches. Some are building LLM-as-a-judge pipelines in which a separate model evaluates the agent’s outputs. Others are creating scenario-based test suites that check for behavioral properties rather than exact outputs. A few are investing in simulation environments where agents can be stress-tested against thousands of synthetic scenarios before hitting production.
But none of these approaches feels truly mature yet. The evaluation tooling is fragmented, benchmarks are inconsistent, and there’s no industry consensus on what “good” even looks like for a complex agentic workflow. Most teams end up relying heavily on human review, which obviously doesn’t scale.
5. Governance and Safety Guardrails Lag Behind Capability
Agentic AI systems can take real actions in the real world. They can send emails, modify databases, execute transactions, and interact with external services. The safety implications of that autonomy are significant, and governance frameworks haven’t kept pace with how quickly these capabilities are being deployed.
The challenge is implementing guardrails that are robust enough to prevent harmful actions without being so restrictive that they kill the usefulness of the agent. It’s a delicate balance, and most teams are learning through trial and error. Permission systems, action approval workflows, and scope limitations all add friction that can undermine the whole point of having an autonomous agent in the first place.
Regulatory pressure is mounting too. As agentic systems start making decisions that affect customers directly, questions about accountability, auditability, and compliance become urgent. Teams that aren’t thinking about governance now are going to hit painful walls when regulations catch up.
Final Thoughts
Agentic AI is genuinely transformative, but the path from prototype to production at scale is littered with challenges that the industry is still figuring out in real time.
The good news is that the ecosystem is maturing quickly. Better tooling, clearer patterns, and hard-won lessons from early adopters are making the path a little smoother every month.
If you’re scaling agentic systems right now, just know that the pain you’re feeling is universal. The teams that invest in solving these foundational problems early are the ones that will build systems that actually hold up when it matters.